
Carto-SI, une solution pour cartographier son Système d'Information, tout simplement
Carto-SI est une solution qui permet de cartographier les différentes couches du Système d’Information, de définir leurs dépendances, puis de réaliser des études d’impacts. C’est une solution 100 % française, développée par des architectes d’entreprise expérimentés et déjà utilisée par plusieurs grands comptes.

Carto-SI : menu général (à gauche) et Etude d'impact (à droite)
Un mix pragmatique entre CIGREF (strates) et Urba-SI (POS)
Carto-SI va vous permettre de cartographier votre Système d'information en 4 couches principales :
Métier, Applicative, Infrastructure, Données.
Traditionnellement pour une analyse top-down, la couche Métier est haut, tandis que la couche Infrastructure est en bas, avec la couche Applicative entre ces deux couches.
Pas de strate Fonctionnel (parfois difficile à établir et à distinguer de la strate Métier, sauf dans la cadre d’une architecture micro-services) comme le modèle du Cigref. Mais il y a une Vue fonctionnelle dans la couche Métier. Il n’y a pas de métamodèle de ce mix pragmatique.
Cette légère simplification est basée sur l’expérience des concepteurs de cette solution. Elle est compensée par la notion d’Objet Applicatif, qui permet de préciser les échanges de données entre les applications (un bon de commande, par exemple).
Couche Métier : Sans surprise, les Domaines Métiers correspondront bien sûr à ceux de l’entreprise : Logistique et Chaine d’Approvisionnement, Finance et Comptabilité, Ressources Humaines, etc. Chaque domaine métier sera représenté par une couleur différente. Une Activité pourra être décomposée en une ou plusieurs Tâches.
Couche Applicative : Cette couche illustre des Applications utilisées par l'Entreprise et leurs interactions. L’Étude de flux n’apporte pour le moment (version bêta) rien de plus que la cartographie des Dépendances applicatives.
Couche Infrastructure : La notion d’Environnement permet de distinguer par exemple les Composants techniques qui sont installés localement (On-Premise) de ceux qui sont installés sur le Cloud.
Carto-SI très fort pour le suivi des données
Données n’est pas vraiment une couche : cette notion traverse en fait les trois autres couches. Il est recommandé de renseigner, pour chaque donnée, quelle application source l’a créée (dans le champ Master Data). Il est également possible de préciser s’il s’agit d’une donnée personnelle et/ou sensible. Ces données élémentaires seront généralement associées à des Objets Applicatifs (ensembles de données).
Ce niveau de détail permettra de s’assurer de la conformité avec le RGPD.
Ainsi, le « Registre des traitements » des données est intégré à la solution Carto-SI.

Carto-SI : Registre des traitements de données pour RGPD
Il est ainsi possible de faire une étude d’impact spécifiquement sur la protection des données personnelles. L’outil PIA (Privacy Impact Assessment) de la CNIL est intégré dans Carto-SI et permet d’aller encore plus loin avec le RGPD et garantir la traçabilité des données de bout en bout.
Pour approfondir ce sujet important des données, il faudrait peut-être indiquer leurs types, leurs formats, leurs longueurs maximales et leurs caractères obligatoires ou facultatifs dans les Objets Applicatifs (informations non disponibles dans la version 4.7.34 testée).
Une gestion des dépendances très aboutie
Les objets de chaque couche sont bien souvent dépendants d’objets d’autres couches. Les dépendances permettent de réaliser des études d’impacts (avec la notion de profondeur). Des éléments de profondeurs différentes peuvent être regroupés, afin de simplifier la représentation graphique.

Carto-SI : Définition des dépendances entre les différents composants techniques (par saisie)
On peut définir les dépendances par saisie, en sélectionnant préalablement la ou les couches concernées (bouton Créer sur l’écran ci-dessous, qui concerne les Applications – Couche Applicative - dépendantes de Composants techniques – couche Infrastructure), mais également sur les diagrammes de la Cartographie ou de l’Etude d’impact, sans avoir besoin de se préoccuper des différentes couches. Une fonction Repositionner (automatiquement) permet de limiter les croisements dans la représentation graphique des dépendances.
Deux modules intéressants en plus
Livraisons permet de suivre les livraisons en Dev, en Préprod et en Prod (Mises en Production) des développements spécifiques, tandis que Gestion de licences permet de suivre les dates de début et de fin de licences de logiciels standards (généralement liées à des composants techniques ou applicatifs).
Mise en place de Carto-SI
En mode SaaS (rien à installer ; on ne s’embête pas avec les mises à jour et l'on bénéficie automatiquement de la dernière version) ou On-Premise (si contrainte sécuritaire ; installation en ½ heure via un conteneur Docker). Dans les deux cas, un grand écran est conseillé, afin d’éviter de trop utiliser l’ascenseur horizontal pour visualiser les larges tableaux.
Pas besoin d’une formation de plusieurs jours : une démonstration d’une heure et l’académie Carto-SI https://academy.carto-si.com/ en accès libre suffisent pour le prendre en main. Si les Imports (aux formats Excel ou CSV) pour faciliter la récolte d’informations existantes bénéficient d’une fonction dédiée dans le menu de Carto-SI, les Exports peuvent être effectués au niveau de nombreux écrans.

Carto-SI : Import d'un fichier CSV contenant la liste des applications du Système d'Information
Une période d’essai gratuite de 14 jours permet de réaliser une PoC. Une fois cette période d’essai passée, le nombre d’applications à cartographier sera le critère principal pour la facturation de la solution Carto-SI.
Conclusion
Carto-SI est une solution relativement simple, mais suffisamment complète pour cartographier son Système d’Information en profondeur. En plus de sa simplicité, ses deux principaux atouts sont le suivi des Données (dont la conformité au RGPD) et la gestion des Dépendances.
|
|
Thierry BIARD |
"La cartographie n’est pas une discipline rébarbative mais une manière passionnante et gratifiante de visualiser ses données. On y gagne en liberté - liberté de décision, d’analyse, de travail - mais aussi en conséquence en efficacité. Il faut toujours garder à l’esprit que réaliser une carte n’est affaire que de cohérence et de respect des subtilités de la vision humaine. La cartographie, à la fois, art et science, à la jonction de la technologie, de la communication et du graphisme, déploiera alors toutes ses qualités d’aide à l’action."
Poidevin, Didier (1999). La carte moyen d’action. Conception - réalisation. ellipses.
Compléments de lecture
- Démarche d’urbanisation du SI : les questions techniques, organisationnelles, voire existentielles
- L’Architecture Micro-Services expliquée à ma fille
- Inconvénients de l'Architecture Micro-Services
- Estimation de la complexité d’une Architecture Micro-Services
- Essai et évaluation de Modelio : est-il un bon outil de modélisation ?
- Archi (archimatetool) : essai et analyse de cet outil ArchiMate français gratuit sous Windows, Linux et Mac OS
- WinDesign : essai et analyse de la version d’évaluation, ce logiciel français est-il un bon outil pour l’Architecture d’Entreprise ?
- Quel outil ArchiMate pour modéliser vos architectures d’entreprise sources et cibles, évaluer les écarts, analyser les impacts et élaborer des trajectoires de transformation ? Obeo SmartEA S.1 Ep.1
- Comment consolider un référentiel centralisé TOGAF rassemblant les autres référentiels Stratégie, Métier, Applications, Infrastructure… ? Obeo SmartEA S.1 Ep.2
La rédaction tient à souligner que la plateforme urbanisation-si.com est indépendante de toute organisation et son fonctionnement repose entièrement sur des bénévoles passionnés de pédagogie et désirant partager leur expérience. Vous ne verrez jamais de publicités sur notre plateforme.
Bien que nous encourageons l’open source, il peut nous arriver d’utiliser des logiciels commerciaux qui nous sont gracieusement prêtés sous aucune condition et nous ne touchons aucune rémunération de qui que ce soit.
Comment partager le référentiel d’Architecture d’Entreprise TOGAF avec Enterprise Architect (EA) et sa plateforme Pro Cloud Server de l’éditeur Sparx Systems ?
“AE, ma sœur AE, ne vois-tu point l’IA venir ? Non, je ne vois que des éléments classiques et des aménagements cosmétiques…” Bien que certains éditeurs nous disent que l’intégration de l'IA est à l’étude, il semble que ce n'est pas pour tout de suite. En attendant, nous vous proposons d’examiner quelques fonctionnalités, du côté de l'Australie, de l’outil Enterprise Architect (EA) de Sparx Systems, comme nous l’avions fait avec son concurrent français Obeo SmartEA.

Image générée par ChatGPT.
Forces et faiblesses d’Enterprise Architect
EA rassemble tout ce qu'on peut imager comme outils pour gérer les composants d’une architecture d'entreprise. Rien n'y manque. Voici une liste à la Prévert : TOGAF, ArchiMate, BPMN, DMN. CMMN, UML, SysML, SOAML… la simulation de modèles, la mise en œuvre de méthodes agiles, Scrum, Kanban, la gestion de projet, Gantt, les exigences, les tests, XML, WSDL, API, REST, scripts SQL, la génération de code dans de nombreux langages, le maquettage d’écran, la conception et l’exécution des tests, la production de documentation, on pourrait continuer l'énumération des fonctionnalités proposées. À tel point qu’une fois dans l’outil, il est facile de se perdre, comme un Parisien au milieu du souk de Marrakech.
La collaboration a toujours été le talon d’Achille d’EA. Une plateforme de versioning était nécessaire pour centraliser les artefacts d’architecture. Chaque utilisateur devait avoir EA installé et être connecté à la plateforme.
Dans notre article "Comment consolider un référentiel centralisé TOGAF rassemblant les autres référentiels Stratégie, Métier, Applications, Infrastructure… ? Obeo SmartEA S.1 Ep.2", nous demandions à ChatGPT :
“A quels défis sont confrontés aujourd'hui les architectes d'entreprise ?”,
voici ce qu'il répondait en premier :
“L’un des principaux défis est de faire face à la complexité croissante des systèmes d’information et des technologies de l’information”.
Puis en deuxième :
“Les architectes d’entreprise doivent être en mesure de communiquer efficacement avec les parties prenantes de l’entreprise, y compris les cadres supérieurs, les responsables informatiques et les utilisateurs finaux”.
Le cloud au secours d’EA
EA reste l’outil d’administration du référentiel d’Architecture d’Entreprise (AE). Grâce à lui, l’architecte d’entreprise met en œuvre le framework TOGAF, cartographie les différentes strates d’architecture, structure le référentiel et doit s’assurer de la participation de tous les acteurs, les actionnaires, la DG, les responsables de domaines métiers, les architectes techniques… Pour ce faire, il doit être possible de communiquer tout ou partie du référentiel d’AE, de gérer des revues de cartographies, de solliciter les différents points de vue, de gérer des discussions, des anomalies, des simulations, d’effectuer des campagnes de tests.
Pour s’aligner sur les standards du marché, Sparx Systems a intégré le cloud dans son écosystème. La plateforme Pro Cloud Server permet à l'administrateur de stocker le référentiel d’AE dans le cloud. Les modèles d’entreprise sont accessibles grâce à l’application WebEA, développée en PHP et déployée dans un serveur Apache, ce qui permet aux parties prenantes de :
- les réviser,
- discuter de leur pertinence et de leur validité,
- les commenter,
- les illustrer avec des cas d’utilisation,
- les tester,
- gérer les exigences,
- identifier les problèmes,
- les tester
- suivre les modifications du modèle via une liste de surveillance
Un cas d’utilisation :
Automatiser le ranking des mails pour la Relation Client
Partant du constat que la Relation Client (RC) est mal notée dans les avis, la DG pose comme objectif d’améliorer la RC, avec comme indicateur d’être en tête dans le classement de RC.
Enterprise Architect propose sur étagères les patterns d’AE :

L’architecte d’entreprise crée la vue ArchiMate en adaptant le pattern Réalisation des objectifs :

Partant du fait que la RC est aujourd'hui un domaine stratégique pour l'entreprise,
il a été décidé d'intégrer de l'IA dans son fonctionnement.
L’architecte d’entreprise connecte le modèle dans le cloud (plateforme Pro Cloud Server) :

Une fois les modèles connectés à la plateforme Pro Cloud Server,
les parties prenantes dument autorisées pourront les consulter et collaborer.
WebEA
L’architecte technique se connecte, via la plateforme Pro Cloud Server, au projet créé par l’architecte d’entreprise. Il visualise le modèle :

Création d’une revue à propos du modèle précédent
L’architecte technique peut alors créer une revue :

Enterprise Architect et son application WebEA permettant aux acteurs de l'Architecture d'Entreprise de collaborer à la validation des modèles. Ici, on va ajouter un élément de type "Revue".
Identification et priorisation des risques
L'architecte technique identifie et priorise des risques liés à la stratégie consistant à intégrer l'IA dans la RC :
- Risque projet : Compétences en intégration des IA agentiques
Le chef de projet doit être formé à l'IA, ainsi que l'architecte technique
[Criticité : Moyenne (2)] - Risque fonctionnel : Intégration de l'IA : risques métier et technique
- Plan préventif : une POC doit être réalisée sur une durée de 6 mois, pour évaluer techniquement et pour mesurer les apports en termes de coûts, délais et qualité à la RC.
[Criticité : Haute (3)] - Prendre un prestataire expert en intégration de l'IA.
- Plan préventif : une POC doit être réalisée sur une durée de 6 mois, pour évaluer techniquement et pour mesurer les apports en termes de coûts, délais et qualité à la RC.

Ajout d'un risque à un élément pour le modèle d'intégration de l'IA dans la RC.

Avec le référentiel d'AE partagé, la collaboration entre parties prenantes est facilitée.
La discussion sur l'atténuation des risques peut s'engager.
Conclusion
Autant nous avons toujours été enthousiastes avec la version locale d’Enterprise Architect, autant nous sommes réservés concernant cette plateforme cloud, qui nous paraît fonctionnellement limitée et d’une effroyable complexité pour son intégration (voir l’annexe). Dans une matrice RACI (Réalisateur, Approbateur, Consulté, Informé) des responsabilités des parties prenantes, l'application WebEA semble réservée au C et au I. Remercions toutefois, l'équipe technique de Sparx Systems, qui a été constamment à nos côtés pour la mise en œuvre.
Lors de nos tests, son concurrent français Obeo SmartEA faisait mieux (voir nos articles dans les compléments de lecture). Contacté, Obeo nous dit que de nouvelles fonctionnalités seraient à l'étude, comme le requêtage en français du référentiel et la génération d’une partie du modèle.
Le coq serait-il plus fort que le kangourou ?

|
|
Rhona Maxwel @rhona_helena |
"Ce qu'on appelle stratégie consiste essentiellement
à passer les rivières sur des ponts et à franchir les montagnes par les cols."
Anatole France
Annexe : Intégration de Pro Cloud Server
1 - Demander une version d'essai
Faire la demande : "Request Pro Cloud Server trial"
Une fois enregistré, vous recevrez par mail le fichier " _SSPCSTRIAL_RegistrationText.txt" contenant votre nom d'utilisateur, votre mot de passe et votre numéro de licence temporaire.
2 - Télécharger Pro Cloud Server
Entrer le nom d'utilisateur et le mot de passe fourni dans le mail reçu.
3 - Exécuter le fichier *.msi
Exécuter "ssprocloudserver_x64.msi" et suivre les indications
Vérifier dans taskmgr le démarrage du service Windows :

4 - Faire une demande de fichier "pcsrequest.csr" pour activer la licence
Une fois installé, dans le répertoire Client, lancer "Pro Cloud Config Client" afin de générer la demande d'activation de la licence en utilisant le mot de passe par défaut fourni dans le mail reçu de Sparx Systems.


Cliquer sur Licensing

Cliquer sur Create Request

Dans Installation ID, saisir le numéro de licence se trouvant dans le fichier "_SSPCSTRIAL_RegistrationText.txt" fourni par Sparx Systems lors de la demande d’essai ou lors de l’achat du produit.
Une fois validé, un fichier "pcsrequest.csr" est créé dans le répertoire que vous avez indiqué.
Envoyer ce fichier à Sparx Systems à l'adresse du mail de réponse à votre demande d'essai.
5 - Activer le fichier licence reçu “pcslicensecert.lic”
Vous recevrez en retour un fichier “pcslicensecert.lic”, contenant la licence temporaire.
Procédure similaire à la demande, dans l'écran Pro Cloud Server Configuration Client :
Add > Indiquer le fichier licence.
Une fois la licence enregistrée, vous pouvez activer le protocole de communication OSLC entre le client WebEA et le serveur (Pro Cloud Server).
6 - Configurer le client avec l'outil Windows : Pro Cloud Configuration Client
Pour créer la base de données pour vos modèles :
- dans le répertoire Client de l'installation, lancer "SSProCloudClient.exe" (Pro Cloud Configuration Client)
- Onglet Database Managers > Add > Sélectionner le SGBDR open source Firebird embarqué dans Pro Cloud Server > Saisir un nom de fichier, par ex. : rhonamodel.feap > OK

Le nouveau “Database Manager” apparaît en orange, il reste à le configurer. Pour cela, le sélectionner, puis double-cliquer > Cocher Enabled et Enable Pro Features (OSLC, WebEA and Integration) qui est cliquable uniquement si la licence a été ajoutée. > OK


Pour activer le protocole OSLC pour le port 1804 pour HTTP :
Onglet Ports > Sélectionner le port 1804 > double-clic > une fois la licence reconnue, vous pouvez cocher OSLC Supported


Avec taskmgr, redémarrer le service Windows “Sparx Systems Professional Cloud”
7 - Créer un modèle dans Pro Server Cloud à partir de Enterprise Architect
Dans EA > Open Project

Connect To Cloud > Indiquer l’adresse IP du serveur, dans notre exemple, il s’agit de localhost, puis indiquer le port HTTP, ici 1804 (pour HTTPS, ce sera 1805).

