
Architecture technique
Autonomic Computing ou Informatique Autonome, est-elle une informatique visionnaire ?
L'informatique autonome aide à réduire la complexité en utilisant la technologie pour gérer la technologie. Dans cet environnement, les systèmes sont capables de s’adapter dynamiquement au changement des politiques métier.
Les enjeux de l'Informatique Autonome.
Similaire au corps humain ?
Le terme autonome est dérivé de la biologie humaine. Inconsciemment, le système nerveux autonome surveille votre rythme cardiaque, vérifie votre niveau de glycémie et maintient votre température corporelle proche de 37 °C, sans aucun effort de votre part.
De la même manière, l'informatique autonome anticipe les exigences du système informatique et résout les problèmes sans intervention humaine. Les professionnels de l'IT peuvent se concentrer sur des tâches à plus forte valeur ajoutée pour l'entreprise.
Cependant, il existe une distinction importante entre l'activité autonome dans le corps humain et les activités autonomes dans les systèmes informatiques : de nombreuses décisions faites par les capacités autonomes du corps humain sont involontaires. En revanche, les capacités autonomes dans les systèmes informatiques effectuent des tâches que les informaticiens choisissent de déléguer à la technologie, conformément à la gouvernance en place.
Un moteur de règles, plutôt qu'une procédure codée en dur, détermine les types des décisions et des actions que les composants autonomes effectuent.
Introspection
Le système autonome se connaît :
- Il connaît ses composants, leurs spécifications, leurs capacités et leurs états en temps réel.
- Il a également des connaissances sur ses ressources propres, empruntées et partagées.
- Il peut se configurer encore et encore et exécuter sa configuration automatiquement
au fur et à mesure des besoins. - Il a la capacité de s'optimiser en ajustant les flux de travail.
- Il peut se réparer, il peut se remettre des échecs.
- Il peut se protéger en détectant et en identifiant diverses attaques à son encontre.
- Il peut s'ouvrir. Cela signifie qu'il ne doit pas s'agir d'une solution propriétaire
et doit implémenter des standards ouverts. - Il est invisible. Cela signifie qu'il a la capacité de permettre l'optimisation des ressources,
en masquant sa complexité.
Un système autonome, selon IBM, doit être capable de savoir ou d'anticiper le type de demande qui va survenir pour ses ressources.
Les capacités d'auto-gestion d'un système accomplissent leurs fonctions, en prenant une action appropriée selon une ou plusieurs situations qu'ils perçoivent dans l'environnement. La fonction de toute capacité autonome est une boucle de contrôle, qui collecte les détails du système et agit en conséquence.
Ces boucles de contrôle sont organisées en quatre catégories : auto-configuration, auto-réparation, auto-optimisation et auto-protection.
Auto-configuration
Les composants auto-configurables s'adaptent dynamiquement aux changements de l'environnement, en utilisant les règles fournies par les informaticiens.
De tels changements pourraient inclure le déploiement de nouveaux composants ou la suppression de ceux existants, ou des changements importants dans les propriétés du système. L'adaptation dynamique assure une productivité constante de l'infrastructure informatique, ce qui entraîne une croissance et une grande flexibilité de l'entreprise.
Auto-réparation
Cette propriété permet de découvrir, diagnostiquer et réagir aux perturbations.
Les composants d'auto-réparation peuvent détecter les dysfonctionnements du système et initier des actions correctives basées sur des règles, sans perturber l'environnement informatique. Une action corrective peut impliquer qu'un composant modifie son propre état ou effectue des changements sur les autres.
Le système dans son ensemble devient plus résilient, parce que les opérations quotidiennes sont moins susceptibles d'échouer.
Auto-optimisation
Les ressources sont surveillées et réglées automatiquement pour une efficience optimale.
Les composants d'auto-optimisation peuvent s'adapter pour répondre à l'utilisateur final ou aux besoins de l'entreprise. Les actions de réglage peuvent être la réallocation des ressources - par exemple en réponse à des augmentations des charges de travail - pour améliorer les temps de réponse des processus métier.
Auto-protection
Les menaces sont anticipées, détectées, identifiées et les parades sont mises en place.
Les composants auto-protégés peuvent détecter des comportements suspects au fur et à mesure qu'ils se produisent et prendre des contre-mesures, pour se rendre moins vulnérables par exemple aux accès non autorisés, à l'infection et à la prolifération de codes malveillants, ainsi que les attaques par déni de service.
Les capacités d'auto-protection permettent aux entreprises d'appliquer systématiquement des politiques de sécurité et de confidentialité.
Intégration dans ITIL
Les entreprises informatiques organisent ces tâches sous la forme d'un ensemble de meilleurs pratiques et processus, tels que ceux définis dans ITIL (Information Technology Infrastructure Library).
Traditionnellement, la détection d’un dysfonctionnement nécessite la mise en œuvre d’une procédure fastidieuse : il faut créer la demande de correction, recueillir les détails de l'incident et suivre l’évolution de l’état du ticket d’anomalie sur une plateforme.
Dans un système auto-géré, les composants peuvent initier ces étapes en fonction des informations provenant directement du système. Cela aide à réduire les tâches manuelles et le temps nécessaire pour répondre aux situations critiques.
Dans un processus de gestion des problèmes, une des étapes est le diagnostic. Dans les systèmes auto-gérés, les ressources sont créées telles que l'expertise requise pour effectuer cette tâche puisse être encodée dans le système et ainsi puisse être automatisée.
La plus-value client
L'efficience des processus informatiques typiques est mesurée à partir du temps écoulé pour terminer un processus, le pourcentage exécuté correctement et le coût d'exécution d'un processus.
Les systèmes auto-gérés peuvent affecter positivement ces métriques, améliorant la réactivité et la qualité de service, en réduisant le coût total de possession (TCO) et en améliorant le délai de rentabilité.
L'informatique autonome est nécessaire pour surmonter le problème de la complexité accrue :
- des systèmes distribués, dont les prévisions tablent sur une croissance de 40 % par an,
- des applications qui doivent s'adapter au travail en distanciel.
Architecture de l'Autonomic Computing
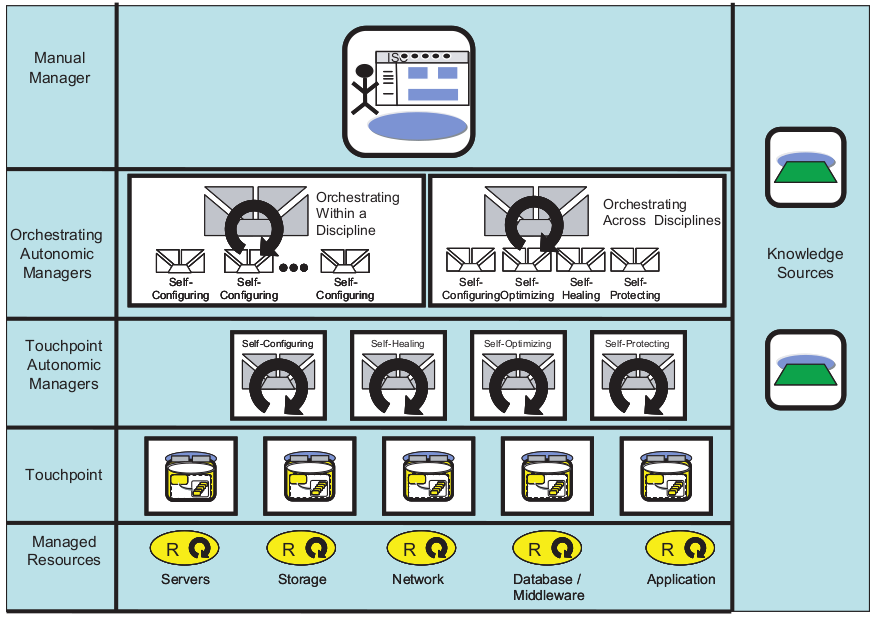
Les couches de l'Architecture de l'Autonomic Computing
L'architecture AC (Autonomic Computing) comprend des propriétés qui permettent l'auto-gestion selon divers fournisseurs, en impliquant des boucles de contrôle qu'un fournisseur de ressources intègre dans l'environnement d'exécution.