Dans le nouveau projet, créer :
- un package, par ex. “Test-Pro-Cloud-Server”
- un modèle ArchiMate à partir de l’assistant générant les vues de l’Open Group > dans la liste des perspectives > Enterprise Architecture > ArchiMate > Basic Viewpoints > Service Realization Viewpoint

Cliquer sur Create Model

Personnaliser la vue ArchiMate dans EA :

Dans EA > Settings > Model > Options > Cloud > Cocher “Auto create Diagram Image” et “Auto create HTML Page” et “Enable Pro Cloud Server Connection” > Close

8 - Configurer le client avec l'outil web : WebConfig
WebConfig est l’équivalent web du client Windows de configuration vu précédemment (Pro Cloud Config Client).
Il s’agit d’une application web développée en PHP. Pour l’installer, il suffit d’installer XAMPP (XAMPP Apache + MariaDB + PHP + Perl), qui intègre le serveur HTTP Apache incluant PHP.
Télécharger XAMPP
Une fois installé, copier le répertoire WebConfig du répertoire d’installation de Pro Cloud Server dans le répertoire htdocs du répertoire d’installation de XAMPP
Démarrer le “Control Panel” de XAMPP sous Windows.
Démarrer uniquement Apache :

Une fois Pro Cloud Server et Apache démarrés, aller dans un navigateur et saisir :
http://localhost/WebConfig/
On retrouve les fonctionnalités du client Windows de configuration :


9 - Configurer les autorisations d'accès au référentiel partagé
De la même manière que pour Webconfig, copier le répertoire WebEA du répertoire d’installation de Pro Cloud Server dans le répertoire htdocs du répertoire d’installation de XAMPP
Le projet créé précédemment par Enterprise Architect et stocké dans le Pro cloud Server doit être paramétré dans le fichier "webea_config.ini" du répertoire "xampp\htdocs\WebEA\includes".
Remplacer les valeurs de tous les paramètres sscs_db_alias par le nom de votre projet. Dans notre démonstration, il s’agit de “rhonamodel”.



Les autres options pour le model3 sont inchangées.
Si Apache était démarré, arrêter-le et redémarrer-le grâce au XAMPP Control Panel.
10 - Accéder au référentiel partagé avec WebEA
Dans votre navigateur : http://localhost/WebEA

Prendre par exemple les accès complets nécessitant le code d'accès paramétré précédemment.
Cliquer sur Desktop.

Saisir la valeur du paramètre auth_code du fichier webea_config.ini.

Un utilisateur, dument authentifié et autorisé, peut accéder
au modèle créé avec EA par l'architecte d'entreprise.
En fonction de la façon dont le modèle actuel a été configuré dans le fichier de configuration de WebEA et de votre accès de sécurité au modèle, vous pouvez avoir la possibilité de créer (+ vert <New>) une plage d’objets dans le modèle via WebEA. Voir "Un cas d’utilisation : Automatiser le ranking des mails pour la Relation Client" plus haut dans le corps de l'article.
Ces objets incluent : les packages, les diagrammes, les cas d’utilisation, les exigences, les composants, les modifications, les problèmes, les tests, les décisions, les défauts et les événements. (Package, Diagram, Review, Actor, Change, Component, Feature, Issue, Node, Requirement, Task, Use Case).
En plus d’ajouter de nouveaux éléments, vous pouvez également modifier les notes de n’importe quel objet, quel que soit son type, ainsi que les détails des tests d’éléments et des allocations de ressources pour n’importe quel élément du modèle, que vous l’ayez créé ou non.
Vous pouvez :
- Créer des éléments : dans la vue principale WebEA - Propriétés de l’objet - Add New.
- Afficher les propriétés de l’élément auquel vous souhaitez ajouter une fonctionnalité, cliquer sur le bouton “Add New”. Un menu s’affiche et propose des options pour ajouter à l’élément chaque fonctionnalité à condition d'avoir les droits. (Other Objects, Tests, Resources, Features, Changes, Documents, Defects, Issues, Tasks, Risks).
Compléments de lecture
- Quel outil ArchiMate pour modéliser vos architectures d’entreprise sources et cibles, évaluer les écarts, analyser les impacts et élaborer des trajectoires de transformation ? Obeo SmartEA S.1 Ep.1
- Comment consolider un référentiel centralisé TOGAF rassemblant les autres référentiels Stratégie, Métier, Applications, Infrastructure… ? Obeo SmartEA S.1 Ep.2
- Alimenter le référentiel d’Architecture d’Entreprise pour la couche Application de TOGAF avec l’outil Information System Designer (ISD) d’Obeo - Modélisation de l’analyse des besoins S.1 Ep.1
- Méthode Graal, le NoUML d’Obeo, parfaite fusion entre un UML phagocyté et un BPMN édulcoré. S.1 Ep.2
- Comment assurer la traçabilité des exigences avec les user stories, les use cases, les processus métier, la cinématique et les maquettes d'écrans ? Une solution dans notre test Obeo ISD S.1 Ep.3
- Quelle solution pour concevoir la modélisation d’une architecture micro-services, l’intégrer dans une architecture d’entreprise et permettre une collaboration avec l’ensemble des acteurs projet ? Obeo ISD S.1 Ep.4
- Vous cherchez un outil pour gérer le mapping entre les objets métier et une base de données relationnelle, générer les scripts SQL et produire du code à partir de vos modèles ? Obeo ISD S.1 Ep.5
- Comment générer par ChatGPT vos diagrammes ArchiMate gratuitement ?
- ChatGPT, l’outil idéal de réalisation de modèles pour l’Architecture d’Entreprise et l’Urbanisation du Système d’Information ?
- Top 5 2023 des outils gratuits ou open source pour l’Architecture d'Entreprise et la modélisation du Système d’Information
La rédaction tient à souligner que la plateforme urbanisation-si.com est indépendante de toute organisation et son fonctionnement repose entièrement sur des bénévoles passionnés de pédagogie et désirant partager leur expérience. Vous ne verrez jamais de publicités sur notre plateforme.
Bien que nous encourageons l’open source, il peut nous arriver d’utiliser des logiciels commerciaux qui nous sont gracieusement prêtés sous aucune condition et nous ne touchons aucune rémunération de qui que ce soit.
BPMN, CMMN et DMN : évolution des spécifications et émergence du langage FEEL
En tant que lecteur assidu de notre blog www.urbanisation-si.com, vous avez bien compris que nous préférons les notations normalisées et nous ne prenons pas beaucoup de risques quand nous vous recommandons de les utiliser. Selon les notations, leurs spécifications sont mises à jour plus ou moins régulièrement, mais la fréquence de ces mises à jour n’est pas forcément le signe de leur usage intensif. Nous allons démontrer ici que c’est même le contraire, ce qui semble paradoxal. C’est à travers ce prisme que nous allons faire le point dans cet article sur les évolutions des spécifications BPMN, CMMN et DMN, surtout DMN en fait, avec son langage FEEL et un exemple d’application.

BPMN (Business Process Model and Notation)
La dernière version 2.0.2 de BPMN fut publiée en janvier 2014, soit il y a plus de 11 ans déjà. Et encore, il ne s’agissait que d’un simple changement mineur concernant les formats d’échanges. La version 2.0.1 mineure précédente, publiée en septembre 2013, était plus importante, car elle permit à BPMN de devenir un véritable standard international : ISO/IEC 19510. En fait, la dernière version majeure 2.0 fut publiée en décembre 2010. Aucune mise à jour majeure depuis une quinzaine d’années donc, mais BPMN est pourtant une notation qui remporte un énorme succès. Peut-être que les spécifications de BPMN (une belle somme de 532 pages pour la version 2.0.2) ont approché, voire atteint, l’exhaustivité ?

Exemple d’un diagramme d’orchestration BPMN
représentant un processus d’approvisionnement (OMG)
CMMN (Case Management Model and Notation)
Seulement deux versions pour CMMN : la version initiale 1.0 en mai 2014, puis la version 1.1 en décembre 2016. Nous n’avons jamais été de fervents supporters de CMMN. En gros, CMMN permet de lister des tâches qui pourront être exécutées par les opérateurs dans n’importe quel ordre, en fait dans un ordre adéquat qui ne peut pas être prédéterminé et qui répond à un besoin de flexibilité. On reconnait un diagramme CMMN à sa représentation octogonale des étapes (stages) :

Exemple d’un modèle plan de cas CMMN représentant la gestion des réclamations (OMG)
Afin d’une notation normalisée soit utilisée, il faut qu’elle soit supportée par l’outillage. L’éditeur allemand Camunda a décidé d’arrêter de supporter CMNN en 2019, tandis que d’autres, comme l’éditeur australien Sparx Systems et l’éditeur canadien Trisotech, continuent de la supporter. Trisotech promeut le concept de Triple Crown - triple couronne, sorte de tiercé gagnant pour améliorer les processus métier - constituée de BPMN + CMMN + DMN. Finalement, CMMN ne semble pas avoir rencontré le succès escompté. Ce qui est absolument certain, c’est que CMMN est bien moins utilisé que BPMN.
Rappelons que BPMN propose le sous-processus Ad-Hoc, reconnaissable à son tilde « ~ », qui permet en partie de modéliser de tels cas, sans doute bien difficiles à automatiser. Voici l’exemple officiel de sous-processus Ad-Hoc, extrait de la spécification BPMN 2.0.2 :

Exemple d’un sous-processus BPMN Ad-Hoc représentant l’écriture d’un chapitre de livre (OMG)
Ce sous-processus Ad-Hoc représente l’écriture d’un chapitre de livre (mais aussi l’écriture de cet article !) : on effectue des recherches, on écrit du texte, on crée des illustrations, etc., dans un ordre quelconque (SANS flux de séquence entre les tâches) et souvent plusieurs fois, pourvu que le livrable final (un chapitre ou cet article donc) constitue un ensemble logique et cohérent (c’est ce que l’on espère !).
DMN (Decision Model and Notation)
Si la notation DMN peut s’utiliser seule, rappelons qu’elle est aussi destinée à compléter BPMN. Ou plutôt, selon le principe de séparation des préoccupations, à dissocier les prises de décisions des processus métier. Comme nous le démontrerons plus loin, cela permet de faire évoluer une prise de décision, sans modifier le processus métier qui invoque cette prise de décision. Rappelons que DMN ne sert pas qu’à représenter les prises de décisions, mais peut également servir à représenter des calculs plus ou moins complexes (exemple : calculer le pourcentage d’une remise commerciale, selon l’ancienneté du client, le montant de sa commande, etc.).
Tandis que la notation DMN semble encore peu utilisée, notamment en France, le groupe de travail de l’organisme normalisateur OMG est très actif, avec en moyenne une nouvelle version des spécifications DMN tous les 2 ans depuis 10 ans ! Voici l’historique des différentes versions de DMN :

Historique des différentes versions de DMN
N.B. Une version 1.6 Beta de la spécification DMN est déjà publiée.
Langage FEEL (Friendly Enough Expression Language)
Si le nombre de pages des spécifications DMN est un indicateur, la tendance étant généralement à la hausse d’une ancienne vers une nouvelle version (dans un volume toutefois contenu de 250 pages en moyenne depuis plusieurs années), un autre indicateur a retenu notre attention : le nombre de fonctions du langage FEEL (Friendly Enough Expression Language). Il s’agit donc d’un langage destiné théoriquement à une large audience : les développeurs, mais aussi les experts métier.
Si, au début, il était réservé pour les expressions littérales et les tables de décision de DMN, il est désormais possible de l’utiliser dans BPMN (bien que la dernière version 2.0.2 des spécifications n’en fasse aucune mention, mais vous avez bien noté que BPMN est antérieure à DMN) : dans les passerelles (gateways) conditionnelles et dans les tâches de type Script. L’éditeur Camunda offre également la possibilité d’utiliser le langage FEEL dans ses formulaires.
En 10 ans, le nombre de fonctions de FEEL a plus que doublé, atteignant la centaine ! Dans le tableau récapitulatif ci-dessous, nous nous sommes alignés sur les différents types de fonctions de la version 1.5 de spécifications DMN, alors que des regroupements fonctionnels pourraient être effectués (Date and time, Temporal et Miscellaneous, par exemple) :

Nombre de fonctions FEEL intégrées, par type et par version de DMN
Certains éditeurs comme Camunda ajoutent déjà certaines fonctions FEEL étendues (la dernière ligne du tableau ci-dessous), sans attendre qu’elles soient normalisées dans la dernière version 1.5 de la spécification DMN : nous vous recommandons d’utiliser ces fonctions avec parcimonie, en espérant qu’elles soient normalisées dans la prochaine version… Bon, l’éditeur Camunda est un membre très actif du groupe de travail DMN de l’OMG. Ces fonctions supplémentaires sont clairement reconnaissables dans la documentation en ligne grâce à la mention « Camunda Extension ».
Exemple d’application simple, mais opérationnel
Voici un exemple très simple pour illustrer l’utilisation du langage FEEL dans la notation DMN. Soit le processus métier d’un transporteur qui consiste à indiquer au destinataire d’un colis une date de livraison en fonction d’une date d’expédition. Dans la représentation BPMN du processus, une tâche de type Règle Métier (symbolisé par la petite table de décision au haut à gauche du rectangle) calculera cette date de livraison. Nous verrons que la méthode de calcul de cette date de livraison pourra évoluer au fil du temps et devenir plus élaborée, SANS modifier la représentation BPMN du processus : c’est là l’illustration du principe de séparation des préoccupations.

Diagramme d’orchestration BPMN simple, mais immuable, représentant le calcul d’une date de livraison
Il convient ensuite de créer un modèle DMN, en l’occurrence un diagramme DRD (Decision Requirements Diagram) avec au moins une décision - ou un calcul - complétée par une expression littérale ou une table de décision. Voyons en détail ces deux possibilités.
Selon le plan de transport, la livraison de colis est théoriquement effectuée le lendemain de l’expédition, délai que l’on nomme souvent « J+1 ». Le langage FEEL propose la fonction « duration » pour calculer cette date de livraison. En fait, il suffit d’ajouter une Période de 1 jour « P1D » (ce format de durée est défini dans XPath Data Model) à la date d’expédition. Voilà comment cela se traduit en langage FEEL, dans une expression littérale :

Diagramme DRD et expression littérale associée simple, en langage FEEL (DMN)
Mais les livraisons ne sont pas effectuées par ce transporteur durant le weekend, aussi : si la date d’expédition est un vendredi (5e jour de la semaine), on ajoutera deux jours de plus, et si la date d’expédition est un samedi (6e jour de la semaine), on ajoutera un jour de plus, afin de livrer le lundi qui suit. Voilà comment cela se traduit en langage FEEL, toujours dans une expression littérale :

Diagramme DRD et expression littérale associée plus élaborée, en langage FEEL (DMN),
afin de prendre en compte les weekends

Résultat de l’exécution de cette expression (variable d’entrée, puis variable de sortie).
Mais plutôt que d’imbriquer plusieurs tests « if-then-else » (disponible dans le langage FEEL donc) comme avec n’importe quel autre langage de programmation (cela reste toutefois lisible grâce à un effort sur l’indentation), il est préférable ici d’utiliser l’une des fonctionnalités de DMN, en l’occurrence une table de décision, plus lisible et donc plus facilement modifiable qu’une expression littérale (en cas de changement du plan de transport, dans cet exemple) :

Diagramme DRD et table de décision associée, en langage FEEL (DMN),
prenant en compte les weekends
Une démarche « Low Code » ? Vous remarquerez que dans la formalisation des règles métier dans une table de décision, le « when » remplace le « if ». Pas de changement pour le « then ». Quant au « else », il devient implicite : chaque règle, c.-à-d. chaque ligne (numérotée de 1 à 4 dans la table de décision ci-dessus) correspond plus ou moins à un « else » (pour être précis, cela dépend de la Hit policy, mais ce point important mériterait un prochain article pour lui tout seul).
Des éditeurs interactifs en ligne permettent de tester partiellement vos expressions en langage FEEL. Cette méthode de calcul de la date de livraison est encore assez sommaire. La prochaine étape consisterait à prendre en compte dans le calcul, en plus des weekends, les jours fériés. Toujours SANS modifier (et SANS redéployer) la représentation BPMN du processus, qui se contente de la simple tâche « Calculer Date Livraison ».
Conclusion
BPMN est une norme (et même un standard ISO) peu mise à jour, mais très utilisée, tandis que DMN est une norme bien vivante et régulièrement mise à jour, mais encore peu utilisée : pas forcément très logique, tout cela !
Continuez à utiliser BPMN, dont si nécessaire ses sous-processus Ad-Hoc pour remplacer CMMN. Mais surtout, n’hésitez pas à séparer les prises de décisions et les calculs complexes dans des modèles DMN, puis à évaluer puis utiliser les nombreuses fonctions du langage FEEL, dans vos expressions littérales et tables de décision notamment.
|
|
Thierry BIARD |
« Le secret pour réussir, c’est de toujours prendre de bonnes décisions.
Et comment prend-on de bonnes décisions ? Grâce à l’expérience.
Et comment acquiert-on de l’expérience ? En prenant de mauvaises décisions. »
Citation attribuée à Mark Twain
Annexe
Cet exemple opérationnel d'application du langage FEEL de DMN a été réalisé avec :
- Camunda Modeler version 5.33.1,
- Camunda 8 Run version 8.6.12.
L'installation de Camunda Modeler n'a rien de particulièrement difficile.
L'installation de Camunda 8 Run nécessite l'installation préalable d'un JDK (Java Development Kit) version 21 ou supérieure, qui n'est pas une version très courante (bien que la dernière version du JDK en cours de développement soit la version 25, Oracle recommande toujours la version 8 de Java aux utilisateurs finals !). Comme avec d'autres composants, choisissez de préférence une version LTS (Long Term Support). Enfin, n'oubliez pas d'initialiser les variables d'environnement JAVA_HOME et JAVA_VERSION :

Une fois la version adéquate de JDK installée et le paquet ZIP de Camunda 8 Run extrait dans un répertoire, il suffit de le démarrer en saisissant "c8run start". Le moteur de base de données Elasticsearch démarre avant Camunda, après un nombre aléatoire de tentatives, ce qui est assez surprenant :

La fin du démarrage de Camunda lance automatiquement votre navigateur web préféré avec l'URL "Operate" (Username = Password = demo) :

Avec Camunda Modeler, il faudra choisir la version 8 de Camunda lors de la création d'un nouveau fichier, que ce soit pour BPMN, DMN ou Form (Formulaire). Ces trois types de fichiers devront ensuite être déployés sur Camunda 8 Run de la même façon avant utilisation. Pour cela, il suffit de cliquer sur la petite fusée en bas à gauche de la fenêtre principale de Camunda Modeler, puis sur le bouton Deploy :

Seul le processus métier peut être démarré à partir de Camunda Modeler. Il suffit de cliquer sur la petite flèche en bas à gauche, puis sur le bouton Start. Inutile d'indiquer une variable optionnelle au format JSON, car cette variable va être renseignée lors de la saisie du formulaire.

Pour effectuer cette saisie du formulaire, indiquez l'URL de la Tasklist, choisissez la tâche en attente, cliquez sur le bouton M'assigner, saisissez la Date d'expédition (ou sélectionnez-là dans le calendrier qui s'affiche) et enfin cliquez sur le Bouton du bas "Terminer la tâche" (un message fugace "Tâche terminée" s'affiche) :

Retournez sur l'URL Operate, cliquez sur l'onglet Decisions, puis cliquez sur la Decision Instance Key la plus récente.

La règle qui a été appliquée pour prendre la dernière décision est surlignée (ici la #2).
Cliquez enfin sur l'onglet Result pour voir le résultat, suite à l'application de cette règle.

A la fin de l'utilisation, pour arrêter Camunda 8 Run, saisissez "c8run stop" :

Compléments de lecture
DMN
- Quels sont les objectifs et les concepts de la notation de modélisation des règles métier, DMN Decision Model and Notation ?
- DMN - L'antisèche de la notation complète des composants d'un DRD ( Decision Requirement Diagram ) : notation de la décision
- La norme DMN ( Decision Model and Notation ) pour les tables de décision
- Tutoriel – didacticiel – exemple complet sur la norme de modélisation des règles métiers DMN ( Decision Model Notation ) : le processus métier BPMN
- Tutoriel – didacticiel – exemple complet sur la norme de modélisation des règles métiers DMN ( Decision Model Notation ) : La vue des exigences des décisions
- Tutoriel – didacticiel – exemple complet sur la norme de modélisation des règles métiers DMN ( Decision Model Notation ) : Exemple d'exécution du modèle de décisions
BPMN
- Vous cherchez désespérément un formalisme pour vos processus métiers mettant en accord MOA et MOE, la solution miracle existe, elle s'appelle BPMN
- Comment identifier, simuler, améliorer et modéliser les processus métiers ?
- Comment mettre en place un jeux de rôles pour modéliser un processus métier ?
- BPSim, la théorie et la pratique de la simulation de processus BPMN
CMMN
La rédaction tient à souligner que la plateforme urbanisation-si.com est indépendante de toute organisation et son fonctionnement repose entièrement sur des bénévoles passionnés de pédagogie et désirant partager leur expérience. Vous ne verrez jamais de publicités sur notre plateforme.
Bien que nous encourageons l’open source, il peut nous arriver d’utiliser des logiciels commerciaux qui nous sont gracieusement prêtés sous aucune condition et nous ne touchons aucune rémunération de qui que ce soit.
Loi de Gabor : technologie et progrès
Extrait de l'article de référence : Can We Survive Our Future ? A Conversation with Dennis Gabor

The principle of technological civilisation itself: "what can be made, will be made." "Progress" tends to apply new techniques and to establish industries regardless of whether they are truly desirable or not.
Cette version originale ayant été traduite librement de diverses manières, plus ou moins subjectives, nous lui préférons ici une traduction littérale :
Le principe même d'une civilisation technologique : « Ce qui peut être fait, sera fait ». Le « Progrès » tend à appliquer de nouvelles techniques et à établir des industries, indépendamment du fait qu'elles soient vraiment souhaitables ou pas.
C'est Gabor lui-même qui a mis des guillemets autour du mot « Progress », car si ce principe conduit à appliquer de nouvelles techniques et établir des industries qui NE sont PAS souhaitables, est-ce vraiment le Progrès ?
Que penser notamment de l'industrie nucléaire, qui commença son développement dans le secteur militaire avec des armes de destruction massive (puis « heureusement » de dissuasion), mais qui aujourd'hui concerne essentiellement le secteur civil (dont l'usage reste toutefois très controversé) et fournit probablement l'énergie nécessaire à l'ordinateur utilisé pour écrire cet article ?
Qui était Gabor ?
Dennis Gabor (1900-1979) était un ingénieur et physicien d'origine hongroise. Il est connu comme étant l'inventeur de l'holographie (ce qui lui a valu le prix Nobel de Physique en 1971).
Version originale du 17/02/2025
|
|
Thierry BIARD
|
"Science sans conscience n'est que ruine de l'âme."
Rabelais.
Compléments de lecture
- Moore, Murphy, Pareto, Maslow, Asimov… pionniers, voire visionnaires : les lois qui portent leurs noms s’appliquent-elles encore à l’informatique ?
- ChatGPT, l’outil idéal de réalisation de modèles pour l’Architecture d’Entreprise et l’Urbanisation du Système d’Information ?
- Architecture d'Entreprise augmentée, quelle influence de l’Intelligence Artificielle sur la gouvernance et la stratégie ?
- Comment gérer efficacement votre documentation d'architecture technique ? Essayez le C4 model avec l'outil Uncia
- Essai et évaluation de Modelio : est-il un bon outil de modélisation ?
- WinDesign : essai et analyse de la version d’évaluation, ce logiciel français est-il un bon outil pour l’Architecture d’Entreprise ?
- Quel outil ArchiMate pour modéliser vos architectures d’entreprise sources et cibles, évaluer les écarts, analyser les impacts et élaborer des trajectoires de transformation ? Obeo SmartEA S.1 Ep.1
- Comment consolider un référentiel centralisé TOGAF rassemblant les autres référentiels Stratégie, Métier, Applications, Infrastructure… ? Obeo SmartEA S.1 Ep.2
- Archi (archimatetool) : essai et analyse de cet outil ArchiMate français gratuit sous Windows, Linux et Mac OS
- ADOIT:CE pour la gestion de l’Architecture d’Entreprise
La rédaction tient à souligner que la plateforme urbanisation-si.com est indépendante de toute organisation et son fonctionnement repose entièrement sur des bénévoles passionnés de pédagogie et désirant partager leur expérience. Vous ne verrez jamais de publicités sur notre plateforme.
Bien que nous encourageons l’open source, il peut nous arriver d’utiliser des logiciels commerciaux qui nous sont gracieusement prêtés sous aucune condition et nous ne touchons aucune rémunération de qui que ce soit.
Les architectures catholiques du S.I. (2/2)
Voici la seconde partie de notre exploration des architectures catholiques du S.I. (commencée ici "Les architectures catholiques du S.I. (1/2)"), étant entendu que celle-ci ne se prétend en aucune manière exhaustive.

Illustration créée par ChatGPT - DALL-E pour cet article
L’Architecture orientée Bidouille (AoB)
Cette architecture très populaire est guidée par la recherche systématique d’une solution à court terme facile à trouver, facile à réaliser, et peu coûteuse, le sacro-saint « quick win ». Bref, l’idéal quand on n’a pas affaire à un système (d’information), et quand le périmètre du sujet traité a une durée de vie courte… ce qui n’est quasiment jamais le cas. Ce style d’architecture du S.I. aboutit ainsi à mettre de la bidouille sur de la bidouille sur de la bidouille (vous me rajouterez un peu de bidouille pour corriger les effets d’une bidouille précédente…), jusqu’à ce que, étonnamment, le coût de l’ensemble devienne insupportable, sa qualité devienne déplorable et son évolutivité quasi nulle.
Cette architecture a quelques caractéristiques qui méritent que l’on s’y attarde. Premièrement, elle n’est quasiment pas documentée. Normal, puisque sa logique est systématiquement court-termiste alors que la documentation, par essence, s’effectue dans une démarche d’héritage, de transmission, donc de moyen / long terme — paradoxe savoureux, cette logique court-termiste peut courir pendant des années ; c’est même pour cela qu’elle est douloureuse.
Deuxièmement, elle se construit par des bonds réalisés par un individu. En effet, comme chaque évolution est petite, elle n’est réalisée que par une seule personne, celle qui la plupart du temps l’aura d’ailleurs préalablement proposée (« Je peux le faire » annonce ainsi fièrement celui qui pourra ensuite se targuer d’être celui qui aura « solutionné le problème » si efficacement, faisant ainsi le bonheur du chef de projet ou du responsable hiérarchique qui aura ainsi « tenu le budget »). Ce phénomène renforce d’ailleurs l’absence de documentation (« la documentation est dans le code », en fait dans sa tête), car celui qui réalise devient également celui qui maintient. Et ce dernier va se faire un plaisir, au gré des évolutions demandées, de faire grossir son paquet de bidouilles (d’autres termes moins fleuris, mais tout aussi pertinents, pourraient venir à l’esprit du lecteur espiègle, mais je lui en laisserais l’entière responsabilité).
Précisons bien que cela ne signifie pas qu’un seul individu est à l’origine de toute la bidouille présente dans le S.I. On peut parfaitement y trouver plusieurs paquets de bidouilles, chacun ayant son propre auteur. Et pour boire le calice jusqu’à la lie, un paquet de bidouilles peut parfaitement traiter de sujets qui n’ont rien à voir entre eux. Simplement, comme ils ont été traités par une même personne qui ne veut pas s’embêter à faire un autre paquet (dans tous les cas, c’est son « quick win »), ils se retrouvent intriqués, interdépendants.
Il y a alors une seconde phase dans cette architecture : la vitrification. Le temporaire s’éternise. Car, certes, le coût de l’ensemble devient exorbitant, mais le coût du remplacement l’est également (avec en plus un certain degré d’incertitude). Un consensus s’établit alors pour décider que, même s’il fallait le remplacer, il est urgent d’attendre, d’autant que l’on souhaite réaliser des dépenses d’investissement sur un autre sujet un peu plus glamour (la même décision, basée sur le même constat et la même envie, sera donc prise l’année suivante, et la boucle est bouclée). Il est à noter que, bizarrement, personne ne songe à demander au créateur et mainteneur du tas de bidouilles de mettre à profit l’année perdue pour le documenter et ainsi faciliter son remplacement.
Eh oui, l’existant coûte, mais il s’agit là d’un « coût de fonctionnement », donc peu sexy, qui n’intéresse personne ou presque, tant qu’il reste en dessous d’un certain seuil de douleur.
Le « build » (et son coût) est surveillé, l’affectation de son budget pour l’année à suivre peut faire l’objet d’innombrables réunions pendant des mois, mais le « run », lui, est subit. Voici une illustration de plus que la psychologie a un impact fondamental sur l’architecture d’un Système d’Information.
Il est valorisant de construire, mais pas de maintenir, ni encore moins de détruire. Nos écoles d’ingénieurs forment des bâtisseurs, pas des nettoyeurs. Qui a déjà été félicité pour avoir nettoyer les écuries d’Augias : décommissionner n logiciels inutiles, redondants, voire dangereux, ou pour avoir supprimer des flux illogiques [5] et optimiser des communications en point-à-point ? Alors qu’ajouter (ou remplacer) un logiciel entraîne facilement une bonne publicité interne.
Autre biais psychologique, un tas de bidouilles étant l’émanation d’une seule personne, il devient son bébé. Elle l’aura créé, elle l’aura fait grandir, elle est la seule à vraiment le connaître (il assoit sa légitimité), et il peut même devenir pour cette raison son activité principale. À partir de là, on comprend bien qu’elle aura donc du mal à accepter d’en faire la critique et à le voir disparaître. Autrement dit, encore une fois, cette architecture crée une tension entre l’intérêt général et des intérêts individuels.
[5] Pour le coup, j’ai quand même eu cette chance une fois dans ma carrière.
L’Architecture par Népotisme (ApN)
Les liens interpersonnels qui se créent dans une société en débordent : les personnes qui changent d’organisation ou qui passent d’une société à une autre conservent des liens avec de précédents collègues (d’autant que les autres sociétés vers lesquelles aller assez facilement participent logiquement d’un même écosystème ; elles sont soit clientes, soit fournisseuses, soit concurrentes, de la première : on a donc une certaine probabilité de retrouver d’anciens collègues quand on en quitte une), les anciens élèves d’une même école nourrissent leur réseau, les liens familiaux s’en mêlent, des couples se créent, ou encore d’aucuns utilisent leur proximité avec certains collègues pour créer leur société avec la certitude que celle-ci aura comme premier (seul ?) client celle qu’ils viennent précisément de quitter.
On comprend mieux ainsi pourquoi toute analyse architecturale tentant, par exemple, de démontrer l’absurdité de payer un fournisseur proposant une technologie de chaînes de blocs à localisation centralisée et contribution unique sera peine perdue si son dirigeant possède des liens très étroits avec les « bonnes » personnes de la société cliente, et l’auteur de cette analyse sera logiquement gentiment prié de la mettre sous le boisseau.
Ce style d’architecture possède des variantes : l’Architecture sur Canapé
et l’Architecture par Corruption.
L’Architecture orientée Éditeur / Intégrateur (AoE)
Architecture que l’on pourrait également appeler l’Architecture par Délégation. Pour intégrer un nouveau logiciel dans un S.I., son éditeur va naturellement être sollicité (soit directement soit indirectement, via un intégrateur). Et celui-ci a naturellement envie que cette intégration soit la plus rapide possible pour que la vente lui soit la plus rentable possible. Il peut donc vouloir limiter ses risques en poussant une architecture qu’il connaît, des moyens de communication qu’il maîtrise, indépendamment du style d’architecture existant ou souhaité de son client ni de son besoin.
Si les critères d’intégration n’ont pas été pris en compte en amont, si l’équipe interne n’est pas suffisamment ferme, suffisamment volontaire et informée, ou tout simplement si une architecture S.I. n’a pas été conçue, alors chaque éditeur, selon son historique, son niveau de maturité sur telle ou telle technologie ou encore sa stratégie, va orienter localement le S.I. dans une certaine direction. Ici une communication par API REST, là par échanges de fichiers. Ici l’utilisation d’un logiciel médiateur, là une communication point-à-point, là encore l’installation d’un orchestrateur de l’éditeur, et là enfin une transmission de données par courrier électronique (les variantes sont quasi infinies).
Quand on ne sait pas où l’on veut aller, d’autres prendront la barre.
Ce type d’architecture est apparemment très bénéfique à chaque projet, car ainsi certains risques ont été maîtrisés et la probabilité de finir dans le temps et dans le budget imparti est augmentée. Voilà deux critères mesurables, et donc des indicateurs systématiquement suivis par la chefferie de projet. Mais voilà, un projet n’est pas isolé — c’est même le principe de travailler dans et pour un système, donc une optimisation locale peut très bien aboutir à une dégradation globale.
En plus de l’éditeur ou intégrateur, l’une des sources de ce style d’architecture est à trouver dans l’organisation : ceux qui participent à la phase de changement sont rarement ceux qui participent à celle du maintien en condition opérationnelle, autrement dit ceux qui « optimisent » durant un temps fini ne sont pas ceux qui vont en subir les conséquences sur le temps long de l’utilisation (pour ceux qui décident de le — laisser se — mettre en place, ce style d’architecture est bénéfique sur le court terme et indolore sur le long terme ; pour ceux qui en héritent, en revanche…).
Si les caractéristiques précédemment décrites de ce style d’architecture de S.I. le font ressembler à un paquet de confettis, il peut aussi évoluer selon une même logique sur un large périmètre lorsqu’un unique éditeur participe à tout un sous-ensemble du S.I. (c’est typiquement le cas pour les GAFAM [6] qui proposent des outils intégrés pour stocker, diffuser, traiter et représenter des données). Dans ce cas, il pourra orienter l’architecture d’une partie significative — si elle n'est pas structurante — du S.I. de ses clients simplement en changeant sa politique de licences. Ici, la perte de souveraineté de la société sur son S.I. est à peu près totale, car ce dernier appartient, de facto, à un éditeur : d’une part, il a connaissance de tout le savoir de la société (il stocke ses fichiers, données structurées et courriers électroniques) et, d’autre part, il peut piloter son patrimoine logiciel et ses choix technologiques.
Deux facteurs contribuent à ne pas sortir de cette dépendance : tout d’abord une question d’égo, car en changer reviendrait à reconnaître qu’une décision stratégique, prise à très haut niveau et impliquant des sommes colossales, a été mauvaise, et ensuite, car le coût de la prise d’indépendance est considéré comme bien supérieur au coût du maintien de l’inféodation (d’année en année, le coût de la D.S.I. doit augmenter, et/ou la part prise par l’éditeur sur le budget de la D.S.I. doit grossir ; la vache à lait n’a d’autre choix que de se laisser traire — jusqu’à ce qu’une certaine limite soit franchie, et alors des décideurs soient changés).
Tant qu’il n’y a pas de changement de décideur, il n’y a pas de changement de décision.
[6] Mais ils sont loin d’être les seuls ; citons simplement SAP.
L’influence de la SMARTabilité sur le S.I.
Coût, Délai, Qualité, Pérennité : sur ces quatre caractéristiques, 2 sont mesurables, 2 autres ne le sont pas. 2 sont faciles à définir, 2 autres sont ambiguës. 2 sont sensibles uniquement à court terme (sauf cas extrêmes), 2 sont sensibles à moyen / long terme : lesquelles seront suivies par des KPI, d'après vous ? Pour un tableau de bord, ce qui ne se mesure pas n’existe pas ; ça vous énerve ?
Deuxième aparté, qui prolonge d’ailleurs celui de la première partie, sur la non-prise en compte de la qualité et la pérennité dans la construction d’un S.I. En effet, n’étant pas mesurables, ces caractéristiques ne sont par conséquent jamais dans les objectifs « SMART » de l’Entretien Individuel de Performance (E.I.P.) annuel d’un quelconque salarié. Typiquement, les chefs de projets s’y intéresseront diversement, selon les appétences des uns et des autres, alors que les coûts et les délais des projets seront observés par tous (et pourront même permettre de comparer les chefs de projets entre eux).
Par ailleurs, comment espérer avoir des actions collectives cohérentes quand les objectifs à atteindre ne sont tous qu’individuels ? Quelle société rend public (en interne) l’ensemble des objectifs individuels qu’elle donne ? Quelle société s’assure de la cohérence de ces objectifs, s’assure qu’ils n’entrent pas en conflit les uns les autres (et l’assure à ses membres) ? Quelle société, enfin, a mis en place des Entretiens Collectifs de Performance ?
L’Architecture Syncrétique (AS)
Finissons en apothéose, car tous ces styles d’architectures ne sont pas mutuellement exclusifs ! Il est donc parfaitement possible de voir une combinatoire de tous les styles d’architectures précédemment décrits dans un seul et même S.I.
Conclusion
Dans un S.I., il y a des décisions prises, parfois bien obscures pour un architecte S.I. se voulant orthodoxe. Et ce bref panorama de styles d’architecture rencontrés dans les sociétés devrait rendre modeste tout architecte du S.I. attitré. D’une part, il importe avant toute chose de voir la poutre qui est dans son œil, car sous couvert de promouvoir une architecture orthodoxe, il met probablement lui-même en place, sans s’en rendre compte, une architecture catholique. D’autre part, il n’a pas la main — et il ne l’aura jamais — sur les facteurs structurants d’un système d’information : politique RH, contrôle de gestion, structure organisationnelle, choix de nouveaux salariés, biais psychologiques, principes culturels ; tout cela est décidé ou existe sans lui.
Et, vis-à-vis de ces enjeux, pourtant incontournables comme nous l’avons vu, pour qui souhaite maîtriser la complexité d’un S.I., aucune méthode, aucun cadre d’urbanisation du S.I., ne lui sera d’aucune utilité, d’aucun secours, car aucun ne les traite de front (et à plus forte raison, aucun logiciel ni aucun langage de modélisation). En outre, appartenant le plus souvent à une organisation transverse dédiée, il n’a par conséquent à sa disposition ni carotte ni bâton vis-à-vis des directeurs, chefs de projets, développeurs, intégrateurs, etc., qui font du S.I. ce qu’il est. Tout est-il pourtant perdu pour l’esthète ? Non, mais c’est un autre sujet.
Chers confrères architectes ou urbanistes du S.I., si ce que je vous ai proposé vous parle, je vous invite maintenant à amender, enrichir ou illustrer (par de croustillantes anecdotes) les architectures présentées ici en commentaire.
|
|
Emmanuel Reynaud
|
"La beauté, c'est l'harmonie du hasard et du bien.
Sachons faire confiance à la jeunesse pour conserver à la vie sa valeur suprême."
Simone Veil
Compléments de lecture
- Démarche d’urbanisation du SI : les questions techniques, organisationnelles, voire existentielles
- Comment modéliser les niveaux (stratégique, tactique...) de l’Architecture d’Entreprise ?
- TOGAF 10, quelle méthodologie d’architecture de sécurité et de gestion des risques ?
- Exemple de méthode d’Architecture d’Entreprise d’un grand cabinet de conseil : EAM Enterprise Architecture Management de McKinsey
- Quel outil ArchiMate pour modéliser vos architectures d’entreprise sources et cibles, évaluer les écarts, analyser les impacts et élaborer des trajectoires de transformation ? Obeo SmartEA S.1 Ep.1
- Comment consolider un référentiel centralisé TOGAF rassemblant les autres référentiels Stratégie, Métier, Applications, Infrastructure… ? Obeo SmartEA S.1 Ep.2
- Architecture d'Entreprise augmentée, quelle influence de l’Intelligence Artificielle sur la gouvernance et la stratégie ?
- ChatGPT, l’outil idéal de réalisation de modèles pour l’Architecture d’Entreprise et l’Urbanisation du Système d’Information ?
- Comment générer par ChatGPT vos diagrammes ArchiMate gratuitement ?
La rédaction tient à souligner que la plateforme urbanisation-si.com est indépendante de toute organisation et son fonctionnement repose entièrement sur des bénévoles passionnés de pédagogie et désirant partager leur expérience. Vous ne verrez jamais de publicités sur notre plateforme.
Bien que nous encourageons l’open source, il peut nous arriver d’utiliser des logiciels commerciaux qui nous sont gracieusement prêtés sous aucune condition et nous ne touchons aucune rémunération de qui que ce soit.
Les architectures catholiques du S.I. (1/2)
Les architectes et urbanistes du S.I. savent qu’il existe différents styles d’architecture possibles pour un S.I. : architecture orientée (micro) services, architecture hexagonale, architecture orientée événement, la conception par domaine, etc. Chacun va avoir son architecture privilégiée, son style architectural.
Il s’agit là des architectures orthodoxes [1], mais tout cela n’est que la partie émergée des architectures existantes en société. Il en existe en fait beaucoup d’autres, jamais identifiées, car jamais nommées, mais pourtant très présentes et très vivaces : les architectures catholiques [2] (je les tiens pour beaucoup plus répandues que les architectures orthodoxes). Je vous propose ici de combler ce manque en en décrivant quelques-unes.