- Éléments gérés (Managed Resources) : l'élément géré est un composant du système contrôlé. Il peut s'agir aussi bien d'une ressource matérielle que d'une ressource logicielle. Des capteurs et des effecteurs sont utilisés pour contrôler l'élément géré.
- Capteurs (Touchpoint) : fournissent des informations sur l'état et tout changement d'état
des éléments du système autonome. - Effecteurs (Touchpoint Autonomic Managers) : ce sont des commandes ou interfaces de programmation d'applications (API) qui sont utilisées pour changer les états d'un élément.
- Gestionnaire autonome (Orchestrating Autonomic Managers) : utilisé pour s'assurer que les boucles de contrôle sont mises en œuvre. Celui-ci divise la boucle en 4 parties pour son fonctionnement. Ces parties sont : surveiller, analyser, planifier et exécuter -
MAPE (Monitor, Analyze, Plan, Execute). - Interface Utilisateur (Manual Manager) : l'environnement d'exécution est configuré à l'aide d'une interface de gestion fournie pour chaque ressource, par exemple des moyens de stockage.
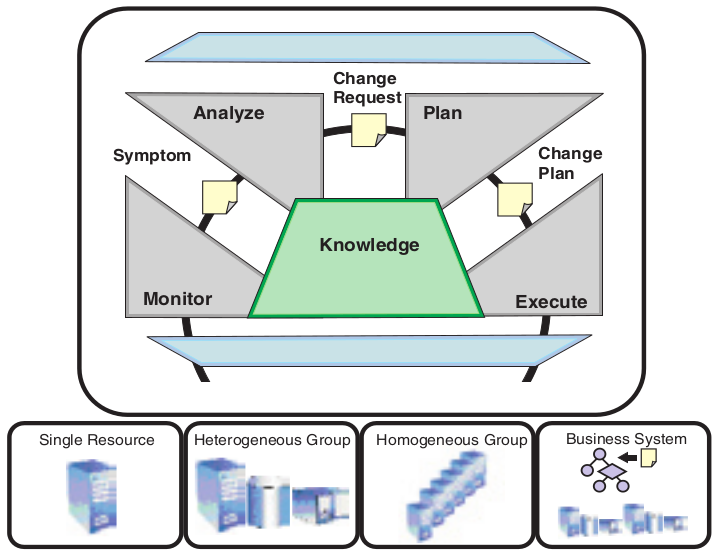
Architecture MAPE (Monitor, Analyze, Plan, and Execute) : surveiller, analyser, planifier et exécuter
Exemples
- Exécution d'une tâche d'auto-configuration telle que l'installation d'un logiciel
lorsqu'il détecte que certains logiciels prérequis sont manquants. - Exécution d'une tâche d'auto-réparation telle que la correction d'un chemin configuré
afin que les logiciels installés puissent être correctement localisés - Exécution d'une tâche d'auto-optimisation telle que l'adaptation de la CPU
lorsqu’elle constate une augmentation des transactions. - Exécuter une tâche d'auto-protection telle que mettre des ressources hors ligne
en cas de détection d’une tentative d'intrusion.
Conclusion
L'Autonomic Computing nécessite 3 conditions :
- Automatique : le système doit pouvoir exécuter ses opérations sans intervention humaine.
- Adaptatif : les ordinateurs autonomes doivent pouvoir apporter des modifications en fonction de leur environnement et d'autres conditions imprévues, telles que les attaques de sécurité et les pannes du système.
- Conscient : il doit également avoir connaissance des processus et des états internes
qui permettraient d'exécuter les deux fonctionnalités précédentes.
Avantages
- Open Source
- C'est une technologie évolutive qui s'adapte aux nouveaux changements.
- Donne donc une meilleure efficacité et de meilleures performances.
- Sécurisé, peut contrer automatiquement des attaques.
- Dispose de mécanismes de sauvegarde qui permettent la récupération après les pannes
et le plantage du système. - Réduit le coût de possession (TCO) d'un tel mécanisme, car il est moins sujet aux pannes
et peut se maintenir automatiquement. - Il peut se configurer lui-même, réduisant ainsi le temps nécessaire
à la configuration manuelle.
Inconvénients
- Il y aura toujours une possibilité de plantage ou de dysfonctionnement du système.
- Impact sur l'emploi pour certaines professions.
- Le système coûte plus cher.
- Besoin de compétences hautement qualifiées pour gérer ou développer de tels systèmes, augmentant ainsi le coût pour l'entreprise qui les emploie.
- Dépendant de la bande passante réseau et donc pas forcément disponible partout.
|
|
Rhona Maxwel @rhona_helena |
"Sur tous les sujets, des opinions contradictoires se font face, et la plupart d’entre nous n’ont pas les outils nécessaires pour savoir laquelle est la bonne."
Yuval Noah Harari
Compléments de lecture
- L’Architecture Micro-Services expliquée à ma fille
- Inconvénients de l'Architecture Micro-Services
- Orchestration des micro-services avec BPMN
- Conseils pour réussir vos micro-services et éviter qu’ils ne se transforment en véritable pensum
- Estimation de la complexité d’une Architecture Micro-Services
- Solutions sur étagère pour la gestion des défaillances des Micro-Services
- Comment éviter la loi de Conway et faciliter ainsi l’agilité avec l’approche Micro-Services ?
- Les couches de l'Architecture Microservices et la méthode de conception DDD (Domain Driven Design)
- Architecture Hexagonale, exemple de mise en pratique de la méthode DDD Domain Driven Design
- Agilité logicielle : quelle solution pour diminuer le couplage entre sous-systèmes et obtenir une architecture logicielle agile ?
- Urbanisation, SOA et BPM d’Yves Caseau
Quelles solutions pour concilier architecture logicielle et agilité ?
Des plus petites aux plus grandes entreprises, le concept de bounded context est aujourd’hui au cœur de la conception d’architecture logicielle, mais se pose l’éternelle question de quelle méthode pour parvenir à un découpage produisant le couplage le plus faible, augmentant ainsi l’évolutivité, l'autonomie et l'agilité.

Evolution de l'architecture logicielle
Dans notre article consacré au livre Urbanisation, SOA et BPM, l’auteur Yves Caseau, insiste sur l’urbanisation fractale ou comment appliquer récursivement les mêmes principes à différentes échelles du SI. En effet, les concepts, comme les “General Responsibility Assignment Software Principles" (GRASP) ou encore les design patterns du GoF (Gang of Four), mis en œuvre dans la conception orientée objet à toute petite échelle, se retrouvent dans les strates supérieures au niveau de l’architecture d’entreprise. Ces principes sont les gammes de l’architecte logiciel, qui s’acquièrent au plus bas niveau en programmation orienté objet et qui permettent ensuite d’avoir les bons réflexes au niveau d’un SI global.
D'après Craig Larman, ces patterns sont des “boîtes à outils mentales”, une aide à la conception à petite ou à très grande échelle.
Nous appliquerons donc ces patterns au niveau architecture logicielle, afin d’obtenir un couplage faible et une forte cohésion.
De la démultiplication des critères qualité
Commençons par un problème récurrent de l’architecture logicielle qui est de pouvoir gérer l’évolutivité et la résilience. Une première idée est de multiplier les systèmes que ce soit au niveau du front-end ou du back-end. A partir de ce moment, une série de problèmes va se poser. Par exemple, comment gère-t-on les états, que choisir entre stateless et stateful ? Doit-on stocker l’état dans tous les back-ends ou bien doit-on mettre en place une solution de “sticky session” pour retrouver le système qui a enregistré l'état. Cette solution est complexe, elle utilise un équilibreur de charge (load balancer), une gestion d’identifiants supplémentaires, mais que se passe-t-il s’il tombe en panne, si le back-end contenant l’état devient surchargé ?