Illustration créée par ChatGPT - DALL-E pour cet article
[1] Orthodoxe : « Qui est conforme à la doctrine officiellement reçue » « Qui s’accorde avec l’opinion couramment admise » (source : Dictionnaire de l’Académie française, 9e édition)
[2] Catholique : « universel » (source : Dictionnaire de l’Académie française, 9e édition)
L’Architecture orientée C.V. (AoCV)
Dans le S.I. où elle est appliquée, cette architecture va faire sourdre de manière isolée des technologies et façons de faire dans la tendance du moment.
Car ce S.I. est vu par ceux qui le font évoluer comme un moyen pour leur permettre d’ajouter des mots-clefs rémunérateurs à leur C.V.
Les composants technologiques à intégrer sont forcément nouveaux dans le S.I., puisqu’ils ont été choisis pour cela : ils sont à la mode, ils sont vendeurs.
On ne s’étonnera pas alors, une fois terminé le projet qui leur a permis de mettre en place ces technologies à la mode, de voir les personnes responsables de ces évolutions partir de leur société (le projet se terminera, car il doit se terminer coûte que coûte, contre toute évidence, non pas seulement à cause du biais d’engagement, mais aussi pour pouvoir « justifier d’une expérience réussie »). En effet, c’était bien là tout l’objectif de ceux qui ont fait les choix d’architecture en question.
Et puis, cela permet de ne pas avoir à assumer ces choix sur le long terme, laissant ainsi aux anciens collègues le soin de gérer une évolution faiblement documentée (pourquoi réaliser une documentation quand on sait dès le début que l’on ne nous la demandera jamais, qu’on ne la lira jamais, et que tout le travail effectué ne l’est que pour soi, et non pour la collectivité ?). Cette évolution est également sans cohérence avec le reste du S.I., donc en rupture avec les habitudes de ceux qui doivent le maintenir en bon état, d’autant qu’elle est facilement branlante, n’étant pas maîtrisée par ceux qui l’ont mise en place.
Ainsi vont fleurir les lacs de données là où une base de données relationnelle aurait suffi, ou encore des conteneurs et orchestrateurs de conteneurs, avec un bus d’événements, là où un développement 3 tiers tristement classique aurait parfaitement convenu, etc.
Le S.I. est (localement) vu comme un bac à sable, dont des enseignements seront tirés… pour le prochain employeur. Cette considération du S.I. comme terrain de jeux est d’ailleurs partagée par un autre style d’architecture assez proche, l’Architecture Orientée Plaisir, qui sera décrite plus après.
Il existe une variante de cette architecture, l’architecture ambitieuse, réalisée à coup de « projets ambitieux ». La montagne accouche alors d’une souris borgne et boiteuse, mais très gourmande.
L’Architecture orientée Histoire (AoH)
Cas symétrique du précédent, ici l’architecture dépend directement du passé de celui qui l'a mise en place. Celui-ci a à cœur de reproduire dans sa nouvelle société ce qu’il a déjà connu dans la précédente (autant que possible) : il ne veut pas de surprise, il sait déjà que cela marche, peut-être même a-t-il été embauché pour cela (et sait-il d’ailleurs faire autre chose ?).
Le contexte a changé, les capacités et les compétences de la D.S.I. présente (et les hommes qui la composent ou interagissent avec eux) ne sont pas les mêmes que celles de la D.S.I. précédente. Tout cela n’importe pas. On croit jouer la sécurité, alors que ce faisant on prend un risque (non identifié, non contrôlé). En fait, on a surtout envie de ne pas réfléchir.
Variante de ce style d’architecture, l’Architecture orientée Grand Éditeur, selon le fameux adage « aucun D.S.I. n’a jamais été viré pour avoir installé de l’IBM / du Microsoft / etc. ».
La société malade du contrôle de gestion
Faisons un petit aparté ici pour noter que ces deux premiers styles d’architecture S.I. ont ceci de commun qu’ils ne sont guidés que par des intérêts personnels, soit pour sortir, soit pour entrer dans une nouvelle société. Ceci étant une conséquence directe de la politique RH généralisée de quasi-non-augmentation de salaire (quant au plan de carrière…). La tension ainsi créée entre l’intérêt général et l’intérêt individuel entraîne logiquement une stratégie de contournement toute trouvée : si ma société ne m’augmente pas, alors je change de société avec une augmentation de salaire à la clef [3].
On ne saurait blâmer cette adaptation, mais il est à déplorer que les conséquences de décisions de contrôleurs de gestion et responsables RH (voire de responsables plus hauts placés) concernant la « masse salariale » et le « centre de coûts » que représente la D.S.I., sous couvert d’optimisations mesurables, entraînent des dégradations invisibles de qualité et de pérennité.
[3] C’est un peu comme si des opérateurs téléphoniques ne proposaient de promotions qu’aux nouveaux clients : forcément, cela pousse à aller voir ailleurs.
L’Architecture orientée Organisation (AoO)
Impossible de ne pas la mentionner, c’est la loi de Conway :
« Les organisations qui définissent des systèmes sont contraintes de les reproduire sous des conceptions qui sont des copies de la structure de communication de leur organisation. » [4]
Je ne m’étendrai pas sur cette loi déjà bien connue, qui a donc tout naturellement sa déclinaison au niveau du système… d’information. On obtient ainsi les fameux « silos » absolument partout dans la société, D.S.I. incluse, chaque directeur souhaitant gérer son budget comme il l’entend (comprendre : sans avoir à en discuter avec un quelconque voisin). D’où la dissémination de développeurs, de chefs de projets, d’acheteurs partout, n’importe où dans l’organisation, pour tendre vers un S.I. composé de plein de sous-S.I., à savoir un mini-S.I. par directeur. Résultat cocasse : dans une société, on pourra ainsi trouver plus de développeurs en dehors de sa D.S.I. qu’à l’intérieur.
Notons l’effet de l’égo qui participe à ce phénomène. Pour un responsable d’équipe, il est valorisant de gérer le plus grand nombre de subordonnés possible, mais également le plus grand budget possible. C’est comme cela que l’on monte dans le classement des « managers ».
Sans méthode ni volonté forte au plus haut niveau, la gestion de la complexité d’un S.I. est réalisée très simplement : il suffit de ne pas se parler. Chaque sous-organisation s’isole dès que possible et autant que possible. Au final, le système est cassé. Il en résulte plusieurs sous-systèmes isolés et, le tout ne pouvant alors être supérieur à leur somme, il n’y a pas de propriété émergente globale (raison d’être de « faire système »).
En particulier, toute organisation à vocation transverse, autrement dit cherchant à mettre du liant avec les autres, doit être, précisément pour cette raison, disqualifiée par toutes les autres par tous les prétextes possibles : trop chère, pas assez compétente, manquant de pragmatisme, pas assez réactive, trop lointaine, etc. Les intérêts étant pour une fois convergents, le consensus se fait pour crier haro sur le baudet.
Effet annexe de cette architecture : c’est le bonheur pour les éditeurs qui peuvent proposer un logiciel plusieurs fois à la même société. Son outil n’a-t-il pas été retenu dans un appel d’offres d’une société ? Il pourra toujours retenter sa chance avec cette même société pour outiller le même périmètre logique à l’occasion d’un autre appel d’offres, mais cette fois-ci passé par une autre partie de son organisation. Son outil a-t-il été retenu dans un appel d’offres ? Il pourra tout aussi bien retenter sa chance dans un autre appel d’offres de la même société, avec la garantie qu’il n’y aura pas de renégociation tarifaire par le client (les clients, de facto) pour bénéficier d’un effet de volume.
Au final, gabegie financière et faiblesse capacitaire.
[4] Melvin Conway, How Do Committees Invent?
L’Architecture orientée Plaisir (AoP)
Les informaticiens sont — assez logiquement — des technophiles. Et nombreux gardent, et c’est heureux, une soif de savoir, un esprit de découverte, qui est forcément nourri par une discipline qui ne cesse d’évoluer à un rythme rapide. Ainsi, certains, qui vont être amenés à pouvoir choisir une technologie, vont succomber à la tentation d’en choisir une, parce qu’elle leur plaît, parce qu’ils ne la connaissent pas (encore), parce qu’elle va leur proposer un défi technologique, parce qu’elle va leur permettre d’explorer de nouvelles façons de faire, d’étancher un temps leur soif de savoir et de savoir-faire. Un expert d’un domaine informatique trouvera toujours une évolution de son champ de connaissance et une évolution des — forcément nombreux — domaines connexes à celui-ci.
Cela peut expliquer pourquoi on pourra observer dans un S.I. un foisonnement de technologies plus ou moins exotiques pour répondre de diverses manières à une même question qui se pose plusieurs fois - et qui, donc, ne devrait plus se poser - (plusieurs technologies de serveurs de bases de données relationnelles, plusieurs mécanismes d’échanges d’un même type de données…).
L’informatique devient alors un jouet (au lieu d’être un outil), une fin en soi (au lieu d’être un moyen), et le S.I. se transforme en un terrain de jeux.
À la décharge de ceux qui mettent en place une telle architecture, il faut dire que nous vivons dans une culture qui prône la nouveauté comme une vertu : le temps n’existe plus, puisque nous sommes dans un perpétuel présent, la dernière nouveauté faisant table rase du passé (c’est tout du moins sa promesse). « Le changement, c’est maintenant », puisque avant et plus tard n’existent pas, le changement les ayant fait disparaître. Le changement fait le présent et nous y enferme ; en fait, ce slogan est en creux une définition : maintenant est le changement. Et l’informatique est un terreau particulièrement fertile pour illustrer, encourager cette idéologie : on ne compte plus les « innovations de rupture », les technologies « disruptives ».
Cependant, si, le nez sur le guidon, seul le présent semble subsister, en prenant du recul, la perception est toute autre. Paradoxalement, c’est en fait dans un S.I. où les changements sont les plus fréquents que l’écoulement du temps est le plus visible. En effet, les technologies s’ajoutant sans complètement se remplacer, on peut voir des strates technologiques se superposer pour raconter, comme des strates géologiques, son histoire.
Rappelons aussi, à toutes fins utiles, qu’une nouveauté a émergé dans un certain contexte d’emploi, et n’est pas forcément bénéfique dans un autre. Et que, outre sa pertinence, on ne sait rien de sa pérennité (notion cardinale pour un architecte). Enfin, ce qui est vieux n’est pas forcément obsolète. Une technologie « ancienne » toujours utilisée a le bon goût d’être éprouvée, et ses capacités comme ses limites sont connues et largement documentées. Son utilisation dans son cadre correspondant sera ennuyeusement sûre et n’apportera aucune gloire, aucun frisson, tout au plus la satisfaction d’avoir simplement servi les utilisateurs du S.I. (mais n’est-ce pas là le suprême sens du service de tout informaticien ?).
Nous n’avons ici passé en revue que quelques-unes des architectures catholiques du S.I. Il nous en reste d’autres à dévoiler, que nous vous proposerons dans une seconde partie.
|
|
Emmanuel Reynaud
|
"Les erreurs ne se regrettent pas, elles s'assument.
La peur ne se fuit pas, elle se surmonte.
L'amour ne se crie pas, il se prouve."
Simone Veil
Compléments de lecture
- L’Architecture Micro-Services expliquée à ma fille
- Inconvénients de l'Architecture Micro-Services
- Orchestration des micro-services avec BPMN
- Les couches de l'Architecture Microservices et la méthode de conception DDD (Domain Driven Design)
- Architecture Hexagonale, exemple de mise en pratique de la méthode DDD Domain Driven Design
- Un problème cornélien de l’EDA, Event Driven Architecture, est de s’assurer de l’exactitude sémantique de livraison d’un message, Kafka l’aurait-il résolu ?
- Comment éviter la loi de Conway et faciliter ainsi l’agilité avec l’approche Micro-Services ?
La rédaction tient à souligner que la plateforme urbanisation-si.com est indépendante de toute organisation et son fonctionnement repose entièrement sur des bénévoles passionnés de pédagogie et désirant partager leur expérience. Vous ne verrez jamais de publicités sur notre plateforme.
Bien que nous encourageons l’open source, il peut nous arriver d’utiliser des logiciels commerciaux qui nous sont gracieusement prêtés sous aucune condition et nous ne touchons aucune rémunération de qui que ce soit.
Moore, Murphy, Pareto, Maslow, Asimov… pionniers, voire visionnaires : les lois qui portent leurs noms s’appliquent-elles encore à l’informatique ?
Codex Informatica : les lois qui s'appliquent à l'informatique
Après avoir publié de nombreux articles consacrés à différentes lois qui s'appliquent à l'informatique, Gabriel KEPEKLIAN a constitué, entre 2006 et 2013, une liste de 31 lois classées par noms de leurs auteurs : le Codex Informatica. Il s'agit sans doute de la liste francophone la plus complète.

Extrait d'un tableau de René Réno
Il faut prendre le terme informatique au sens large. Plusieurs lois s'appliquent notamment aux projets informatiques, mais également aux projets tout court, dans d'autres secteurs d'activité. Par exemple, qui n'a pas expérimenté la fameuse loi de Murphy en dehors du secteur informatique ?
Ces lois-là n'ont rien d'obligatoire. Mais on constate a posteriori et de façon empirique qu'elles se sont appliquées naturellement, souvent au détriment du bon avancement d'un projet (délai et coût dépassés, qualité médiocre). Connaitre ces lois permet parfois d'anticiper, en atténuant leurs conséquences souvent néfastes notamment.
Utilisateurs réguliers de ce Codex Informatica, nous souhaitions y ajouter d'autres lois qui n'y figurent pas encore (notamment à la suite de l'avènement de l'Architecture Micro-Services). Avec l'autorisation de son auteur, voici donc ce Codex Informatica, qui sera enrichi au fil des mois à venir. Nous n'avons pas la prétention d'obtenir une liste exhaustive, mais si vous connaissez d'autres lois qui s'appliquent à l'informatique, n'hésitez surtout pas à poster un commentaire, afin de nous inciter à les ajouter à ce florilège.
|
|
Thierry BIARD |
« Les tentatives de création de machines pensantes nous seront d'une grande aide pour découvrir comment nous pensons nous-mêmes. » Alan Turing
Loi d’Amara : de la mauvaise saisie de la temporalité
Loi d'Amdahl : gain de performance
Loi d'Asimov : les 3 lois de la robotique
Loi de Bell : classes d’ordinateur
Loi de Bezos : la longue traîne
Loi de Brooks : retard sur projet logiciel
Loi de Clarke : les 3 conditions possibles de l’innovation
Loi de Cole : conservation de l’intelligence
Loi de Conway : comment l'éviter et faciliter ainsi l’agilité avec l’approche Micro-Services ?
Loi de Fitts : la durée du mouvement
Loi de Freedman : facilité de programmation
Loi de Gabor : technologie et progrès
Loi de Gates : inertie logicielle
Loi de Gilder : dépassement de bande
Loi de Godwin : débat et discrédit
Lois de Kranzberg : la technologie
Loi de Krug : ne me faites pas réfléchir !
Hiérarchie de Maslow : Web 2.0, un web plus motivant
Loi de Mayfield : participation
Loi de Metcalfe : réseau, web social
Loi de Milgram : profondeur des relations
Loi de Moore : doublement programmé
Loi de Murphy : quand ça va mal…
Loi de Nielsen : vitesse de connexion
Loi de Parkinson : du travail comme un gaz parfait
Loi de Reed : réseau, web social
Loi des rétroactions positives (Wiener)
Loi de Roberts : rapport Performance / Prix
Loi de Shannon : notion d’entropie
Loi de Wirth : vitesse relative du progrès
Comment générer par ChatGPT vos diagrammes ArchiMate gratuitement ?
Comment ChatGPT peut-il aider l’Architecte d’Entreprise ? ChatGPT est un apprenant surdoué : si on lui donne un modèle, il peut ensuite l’adapter à d’autres contextes. Dans cet article très pragmatique, nous allons montrer comment ChatGPT peut créer des vues ArchiMate, mais aussi proposer de nouvelles perspectives auxquelles on ne pense pas forcément. Pour vous prouver que cela fonctionne bien, les résultats générés sont importés dans deux outils Archi et Obeo SmartEA. Voici la méthode que nous avons appliquée.

Illustration créée par Copilot gratuit utilisant DALL-E 3 pour cet article
Objectif :
Générer les vues ArchiMate "Stakeholders & Concerns" et "Drivers & Business Goals" pour l’Architecture d’Entreprise d’un groupe d’assurances désirant intégrer l’IA
Les IA génératives prennent de plus en plus de place dans notre vie professionnelle ou personnelle. Par exemple, les avocats, les juristes, mais aussi les professeurs ou les étudiants ont un tout nouvel assistant pour les aider dans l’analyse de dossiers, pour actualiser leurs cours ou pour faire leurs devoirs, voire carrément les aider à concevoir leur thèse.
Qu’en est-il des architectes d’entreprise ? ChatGPT, peut-il aider à la réalisation de modèles ArchiMate qui sont des tâches chronophages et répétitives ? Peut-il donner de nouvelles idées, de nouvelles pistes d’investigation dans le domaine de la transformation numérique ?
Pour cette démonstration, nous allons demander à ChatGPT-4o (omni) en version gratuite de générer la vue des parties prenantes et de leurs préoccupations (Stakeholders & Concerns) dans le cadre de l’Architecture d’Entreprise (AE) d’un groupe d’assurance désirant intégrer l’IA.
Nous vérifierons que notre modèle est correct, en lui demandant de générer la suite avec la vue des objectifs pour y contribuer (Drivers & Business Goals).
Générer des diagrammes, c’est bien, mais les intégrer dans un référentiel collaboratif, c’est encore mieux
Notre article "Texte vers UML et autres outils de "diagrammes en tant que code" - Le moyen le plus rapide de créer vos modèles ?" a remporté un franc succès, car il permet à ChatGPT de générer n’importe quel diagramme dans la quasi-totalité des langages de modélisation. Voir aussi : ChatGPT, l’outil idéal de réalisation de modèles pour l’Architecture d’Entreprise (AE) et l’Urbanisation du Système d’Information ?.
Un des concepts de base de l’AE est de gérer un référentiel partagé regroupant tous les artefacts représentant l’entreprise. Mais si l’on peut demander à ChatGPT de générer des diagrammes, au format PlantUML par exemple, malheureusement ceux-ci ne peuvent être repris dans un véritable référentiel géré par les outils d’AE.
On sait maintenant à quoi sert
le format Open Group ArchiMate XML

ArchiMate® Model Exchange File Format for the ArchiMate 3.1/3.2 Modeling Language
https://www.opengroup.org/xsd/archimate/
L'interopérabilité est rendue possible grâce au format Open Group ArchiMate, particulièrement verbeux et abscons. La technologie retenue est XML, qui permet de créer sa propre langue avec sa grammaire XSD. Les grandes entreprises l'utilisent entre autres pour définir un langage pivot commun à tous leurs domaines métiers. Si ce métalangage présente une infinité de possibilités, son défaut majeur reste sa complexité et sa verbosité. Mais justement, c’est le terrain de prédilection de ChatGPT. En utilisant les informations qu’on lui a fournies, grâce à ses capacités d’auto-amélioration, d’apprentissage autonome et de prises de décisions indépendantes, il peut appliquer des templates et générer des milliers de lignes XML en respectant le standard de l’Open Group.
Créer un template XML minimal et réutilisable,
pour que ChatGPT comprenne ce que vous attendez de lui
Template XML obtenu à partir de la vue “Stakeholder & Concerns” d'ArchiSurance, l’étude de cas standard de l’Open Group
ChatGPT ne donne pas immédiatement le code XML exhaustif et sans défaut. Il faut lui fournir un modèle générique (téléchargez notre template XML pour la génération de diagrammes ArchiMate par ChatGPT), qu’il adaptera automatiquement en fonction du contexte que vous lui fournirez.
Dans notre exemple, nous avons choisi d’obtenir le template XML à partir de la vue “Stakeholder & Concerns” d'ArchiSurance, l’étude de cas standard de l’Open Group. Mais n’importe quel autre diagramme correspondant à votre problématique conviendra, à condition qu’il soit dans un outil permettant l’export au format Open Group ArchiMate XML.
ArchiSurance version Open Group
Vous pouvez récupérer le cas d'usage sur le site de l’Open Group :
ArchiSurance version Jean-Baptiste Sarrodie (Archi)
Autre solution, vous pouvez le télécharger sur la plateforme GitHub de Jean-Baptiste Sarrodie, le créateur d'Archi (voir nos articles en compléments de lecture) :
ArchiSurance version Obeo SmartEA
Comme nous avions testé récemment Obeo SmartEA (voir nos articles en compléments de lecture) , c'est la solution la plus immédiate qui se présentait à nous.
Voir en annexe -1- la procédure détaillée pour récupérer ArchiSurance au format XML de l'Open Group.