Faisons alors du stateless avec un cache partagé qui contiendra l’état. Si le cache tombe, on met un cluster, mais cela implique que l’on doit gérer la réplication et la cohérence des données…
C’est l’escalade presque sans fin des patterns Circuit Breaker (Disjoncteur), Bulkheads (Cloisonnement)… (voir notre article Solutions sur étagère pour la gestion des défaillances des Micro-Services)
Afin d’éviter cette course effrénée aux propriétés de qualité, il faut s’intéresser à la volumétrie de l’entreprise concernée : a-t-on besoin d’une surenchère de tels systèmes pour une entreprise de quelques dizaines d’utilisateurs ? A-t-on besoin de temps réel ? Pour la plupart des TPE ou PME, les enjeux ne justifient pas la mise en œuvre de systèmes redondants et hautement performants pour des coûts exorbitants.
Une pléthore de possibilités de découpages
Découpage par couches
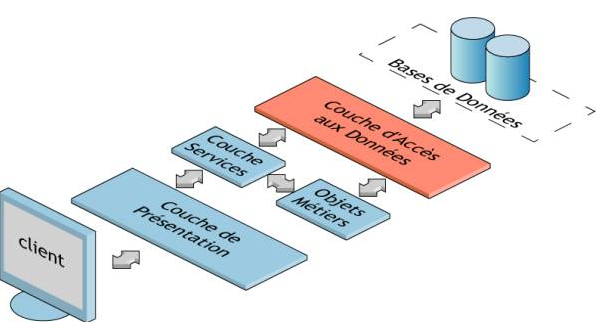
Découpage par couches
Souvent le plus utilisé, le découpage par couche, consiste à séparer l’aspect web (présentation + contrôleur), l’aspect métier (services + règles), DAO (Data Access Object) et enfin la persistance. Le nombre d’appels entre chaque couche est très important et les risques de conflits au moment des commits sont augmentés.
Découpage par technologies
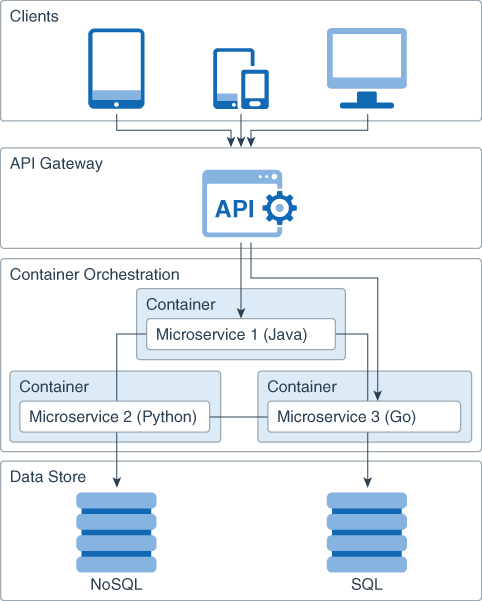
Découpage par technologies
L’exemple typique est d’avoir un existant composé par exemple d’un monolithe Java avec Jakarta EE (anciennement JEE), d’un système plus récent architecturé en micro-services avec Node.js, pour l’IA une architecture Python avec sa cohorte de bibliothèques de Machine ou Deep Learning, les référentiels avec SQL basé sur MySQL ou noSQL basé sur MongoDB… Un couplage fort sera forcément présent, par exemple entre Jakarta EE et MySQL ou Node.js et MongoDB.
Découpage entre entités
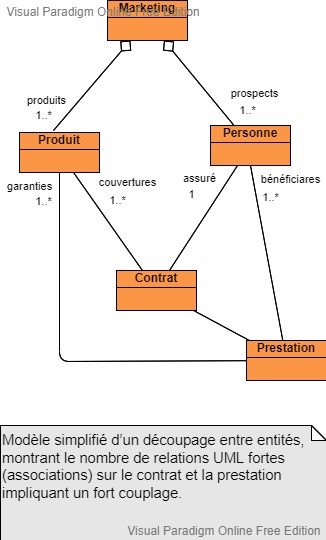
Diagramme UML de classe réalisé avec l'outil gratuit Visual Paradigm
L’architecture micro-services est souvent basée sur ce type de décomposition. A titre d’exemple volontairement simplifié, pris dans le monde assurantiel, on va trouver les micro-services Produit, Personne, Contrat, Prestation…
L’accès aux informations d’un contrat va entraîner de nombreux échanges nécessitant un fort couplage.