L’outil Obeo SmartEA intègre entièrement l’étude de cas ArchiSurance. A lire >
Extraire le diagramme Stakeholder & Concerns avec Archi
Par commodité, nous importons le volumineux fichier XML totalisant la bagatelle de 15 164 lignes dans Archi.
Voir en annexe -2- la procédure d'importation d'ArchiSurance dans Archi.
Pour extraire uniquement la partie qui nous intéresse, c'est-à-dire le diagramme Stakeholder & Concerns, nous créons un nouveau projet dans Archi, dans lequel nous copions le diagramme.
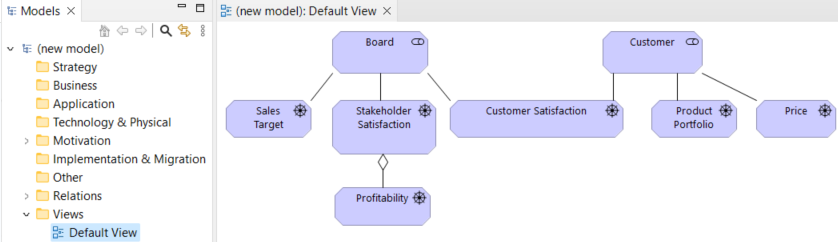
Copie de la vue Stakeholder & Concerns dans un nouveau projet Archi, servant juste à générer le XML
Pour avoir le XML correspondant, il suffit d'exporter le diagramme à partir d'Archi.
Voir en annexe -2- la procédure d'exportation du diagramme Stakeholders & Concerns à partir d'Archi.
Retoucher simplement le template XML
pour ne garder que le strict nécessaire
Rassurez-vous, c’est à la portée d’un néophyte et ça ne demande que 5 minutes.
L’objectif est de constituer une ossature générique contenant les principales balises : element, relationship, node et connection.
Téléchargez notre modèle XML de génération de diagrammes ArchiMate par chatGPT
Template au format Open Group ArchiMate XML, à fournir à ChatGPT pour qu'il sache
dans quel format il doit générer le diagramme correspondant à votre demande
Demander à ChatGPT de vous donner
des propositions d’artefacts et leurs relations ArchiMate
En détaillant le plus précisément possible votre contexte, vous pouvez demander à ChatGPT de vous indiquer les artefacts ArchiMate (Stakeholders & Drivers), avec leurs relations et leurs descriptions. Sa réponse constitue une base de travail, qu’il faut analyser, vérifier, modifier en ajoutant vos propres artefacts.
Demander à ChatGPT de générer le code XML
avec vos éléments ArchiMate en suivant votre template
Question posée à ChatGPT (prompt)
ChatGPT conserve en mémoire tous les échanges d’une conversation. Si vous validez les artefacts qu’il vous a proposés, dans le prompt, il suffit de lui dire de les reprendre, de générer la vue ArchiMate correspondante en appliquant le modèle XML qu'on lui fournit. Il faudra alors copier/coller le contenu du modèle dans le prompt. ChatGPT peut s’arrêter en cours de génération, il suffit alors de lui dire de continuer et ChatGPT reprendra là où il en est resté.
Voir en annexe -6- le prompt pour la génération XML du diagramme ArchiMate.
La réponse de ChatGPT : télécharger le diagramme ArchiMate Stakeholder & Concerns pour un groupe d'assurance désirant intégrer l'IA
Génération par ChatGPT du diagramme ArchiMate Stakeholder & Concerns
pour un groupe d'assurance désirant intégrer l'IA
Disponible aussi à l'annexe -7-.
Importation du XML généré dans Archi
Nous importons dans Archi (voir en annexe -8-) le fichier XML contenant la copie de la réponse de ChatGPT.
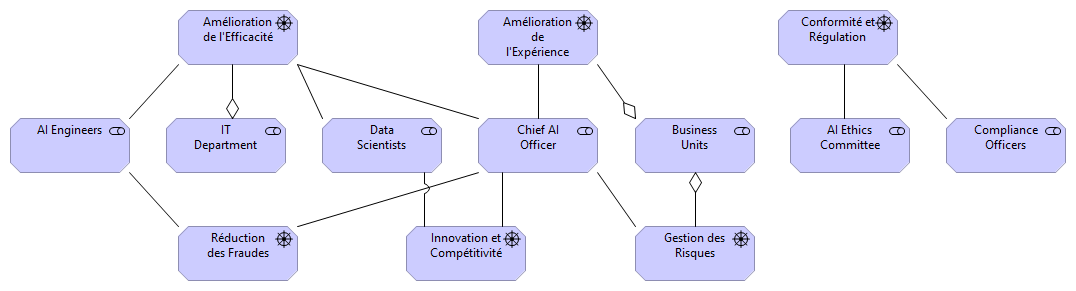
Vue Stakeholders & Concerns d'un groupe d'assurance intégrant l'IA,
générée par ChatGPT, représentée dans Archi
Importation du XML généré dans Obeo SmartEA
Nous importons dans Obeo SmartEA (voir en annexe -9-) le fichier XML contenant la copie de la réponse de ChatGPT. L’outil propose une réorganisation automatique, on n’aura même pas besoin de redisposer les éléments pour rendre le modèle plus lisible.
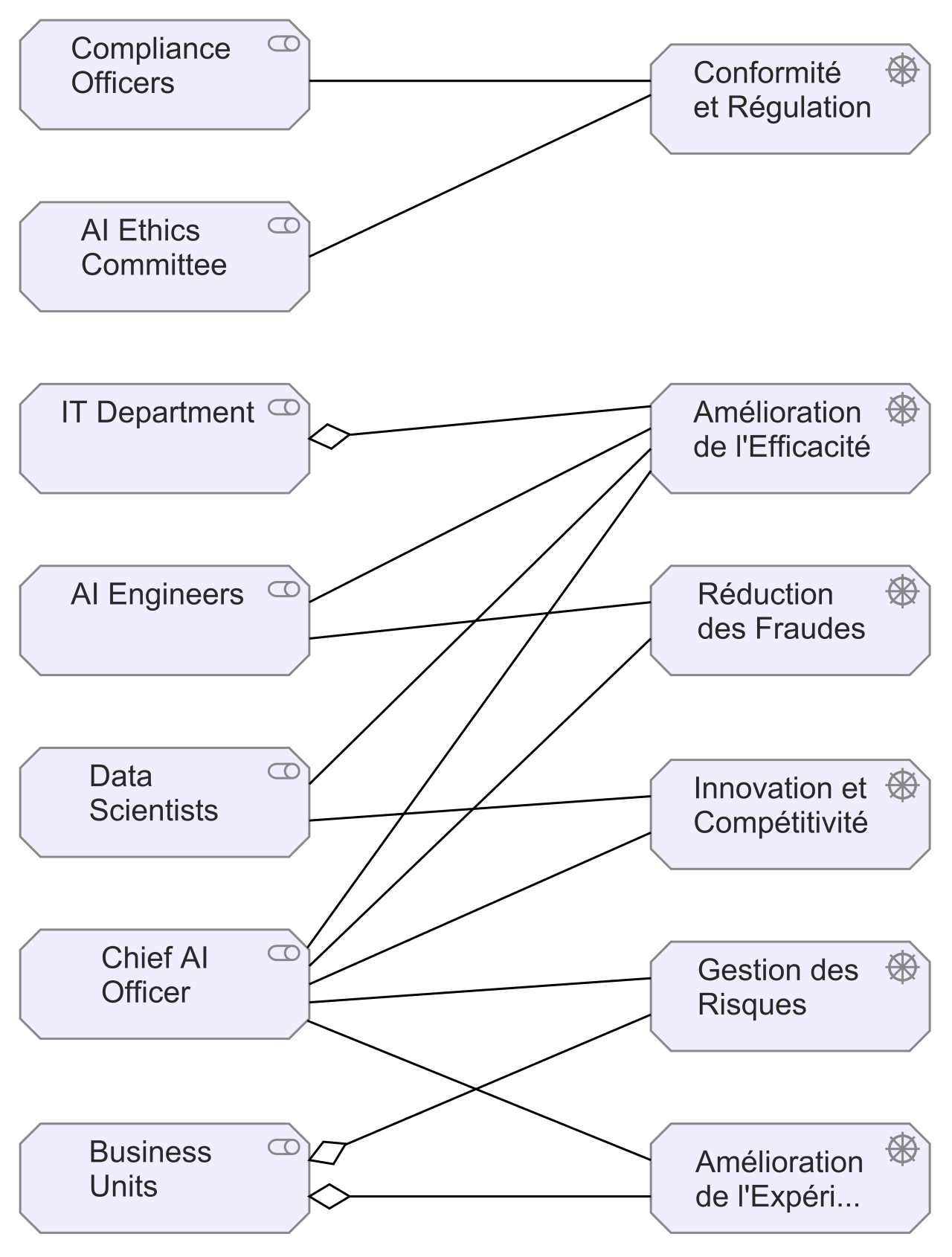
Vue Stakeholders & Concerns d'un groupe d'assurance intégrant l'IA,
générée par ChatGPT, représentée dans Obeo SmartEA
Pour vérifier que ChatGPT est capable d’adapter notre template XML, lui demander de générer le point de vue Drivers & Business Goals dans le contexte précédent
Vérifier, c’est douter, mais pour vous convaincre que ChatGPT peut vous aider dans l’élaboration de vos vues ArchiMate, nous allons utiliser notre modèle XML pour une tout autre vue.
Nous voulons que ChatGPT génère la vue Drivers & Business Goals en prenant en compte notre contexte et la vue Stakeholders & Concerns qu’il vient de créer.
Télécharger le diagramme ArchiMate Drivers & Business Goals généré par ChatGPT grâce à notre modèle XML
Résultat de la génération par ChatGPT de la vue Driver & Business Goals, toujours dans le même contexte et sans modifier notre template XML
Pour l'obtenir, appliquer la même méthode que précédemment
- Un premier prompt pour avoir les Assessments (Évaluations), Goals (Objectifs) et Outcomes (Résultats) en relation avec les Drivers précédents, ainsi que leurs relations entre eux.
Voir en annexe -10- le détail du prompt et la réponse de ChatGPT. - Un deuxième prompt pour obtenir le code ArchiMate XML avec les éléments précédents, y compris leurs relations en suivant notre template XML inchangé. Le template XML généré précédemment est conservé et sera toujours réutilisé en l’état sans aucune modification, pour générer n’importe quel autre diagramme ArchiMate.
Voir en annexe -11- le détail du prompt et la réponse de ChatGPT.
- Voir en annexe 12 : Importation dans Archi et en annexe 13 : Importation dans Obeo SmartEA.
En contrôlant le résultat, on s’aperçoit que les relations de type “Influence” sont inversées. On demande simplement à ChatGPT d’inverser toutes les valeurs des attributs source et target pour les relations de type “Influence”.
Un prompt ChatGPT doit être contextualisé, explicité et très détaillé. En fait, comme si l’on demandait à un consultant de donner son avis sur un sujet.
Conclusion
Une bonne pratique de réalisation de diagrammes est de les réaliser sur une seule page, afin qu’il soit lisible et compréhensible pour les destinataires. Pour y arriver, le contexte doit être bien délimité et défini, ce qui facilite la tâche à ChatGPT. Par exemple, nous aurions pu, dans le premier prompt, spécifier que nous sommes limités à 4 ressources. ChatGPT aurait sans doute priorisé et n'aurait pas identifié 7 rôles différents de stakeholders.
A ce stade, il faut considérer ChatGPT comme un outil de traduction automatique par exemple. Il peut nous faire des propositions, nous donner des idées, c’est un super consultant qui connaît une infinité de cas d’usage. Comme un manager contrôlant le travail de son équipe, les résultats fournis par ChatGPT doivent être vérifiés. Dans notre cas, il est facile de voir la représentation graphique du code XML dans un outil d’AE supportant ArchiMate.
Si certains annoncent la disparition de nombreux métiers, celui d’architecte d’entreprise n’est pas près de disparaître, mais ne dit-on pas que nul n’est irremplaçable ?
|
|
Rhona Maxwel @rhona_helena |
“Mes principales inquiétudes ne sont pas liées à l'immédiat, mais au long terme. De façon presque inévitable, nous nous dirigeons vers des systèmes d'IA qui seront au moins aussi intelligents que nous, humains. Et il est certain que ces systèmes seront utilisés pour de bonnes comme de mauvaises choses. Par ailleurs, si l'IA devient plus intelligente que nous, nous courons le risque d'en perdre le contrôle.”
Yoshua Bengio
Annexe
Procédure détaillée pour que ChatGPT vous aide à créer vos vues ArchiMate (à adapter selon vos besoins)
- 1 -
Récupérer un exemple de vue ArchiMate
au format Open Group XML
Dans le cadre d’une évolution de votre Architecture d’Entreprise (AE), choisissez dans votre référentiel, parmi les vues existantes, celle correspondant le mieux à vos besoins et exportez-la au format Open Group ArchiMate XML. S’il s’agit de la création d’un nouveau référentiel, alors vous devrez juste créer une première vue, puis l’exporter en XML depuis votre outil.
Pour cet article, notre contexte sera l’étude de cas standard ArchiSurance de l’Open Group, présentant l’avantage d’être déjà intégrée dans les exemples d’Obeo SmartEA
Générer simplement dans votre outil le fichier XML de la vue choisie.
Dans Obeo SmartEA, le fichier XML s’obtient en exportant au format d’échange :
- Menu Plus > ArchiMate > Export au format d’échange
- 2 -
Créer votre template XML pour la génération
de modèles ArchiMate par ChatGPT
Importation d'ArchiSurance dans Archi
Le fichier exporté faisant plus de 15 000 lignes, il est inexploitable en l’état. Nous allons extraire la vue Stakeholders & Concerns et l’exporter pour obtenir quelques dizaines de lignes.
Pour y parvenir, nous importons le fichier dans Archi, qui est plus simple d’utilisation qu’Obeo SmartEA :
- Menu File > Import > Model From Open Exchange File
Une fois importé, nous devons isoler la vue voulue dans un nouveau projet, pour pouvoir l’exporter en XML. Pour accéder à la vue désirée dans Archi :
- Sélectionner Views > Folder > Stakeholders and Concerns > Sélectionner tous les éléments du diagramme et copier
Créer un nouveau projet :
- File > New > Empty Model > Views Default View > Coller
Exportation en XML de la vue Stakeholder & Concerns
Une fois la vue isolée dans un projet, vous pouvez l’exporter au format XML :
Sélectionner le nouveau projet > File > Export > Model to Open Exchange XML File > Désélectionner Include Folder > Save
Editer le fichier XML pour supprimer les styles et modifier les identifiants
Rassurez-vous, cette opération ne sera effectuée qu’une fois. Quand vous fournirez votre template XML à ChatGPT, il comprendra ce que vous attendez de lui et il s'adaptera automatiquement au nouveau contexte que vous lui exposerez.
Editer le fichier généré :
- Supprimer toutes les balises style.
- Modifier tous les id de manière à ce que ce soit plus lisible. Par ex., pour le stakeholder “Board”, modifier l’id ("id-95f1f282758140f1a795725fdd5c1afa") en ”Board-id”.
Le contenu du fichier XML est très simple et logique. Voici les explications des 6 principales balises :
- <model> : représente le modèle ArchiMate composé des balises <element> et <relationship>,
- <element> : les éléments qui sont typés comme par exemple Stakeholder, Driver…, nommés et identifiés,
- <relationship> : les relations pour lesquelles on doit indiquer un identifiant, leur type comme Association, Aggregation…, les éléments source et cible (target),
- <view> : la vue composée des balises <node> et <connection>,
- <node> : représente un élément présent sur la vue, avec ses coordonnées et l’identifiant référençant l’élément,
- <connection> : affiche dans la vue, la relation référencée, toujours en précisant l’élément source et la cible ce qui permet de montrer le sens de la connexion.
- <node> : représente un élément présent sur la vue, avec ses coordonnées et l’identifiant référençant l’élément,
Avec cet exemple de syntaxe, ChatGPT est capable de l’adapter à n’importe quel autre point de vue, pourvu qu’on lui précise les types d'artefacts et relations ou qu’on lui demande de nous en proposer, ce que nous faisons dans cet article.
Vous devez ne conserver que les configurations d’occurrence avec leurs relations les plus significatives de votre futur template XML, comme si vous vouliez créer un pattern réutilisable.
- 3 -
Télécharger notre template XML pour la génération
de diagrammes ArchiMate par ChatGPT
Vous pouvez télécharger notre template XML qui a servi à cet article :
Pour chacune de nos demandes de génération de diagrammes ArchiMate, nous fournissons
notre template XML à ChatGPT, pour qu'il comprenne ce que nous attendons de lui
- 4 -
Prompt ChatGPT pour avoir une proposition des parties prenantes et leurs préoccupations selon votre contexte
" Je suis architecte d'entreprise pour un groupe d'assurances. Je dois intégrer l'IA dans la transformation numérique de l'entreprise. Je veux concevoir un diagramme ArchiMate représentant la vue Stakeholders & Concerns. Je veux la liste et la description des nouveaux stakeholders et drivers spécifiques à l'IA. Je veux aussi leur relation de type association et agrégation. "
- 5 -
Réponse de ChatGPT :
liste des stakeholders, drivers et relations
Début de la réponse
" Pour intégrer l'IA dans la transformation numérique d'un groupe d'assurances, il est essentiel de bien identifier les nouveaux stakeholders (parties prenantes) et drivers (moteurs) spécifiques à l'IA, ainsi que leurs relations. Voici une proposition pour les stakeholders & drivers, ainsi que leur description et leurs relations.
Nouveaux Stakeholders spécifiques à l'IA
Chief AI Officer (CAIO)
Description: Responsable de la stratégie et de la mise en œuvre de l'IA au sein de l'entreprise.
Data Scientists
Description: Professionnels responsables de la conception, de la mise en œuvre et de la maintenance des modèles d'IA.
AI Ethics Committee
Description: Groupe chargé de veiller à ce que les initiatives d'IA respectent les normes éthiques et les régulations.
AI Engineers
Description: Ingénieurs spécialisés dans le développement et le déploiement des solutions d'IA.
Business Units
Description: Différentes unités de l'entreprise qui utilisent les solutions d'IA pour améliorer leurs processus et services.
IT Department
Description: Département responsable de l'infrastructure technologique supportant les initiatives d'IA.
Compliance Officers
Description: Professionnels chargés de s'assurer que les solutions d'IA respectent les réglementations en vigueur.
Nouveaux Drivers spécifiques à l'IA
Innovation et Compétitivité
Description: Utilisation de l'IA pour innover et maintenir un avantage compétitif sur le marché.
Amélioration de l'Efficacité
Description: Automatisation des processus pour améliorer l'efficacité opérationnelle.
Amélioration de l'Expérience Client
Description: Utilisation de l'IA pour offrir des expériences client plus personnalisées et réactives.
Gestion des Risques
Description: Amélioration des capacités de gestion des risques grâce à des modèles prédictifs.
Réduction des Fraudes
Description: Détection et prévention des fraudes par des algorithmes d'IA.
Conformité et Régulation
Description: S'assurer que les solutions d'IA sont conformes aux lois et régulations.
Relations de type association et agrégation
Chief AI Officer (CAIO) est associé à Innovation et Compétitivité, Amélioration de l'Efficacité, Amélioration de l'Expérience Client, Gestion des Risques, Réduction des Fraudes.
Data Scientists sont associés à Innovation et Compétitivité, Amélioration de l'Efficacité.
AI Ethics Committee est associé à Conformité et Régulation.
AI Engineers sont associés à Amélioration de l'Efficacité, Réduction des Fraudes.
Business Units sont agrégées sous Amélioration de l'Expérience Client, Gestion des Risques.
IT Department est agrégé sous Amélioration de l'Efficacité.
Compliance Officers sont associés à Conformité et Régulation.
Diagramme ArchiMate
Pour concevoir le diagramme ArchiMate représentant la vue Stakeholders & Concerns, vous pouvez suivre ces étapes :
Créer des éléments de type "Stakeholder" pour chaque partie prenante mentionnée.
Créer des éléments de type "Driver" pour chaque moteur spécifique à l'IA.
Relier les stakeholders aux drivers avec des relations d'association (lien simple) ou d'agrégation (lien avec inclusion).
Utiliser des éléments d'organisation pour montrer les relations hiérarchiques ou fonctionnelles (ex. : le CAIO peut superviser les Data Scientists et les AI Engineers). "
Fin de la réponse
- 6 -
Prompt pour la génération du diagramme ArchiMate
au format XML par ChatGPT
" Avec les éléments précédents, génère le diagramme ArchiMate au format Open Group ArchiMate XML. Je te donne un modèle de code que tu devras respecter : <copier/coller le contenu de votre template XML> "
- 7 -
Réponse de ChatGPT :
le document XML représentant le diagramme ArchiMate
Génération par ChatGPT du diagramme ArchiMate Stakeholder & Concerns
pour un groupe d'assurance désirant intégrer l'IA
- 8 -
Importation du modèle ArchiMate généré par ChatGPT dans Archi
File > Import > Model from Open Exchange file
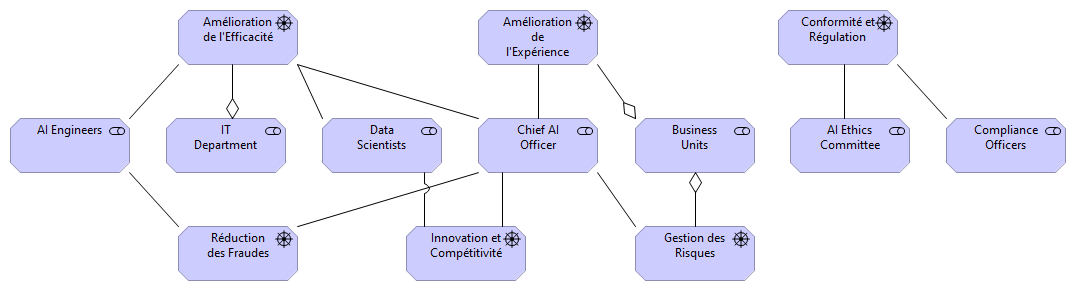
Le diagramme ArchiMate généré par ChatGPT correspondant à notre prompt,
importé dans Archi, après un léger repositionnement
- 9 -
Importation du modèle ArchiMate généré par ChatGPT dans Obeo SmartEA
Sauvegarder et fermer tous les éditeurs en cours > Menu Plus > ArchiMate > Import au format d’échange
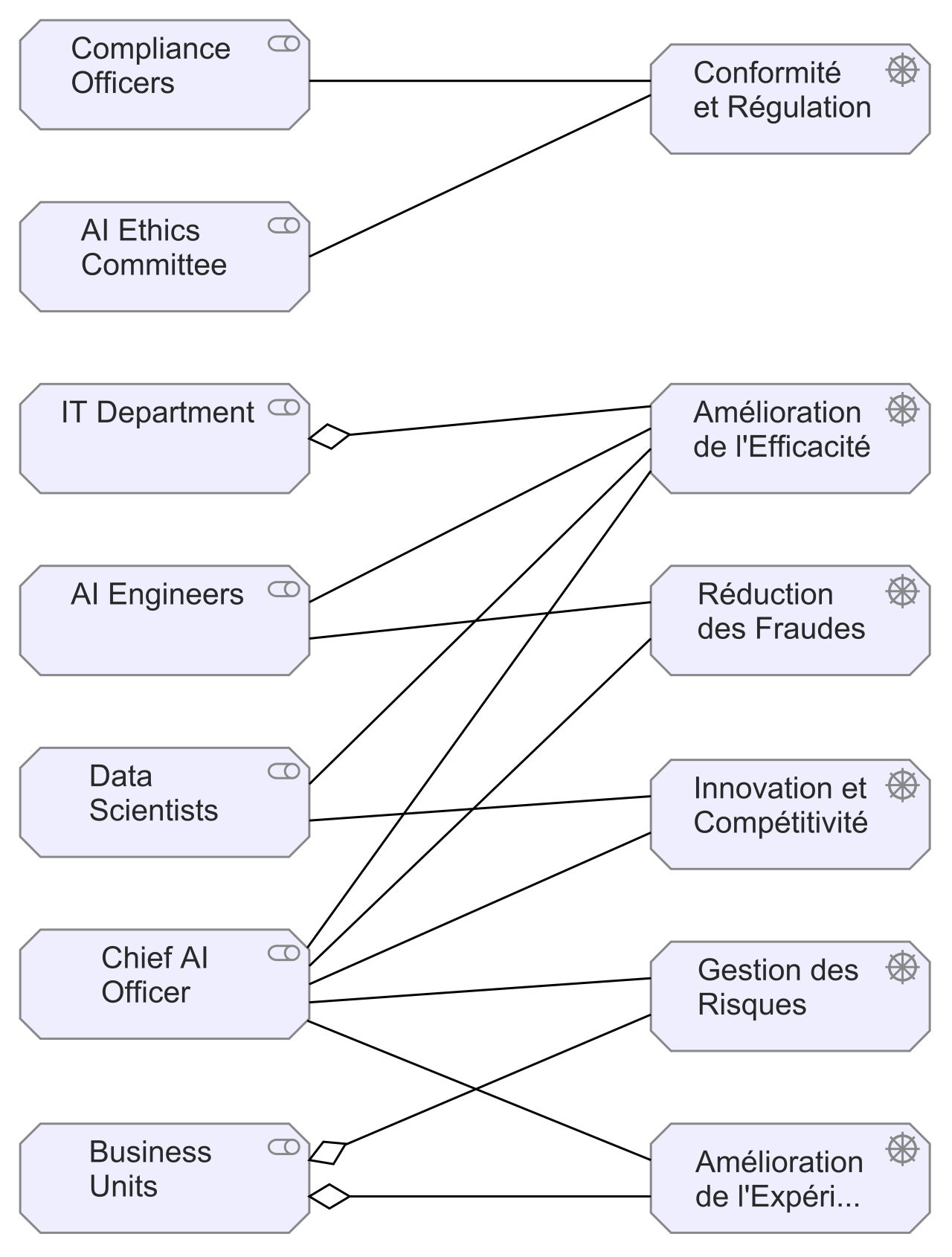
Le diagramme ArchiMate généré par ChatGPT correspondant à notre prompt,
importé dans Obeo SmartEA, dont la fonction "Réorganiser tout" (1ère icône de la vue) est bien utile ici
- 10 -
Vérifions que ChatGPT peut générer une autre vue
On va utiliser les capacités d’auto-amélioration, d’apprentissage autonome et de prise de décisions indépendantes de ChatGPT pour lui faire générer un nouveau modèle ArchiMate en prenant en compte les étapes précédentes.
L’objectif est de faire générer la vue Driver & Business Goals, toujours dans le même contexte et sans modifier notre template XML. On demande à ChatGPT les Assessments, Goals et Outcomes en relation avec les Drivers précédents ainsi que leur relation entre eux.
Prompt
" Avec les drivers ArchiMate précédents, je veux les assessments et leur relation de type association, les goals avec leur relation de type influence et les outcomes liés aux goals avec des relations de type influence ou realization. Je veux les descriptions de tous ces éléments ArchiMate. "
Remarque : non seulement ChatGPT nous donne la description des éléments ArchiMate, mais dans la même réponse, il a compris que nous voulons aussi le code XML correspondant.
On peut apporter quelques modifications en promptant :
“ Parfait. Je veux le même code, mais sans les stakeholders. “
“ Traduis en français les assessments, les goals, les outcomes et leur description. Je veux le même code, mais avec tous les éléments en français. “
Début de la réponse de chatGPT
" Le code XML est fourni (voir le fichier joint) avec la description des éléments :
Descriptions
Drivers:
Innovation et Compétitivité : Améliorer l'innovation et la compétitivité grâce à l'intégration de l'IA.
Amélioration de l'Efficacité : Optimiser l'efficacité des opérations et des processus internes.
Amélioration de l'Expérience Client : Améliorer la satisfaction et la fidélité des clients grâce à des services personnalisés et efficaces.
Gestion des Risques : Renforcer la gestion des risques en identifiant et en atténuant les risques de manière proactive.
Réduction des Fraudes : Utiliser l'IA pour détecter et réduire les fraudes de manière efficace.
Conformité et Régulation : Assurer la conformité avec les régulations et les exigences légales en vigueur.
Assessments:
Faisabilité de l'Adoption de l'IA : Évaluer la faisabilité de l'adoption de l'IA au sein de l'organisation.
Impact de l'IA sur la Main-d'Œuvre : Analyser l'impact de l'IA sur la main-d'œuvre, notamment en termes d'emplois et de compétences.
Conformité Réglementaire : Vérifier que les solutions d'IA respectent les régulations et les normes en vigueur.
Goals:
Mise en Œuvre Réussie de l'IA : Assurer une mise en œuvre réussie des technologies d'IA dans l'organisation.
Satisfaction Client Améliorée : Augmenter la satisfaction des clients grâce à des solutions innovantes et efficaces.
Efficacité Opérationnelle : Améliorer l'efficacité opérationnelle grâce à l'optimisation des processus par l'IA.
Atténuation des Risques : Réduire les risques grâce à des analyses prédictives et des actions proactives.
Réduction de la Fraude : Réduire significativement les fraudes grâce à des technologies d'IA avancées.
Outcomes:
Augmentation des Revenus : Générer des revenus supplémentaires grâce à l'amélioration des processus et à l'innovation.
Fidélité des Clients : Renforcer la fidélité des clients en améliorant leur expérience et leur satisfaction.
Réalisation de la Conformité : Atteindre une conformité totale avec les régulations et les normes en vigueur. "
Fin de la réponse
- 11 -
ChatGPT a inversé des relations
Une fois importé, on s’aperçoit que les relations "influence et realization" sont inversées : on va donc demander à ChatGPT d’inverser ces types de relations.
Remarque : on a épuisé pour l’heure notre quota de ChatGPT-4o, on est repassé en ChatGPT-3.5
Prompt
“ Inverse toutes les valeurs des éléments source et target sauf la relationship rel25 et la connection connection25. “
Réponse de chatGPT
Génération par ChatGPT de la vue Driver & Business Goals, toujours dans le même contexte
et sans modifier notre template XML
- 12 -
Importation dans Archi
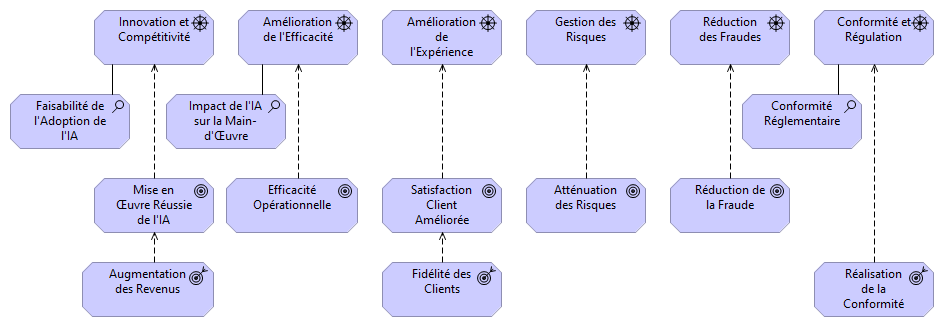
Résultat de l'importation dans Archi de la vue Driver & Business Goals
au format XML générée par ChatGPT
- 13 -
Importation dans Obeo SmartEA
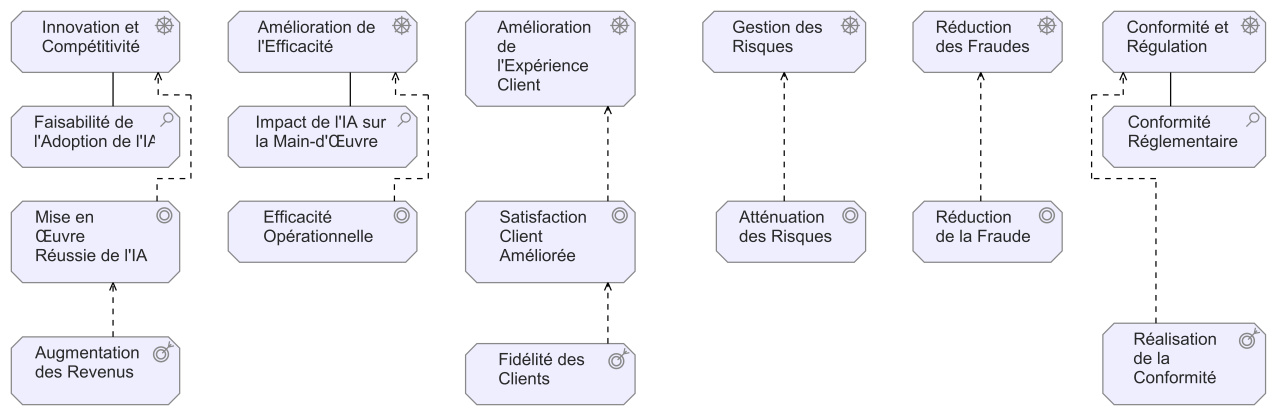
Résultat de l'importation dans Obeo SmartEA de la vue Driver & Business Goals
au format XML générée par ChatGPT
Compléments de lecture
- Architecture d'Entreprise augmentée, quelle influence de l’Intelligence Artificielle sur la gouvernance et la stratégie ?
- Le rôle de la prospective pour une entreprise innovante et résiliente
- ChatGPT, l’outil idéal de réalisation de modèles pour l’Architecture d’Entreprise et l’Urbanisation du Système d’Information ?
- Quel outil ArchiMate pour modéliser vos architectures d’entreprise sources et cibles, évaluer les écarts, analyser les impacts et élaborer des trajectoires de transformation ? Obeo SmartEA S.1 Ep.1
- Comment consolider un référentiel centralisé TOGAF rassemblant les autres référentiels Stratégie, Métier, Applications, Infrastructure… ? Obeo SmartEA S.1 Ep.2
- Archi (archimatetool) : essai et analyse de cet outil ArchiMate français gratuit sous Windows, Linux et Mac OS
La rédaction tient à souligner que la plateforme urbanisation-si.com est indépendante de toute organisation et son fonctionnement repose entièrement sur des bénévoles passionnés de pédagogie et désirant partager leur expérience. Vous ne verrez jamais de publicités sur notre plateforme.
Bien que nous encourageons l’open source, il peut nous arriver d’utiliser des logiciels commerciaux qui nous sont gracieusement prêtés sous aucune condition et nous ne touchons aucune rémunération de qui que ce soit.
Knowledge Graph et Architecture d’Entreprise (2/2)
Des ontologies modulaires
pour gérer la complexité et la pluridisciplinarité
Un Knowledge Graph, c’est une base de connaissance sous forme de graphe. Pour sa conception, il est crucial de clarifier les questions auxquelles elle devrait pouvoir répondre, ainsi que celles portant sur sa maintenance et son évolution.
Une approche clé pour assurer la flexibilité et la maintenabilité d’un Knowledge Graph consiste à le baser sur plusieurs ontologies modulaires inter-reliées, avec un noyau central. Chaque module peut alors être conçu pour traiter des concepts, des relations et des règles spécifiques à un sous-domaine d’expertise, ce qui en facilite la gestion et l’évolution avec les experts du domaine.
En reliant ces ontologies modulaires entre elles, on crée un réseau de connaissances. Cela permet de représenter des relations complexes entre les concepts qui transcendent les frontières des différents sous-domaines, offrant ainsi une vue globale et intégrée du domaine métier dans son ensemble. Or c’est typiquement un besoin des descriptions d’architecture de pouvoir représenter des couches d’architecture et leurs correspondances. Ou de présenter des perspectives spécifiques. Par exemple, la gestion des risques, l’architecture applicative, l’architecture des données, l’infrastructure technologique, l’évaluation de la performance…
Un noyau central définissant les fondamentaux de l’EA, via les concepts et relations réutilisables pour tous les modules, permettra l’interopérabilité. La référence à une ontologie de haut niveau (top-level) ou des « patrons » de conception servira à ne pas réinventer la poudre pour des problèmes généraux de conception déjà bien connus.
Bien entendu, la conception d’un Knowledge Graph d’Architecture d’Entreprise doit suivre les bonnes pratiques. En particulier, réutiliser autant que possible des ontologies existantes et des vocabulaires standards pour éviter la duplication d’efforts et promouvoir la cohérence avec les pratiques établies dans le domaine.
Des ontologies pour des Knowledge Graphs agnostiques des cadres de référence
Les concepts décrits dans une ontologie d’Architecture d’Entreprise (ou module), existent indépendamment des cadres de référence ou langages de description. Car si ces derniers sont réutilisables pour les identifier et les définir, ni un glossaire, ni des textes descriptifs, ni des objets graphiques ne spécifient formellement des concepts et des relations. « Things, not strings » : une ontologie définit des choses et les labels donnés aux choses ne suffisent pas pour les définir. Si deux terminologies différentes désignent le même concept, on trouvera un concept et deux labels dans l’ontologie. Quand elles désignent l’une une spécialisation, l’autre une généralisation, on définira les relations de subsomption et les caractéristiques propres des deux concepts. Et si au contraire elles désignent deux choses différentes et disjointes, on doit le définir également.
Une ontologie, c’est une représentation sémantique riche des entités et de leurs relations en mesure de suivre l’évolution des connaissances. En utilisant les standards du Web sémantique (RDF, RDFS, OWL), contrairement à certains langages de modélisation plus rigides, les Knowledge Graphs sont flexibles et extensibles. Ils permettent d’ajouter de nouveaux concepts, relations et attributs au fur et à mesure que l’Architecture d’Entreprise évolue, assurant ainsi une représentation toujours à jour et adaptable.
Pour prendre l’exemple du langage graphique de description d’architecture ArchiMate, les liens sont limités et certains concepts spécifiques à la stratégie d’offre, au marché, aux situations, aux aspects financiers, ne sont pas dans l’ensemble de ceux prédéfinis.
A contrario, un réseau d’ontologies modulaires peut spécifier des concepts dans tous les sous-domaines de gouvernance et de pilotage de l’entreprise et les relier aux capacités de l’entreprise et les composants qui les supportent. Tout Knowledge Graph exploitant ce réseau peut dès lors procurer une représentation plus riche, flexible et contextuelle des éléments clés éclairant les décisions qui engagent l’entreprise.
Architecture d’Entreprise et continuum d’ontologies
Alliance autour de la technologie OntoPortal
La démarche de description d’Architecture d’Entreprise est continue, itérative et incrémentale. On peut difficilement arriver à une architecture unifiée unique qui satisferait à toutes les exigences de toutes les parties prenantes à tout moment et l’idéal d’avoir des documentations et des modèles à jour suivant toutes les perspectives est une utopie dont la mise en œuvre est dystopique.
Des plateformes pour réutiliser des ontologies consistantes et cohérentes, ou accéder à des patrons de conception et des outils de développement et de curation pour modéliser et implémenter de nouvelles spécifications, ont été mises en place dans différents secteurs d’industrie. Elles concrétisent une approche réellement FAIR des métadonnées.
L’alliance OntoPortal autour de l’outil éponyme (https://ontoportal.org) est significative du besoin de promotion de telles plateformes pour « le développement de référentiels d’ontologie – en science et dans d’autres disciplines ».
Le parallèle peut être fait avec la notion de Continuum d’Entreprise qu’on trouve dans TOGAF. L’idée est d’organiser des artefacts d’architecture et des actifs de solutions réutilisables afin de maximiser les opportunités d’investissement dans l’Architecture d’Entreprise. Dans cette optique, la construction de plateformes communes aux architectes d’entreprises pour recevoir, héberger, servir, aligner et permettre la réutilisation d’ontologies pour l’EA a tout son intérêt. On devrait y trouver différentes ontologies d’entreprise et des métamodèles génériques à spécialiser ou étendre.
Un métamodèle d’entreprise générique
et un langage graphique : EDGY
EDGY enterprise design facets
Si toute entreprise a sa propre dynamique, toutes les entreprises partagent le fait d’avoir des produits et/ou services, des offres portant sur ces produits, des processus supportant les opérations, des rôles, des acteurs, des applications des SI avec des composants, etc. On peut très bien s’entendre sur un vocabulaire et des axiomes logiques pour exprimer ce genre de choses et leurs liens.
Dans ce domaine, l’initiative de la communauté Intersection Group est à souligner. Car elle introduit, avec l’approche « Enterprise Design with EDGY », un langage graphique simple et expressif pour un métamodèle d’entreprise transverse à tous les métiers. En effet, EDGY propose une vue unifiée et consolidée de l’entreprise à des fins de décision collaborative grâce à l’intersection entre trois perspectives : identité, Expérience et Architecture.
La première traite de la raison d’être de l’entreprise aussi bien que de sa culture. A ce sujet, le mantra
« culture eats strategy at breakfast » illustre bien l’importance de ces concepts. La seconde se focalise sur l’expérience procurée aux clients et aux autres acteurs. Une manière également pertinente de traiter dynamiquement de la valeur créée pour les parties prenantes. La dernière s’interroge sur comment orchestrer tout cela, en déclinant modèle d’affaires, modèle opératoire et composants d’architecture.
Le credo d’EDGY est d’avancer que les connecteurs nécessaires à créer entre des disciplines traitées aujourd’hui de façon trop isolée se trouvent à l’intersection desdites perspectives, où l’on trouvera les concepts de produit, organisation, marque.
L’approche EDGY propose les outils pour élaborer une représentation graphique commune, utile et transverse, des éléments clés de l’entreprise à des fins de décision. Cependant, il lui manque encore la dimension formelle des ontologies, pour disposer également d’une base de connaissances sémantiquement riche.
Un outil d’EA basé sur des ontologies :
The Essential Project
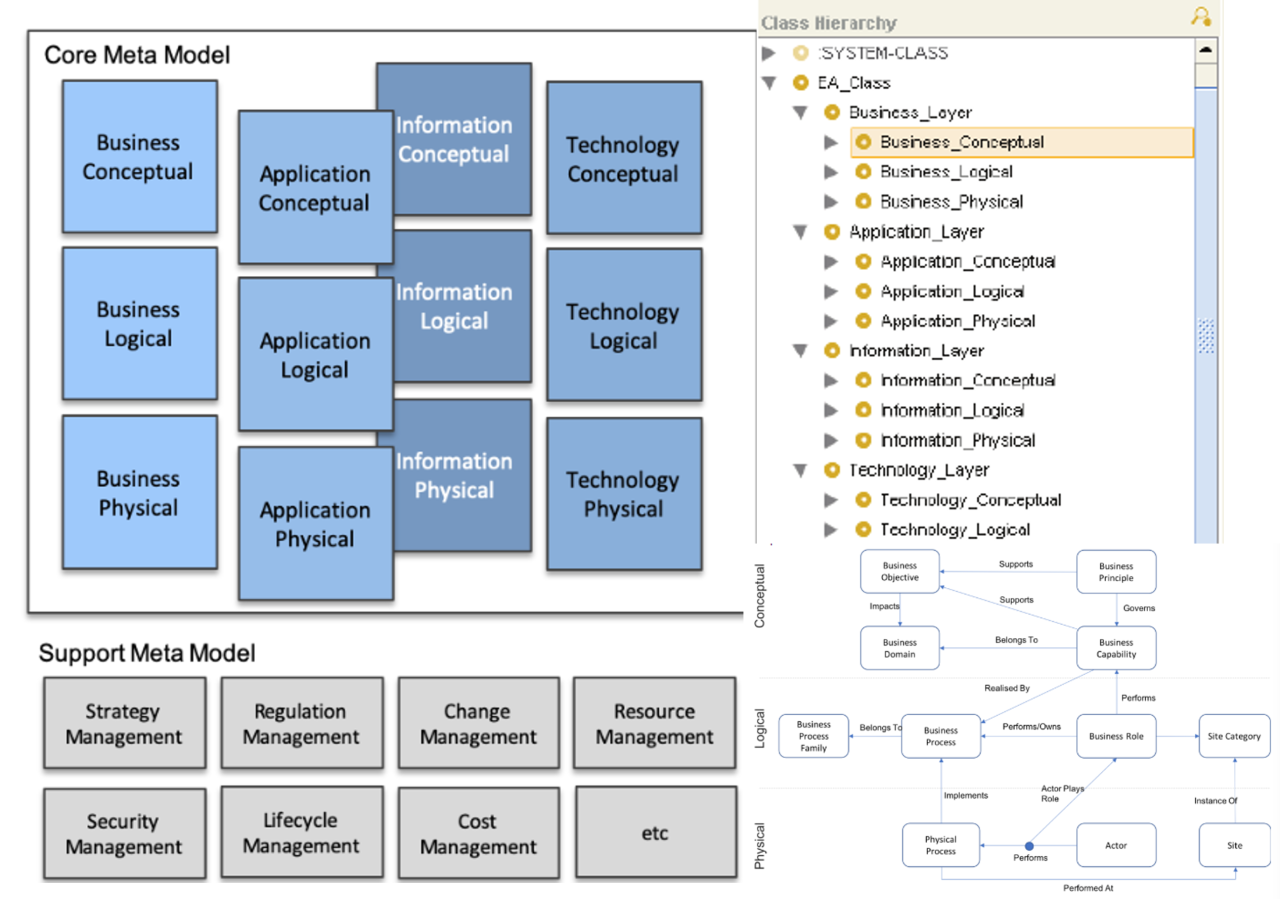
Illustration du Meta-Model d’Essential avec zoom sur partie métier
Fournir pour la description des composants d’architecture, un métamodèle à base d’ontologies, flexible et extensible, cela existe déjà. Dès 2009, «The Essential Project » a été lancé par l’équipe des consultants d’EAS (Enterprise Architecture Solutions) sur cette base, en modélisant des ontologies sous Protégé. La première version open source d’Essential (visant les capacités essentielles à une pratique d’EA) date de mars 2009. La mise en relation avec les concepts TOGAF n’est arrivée qu’en 2015.
Certes, ce sont des demandes des utilisateurs qui ont conduit à la publication d’un mappage TOGAF vers Essential. Reste que, selon EAS, « le métamodèle Essential est, en fait, plus riche en contenu et prend en charge tous les principaux frameworks EA, tout en restant indépendant du framework ».
L’outil Essential a été placé « visionnaire » dans le Gartner Magic Quadrant 2023 des outils d’Architecture d’Entreprise. Si l’on consulte Gartner Peer Reviews, il est globalement bien noté. Avec des commentaires tels que ce dernier : « EAS has a powerful metadata repository that can cover multiple dimensions of the architecture. Also, the look and feel is very appealing, with easy to navigate reports ». Certes, à d’autres égards, notamment les représentations graphiques, il offre moins de richesse que d’autres alternatives.
Mais si l’essentiel recherché est d’avoir effectivement les bons liens entre composants, pour une bonne analyse d’impact, il correspond. Grâce à son métamodèle à base d’ontologies. Tandis que ceci est rarement capturé sans la moindre ambiguïté par un diagramme, au contraire d’un Knowledge Graph. De plus, si l’on part sur l’usage des technologies RDF et OWl, l’interopérabilité du référentiel d’architecture avec d’autres outils utilisés comme bases de modèles, de documentation ou d’exigence sera de facto facilitée, éventuellement avec un VKG et des outils de conversion conformes à RML.
A quand un EAO comme OBO ?
Il manque toutefois un véritable consensus sur des spécifications formelles de conceptions partagées des domaines de connaissance en Architecture d’Entreprise. I.E les ontologies du réseau modulaire évoquées précédemment, avec un moyen de généraliser ou spécialiser certaines. Tout autant qu’un moyen pour les partager (en mode FAIR) ainsi que disposer de services utiles sur tout le cycle de vie du (ou des) Knowledge Graph d’architecture qu’on peut construire à partir de ces spécifications.
On sait que dans certains domaines, cela existe, le plus connu étant l’OBO foundry pour la biologie et la biomédecine. Une communauté autour d’OBO a développé de bonnes pratiques autant pour l’évaluation, la curation, la réutilisation des ontologies que pour la constitution d’outils utiles à leur développement. On peut évoquer des outils comme ODK, ROBOT, ou OntoPortal.
Comme on peut évoquer de nombreux outils, conformes à RML, qui faciliteront le mapping en RDF de sources de données existantes pour la construction des Knowledge Graphs d’EA en entreprise.
Si les bénéfices et les outils existent, une question demeure. Pourquoi nulle communauté d’architecte, éventuellement avec le financement d’une association de standardisation, n’a construit d’EA Ontology foundry ? Est-ce parce que financer une telle démarche serait contre-productif pour certains modèles d’affaires associés aux cadres de références d’EA existants ?
Sabine BOHNKÉ
![]()
"Le vrai signe d'intelligence n'est pas la connaissance, c'est l'imagination."
Albert Einstein
Compléments de lecture
- Knowledge Graph et Architecture d’Entreprise (1/2)
- Comment vérifier un modèle ? Exemple de simulation d’un processus métier BPMN
- Quel outil ArchiMate pour modéliser vos architectures d’entreprise sources et cibles, évaluer les écarts, analyser les impacts et élaborer des trajectoires de transformation ? Obeo SmartEA S.1 Ep.1
- Comment consolider un référentiel centralisé TOGAF rassemblant les autres référentiels Stratégie, Métier, Applications, Infrastructure… ? Obeo SmartEA S.1 Ep.2
Knowledge Graph et Architecture d’Entreprise (1/2)
Un potentiel mal exploité
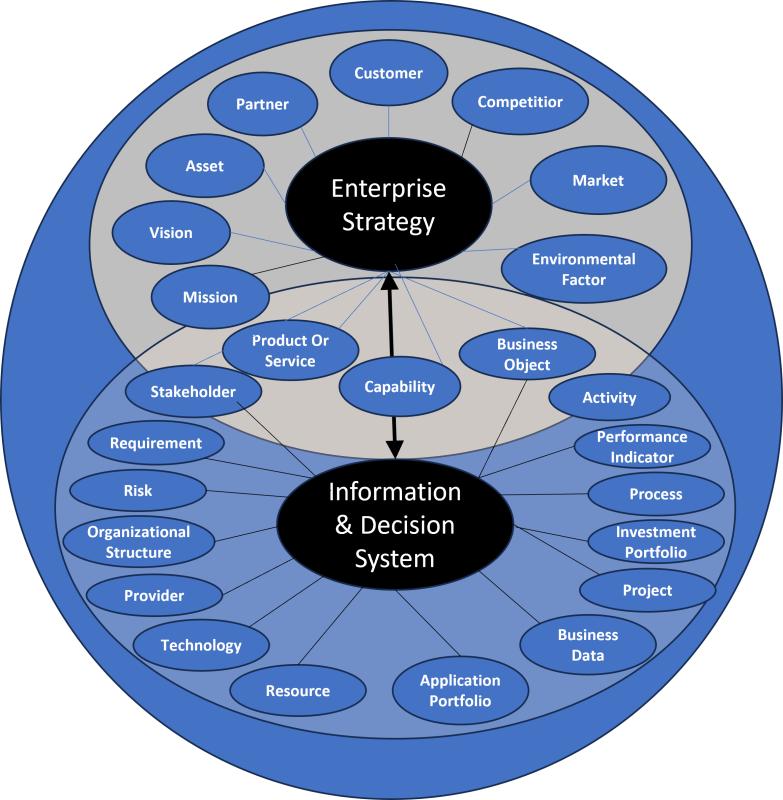
Champ des éléments en interaction pour l’Architecture d’Entreprise
L’Architecture d’Entreprise (AE) est une discipline destinée à favoriser, face à des situations en constante évolution, le développement d‘une stratégie d’entreprise conforme à ses finalités ainsi que son exécution ad hoc.
Cette discipline est profondément liée aux approches de représentation des connaissances. Il est donc curieux que le potentiel des Knowledge Graphs y soit encore insuffisamment exploité. En effet, ces derniers sont pertinents pour représenter de manière expressive la sémantique d’un système. Ils offrent également des moyens de naviguer entre les concepts de connaissance et leurs interrelations. Cela en suivant des standards du Web sémantique et des modèles et ensembles de données FAIR (Findable, Accessible, Inter-operable, Re-usable).
Il est toutefois décevant, au niveau de la couche sémantique, de constater que les essais d’approche des Knowledge Graphs pour l’Architecture d’Entreprise – à quelques exceptions près – se soient cantonnés à des traductions littérales en langage OWL de modèles ou de cadre de référence existants. Or exprimer en OWL les règles et objets de langages tels ArchiMate ou la terminologie de TOGAF, a peu d’intérêt. On restreint ainsi une richesse d’expression sémantique aux contraintes voire incohérences de sources existantes. Les réutiliser à un sens, mais il ne faut pas confondre sources terminologiques et spécification formelle d’une conceptualisation.
Pour que l’approche des graphes de connaissances appliquée à l’Architecture d’Entreprise fonctionne, il ne faut pas se tromper de cible. Aussi suivre les bonnes pratiques de construction, tant pour la conception que l’implémentation. Cet article développe aussi bien les enjeux en la matière que les moyens d’y arriver.
Architecture d’Entreprise
et représentation des connaissances
Une partie de l’Architecture d’Entreprise consiste à décrire le système entreprise au juste nécessaire dans son environnement. Ce « juste nécessaire » revient à disposer d’informations clés afin de réduire l’incertitude sur les situations en développement. Il s’agit autant de décrire les objectifs stratégiques que les aspects organisationnels, les capacités, les ressources, les processus, les technologies, en d’autres termes, tous les composants essentiels qui structurent l’entreprise, leurs interactions ainsi que leurs évolutions dans un monde ouvert, à des fins décisionnelles. L’idéal étant de pouvoir simuler l’impact de choix sur une représentation de l’entreprise à un instant t.
Les descriptions d’architecture servent à acquérir une connaissance utile pour comprendre, choisir et planifier les actions de transformation en continu. L’entreprise est, par ailleurs, un système dynamique complexe. Dès lors, l’approche systémique est de mise. Elle conduit à se concentrer sur les interactions internes entre éléments du système ainsi que leurs relations externes avec l’environnement. Sans oublier, bien sûr, de définir clairement les finalités du système pour identifier des pistes d’évolution conformes aux enjeux stratégiques.
Tout cela nécessite de décrire explicitement ce qui est su des éléments et leurs interactions. Donc de collaborer avec des « SME » (Subject Matter Expert) pour éliciter leurs connaissances. Il faut ensuite la formaliser tout en intégrant la nécessité permanente de mise à jour. Dès lors, des outils et procédés de représentation et partage des connaissances sont nécessaires à plusieurs niveaux d’abstraction.
Things, not strings
Image extraite de l’article de Amit Singhal « Introducing the Knowledge Graph: things, not strings »
Deux erreurs communes depuis des années sont prégnantes dans les systèmes d’information. Modéliser des données pour stockage avant d’expliciter les concepts manipulés et penser plus au couple problème/solution qu’aux enjeux globaux. D’où le fameux « integration spaghetti » du Gartner. C’est à dire un SI constitué d’une mosaïque de systèmes peu évolutifs, peu interopérables, avec de nombreux silos de données.
Quand on parle de concepts manipulés, ce sont les objets métiers, concrets ou abstraits de l’univers du discours de l’entreprise. Un constructeur automobile manipulera des concepts liés aux voitures, un assureur, des contrats d’assurance. Les acteurs métiers aujourd’hui évoquent des « données métiers ». En réalité, les données ne sont déjà plus des objets métiers. Ce sont des traductions en formats numériques, de parties de choses utiles au métier. Et souvent, sous la seule perspective à court terme d’un fonctionnement applicatif recherché.
Dans le champ de l’Architecture d’Entreprise, il y a nécessairement la description des objets métiers manipulés par les acteurs. Cette description sert autant à définir les capacités à développer qu’à fluidifier les échanges entre systèmes d’information.
En 2012, un article de Amit Singhal « Introducing the Knowledge Graph: things, not strings » saluait l’arrivée du Google Knowledge Graph. Things, not strings : tel devrait être également le slogan des échanges entre systèmes d’information.
Les choses sur lesquelles on a besoin d’information ne sont pas les chaines de caractères qui les désignent. Pas plus qu’elles ne sont la façon dont on les stocke ou on les transfère. On a besoin d’un niveau de représentation indépendant des plateformes ou des syntaxes des formats d‘échange pour dire que les données qu’on manipule sont bien liées à telle ou telle chose. Des métadonnées connectées dans un « Knowledge Graph » sont typiquement une réponse à ce besoin.
Architecture d’Entreprise,
Virtual Knowledge Graph et Data Fabric

Image extraite de l’article du Gartner
« Data Fabric Architecture is Key to Modernizing Data Management and Integration »
Un Knowledge Graph consiste en une ou plusieurs ontologies formelles liées et des ensembles de données cohérents avec celles-ci. En créant les ontologies spécifiant les concepts de l’entreprise, on peut ensuite créer un « Virtual Knowledge Graph » (VKG). Il s’agit du concept autrefois nommé OBDA (Ontology-Based Data Access).
En utilisant des ontologies, de la fédération de requêtes SPARQL et du mapping (R2ML), cette approche offre un moyen d’interroger les différentes sources de données distribuées au sein de plusieurs systèmes en fonction des concepts métiers sur lesquels elles ont des informations. Elle permet en outre aux données de rester dans leurs bases d’origine pour une gestion plus agile et plus efficace.
Ici, la description, via une spécification formelle, de composants de l’Architecture d’Entreprise, permet d’optimiser la construction d’autres composants d’architecture. Il existe par ailleurs des outils commerciaux et open source pour créer des VKG. Au-delà de la notion de VKG, c’est le concept de Data Fabric qui profite au mieux des Knowledge Graphs. En utilisant la couche sémantique du graphe de connaissance pour établir la provenance, la qualité et le sens des données gérées dans les systèmes d’information de l’entreprise, on s’oriente vers une meilleure vue intégrée et unifiée de ces derniers. Ce que soulignait l’article publié en 2021 sur le site du Gartner « Data Fabric Architecture is Key to Modernizing Data Management and Integration » : « Data fabric must create and curate knowledge graphs ».
Architecture d’Entreprise :
cas d’usage des Knowledge Graphs
Certes, la construction et la curation desdits Knowledge Graphs nécessitent des efforts. Cependant, il existe de meilleures pratiques et des outils pour des résultats relativement rapides avec des solutions robustes et évolutives.
Deux orientations d’usages des Knowledge Graphs dans le domaine de l’Architecture d’Entreprise sont particulièrement intéressantes. L’une, déjà évoquée, porte sur l’interopérabilité sémantique via la spécification des concepts métiers pour cas d’usage analytique ou transactionnel. L’autre porte sur l’activation dynamique d’un métamodèle des composants d’une entreprise pour guider des changements stratégiques. En spécifiant formellement les composants à connaître, ainsi que leurs interrelations, pour décider et suivre au mieux l’évolution des transformations, on peut construire un graphe de connaissance qui permettrait de réduire les incertitudes liées aux options de changement.
Les Knowledge Graphs aident à contextualiser les décisions liées à l’évolution du système d’information en reliant les éléments architecturaux aux facteurs d’influence externes, aux objectifs métier, aux contraintes opérationnelles et aux tendances technologiques. Cette vision holistique guide les décideurs vers des choix plus éclairés et alignés sur les objectifs stratégiques de l’entreprise. Par ailleurs, en spécifiant avec des métadonnées les relations entre les composants, les Knowledge Graphs facilitent l’analyse d’impact des changements. Cela permet de comprendre rapidement comment une modification dans une partie spécifique de l’architecture peut affecter d’autres composants, aidant ainsi à anticiper les conséquences potentielles et à simuler des scénarios pour prise de décision.
Mais si l’on veut un Knowledge Graph d’Architecture d’Entreprise, contenant tous les composants de l’entreprise ainsi que leurs liens, comment procéder ? N’est-ce pas un travail trop complexe ?
Vous trouverez des éléments de réponses dans le prochain article
" Knowledge Graph et Architecture d’Entreprise (2/2) ".
Sabine BOHNKÉ
![]()
« La connaissance s'acquiert par l'expérience, tout le reste n'est que de l'information. »
Albert Einstein
Compléments de lecture
Métamodèle TOGAF - ArchiMate
- Méta-physique ? Non, méta-modélisation !
- Les concepts du métamodèle de l’architecture d’entreprise TOGAF (The Open Group Architecture Framework)
- L’extension « Modélisation de processus métier » du métamodèle de l’architecture d’entreprise TOGAF (The Open Group Architecture Framework)
- ArchiMate mémento : Alignement de la couche métier avec les couches inférieures - 8
Les critères d'un bon modèle