Pour calculer une prestation, on a besoin du contrat, de la personne…
Les entités Contrat et Prestation auront besoin de nombreuses données en provenance des entités Produit et Personne, d’où des relations fortes sous forme d’associations UML, ce qui introduit un couplage fort, une augmentation de la bande passante réseau, de CPU, sans oublier les nombreux conflits sur le SCM (Source Control Management).
Mais alors quel découpage préconisé ?
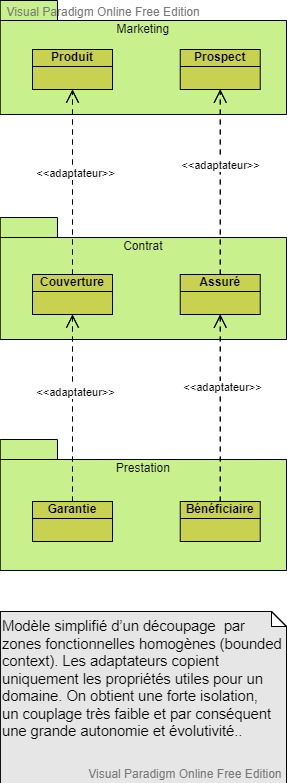
Diagramme UML de classe réalisé avec l'outil gratuit Visual Paradigm
Les décompositions précédentes présentent donc des problèmes de performances, de conflits entre les développements et un fort couplage semblable à une architecture spaghetti.
La bonne solution : le découpage par zones fonctionnelles homogènes (bounded context), regroupant des entités appartenant à un même domaine.
Reprenons notre exemple, on peut constituer 3 domaines fonctionnels homogènes : Marketing (Produit, Prospect), Contrat (Couverture, Assuré) et Prestation (Garantie, Bénéficiaire).
Dans le domaine Marketing, les entités Produit et Prospect deviennent respectivement dans le domaine Contrat, Couverture et Assuré, qui eux-mêmes deviennent Garantie et Bénéficiaire dans le domaine Prestation.
La même personne en chair en os avec la même identité est vue comme prospect dans le marketing, assuré dans le contrat et bénéficiaire dans la prestation.
De même pour un produit dans le marketing, le domaine contrat va utiliser les données de couverture et la prestation les données concernant les garanties.
Cette méthode de regroupement permet d’avoir des zones autonomes. Les liens s’implémentent par des adaptateurs chargés de recopier uniquement les données utiles d’une entité dans une autre.
Mais alors, on viole le principe de non-duplication de données ?
Les adaptateurs copient uniquement les propriétés utiles pour un domaine, c’est le prix à payer pour avoir une forte isolation, un couplage très faible et par conséquent une grande autonomie et évolutivité.
Cette duplication des données se retrouve partout dans la vraie vie, par exemple dans les réseaux sociaux : on a un ami sur Facebook, un candidat sur LinkedIn, un commiter sur Github, un collaborateur sur Slack… Ces différentes plateformes gèrent avec leur propre sémantique la même personne, mais adaptée à leurs objectifs et peuvent partager le même identifiant permettant de se connecter avec un ID Google ou Facebook par exemple.
Le pouvoir de choisir la technologie la plus adaptée
Autre avantage d’une bonne découpe, c’est de pouvoir choisir la technologie la plus adaptée
Prenons l’exemple de la persistance :
- Domaine Marketing regroupant les produits et les prospects : NoSQL favorisant les recherches rapides sur de gros volumes en lecture.
- Domaine Contrat : RDBMS (Relational Database Management System) SQL, pour les aspects transactionnels.
- Domaine Prestation : RDBMS SQL ou Cassandra NoSQL conçu pour gérer des quantités massives de données sur un grand nombre de serveurs, assurant une haute disponibilité en éliminant les points de défaillance unique.
Conclusion
Ce concept de bounded context est de plus en plus considéré et mis en œuvre dans les entreprises et fait partie du DDD Domain Driven Design (voir nos articles Les couches de l'Architecture Microservices et la méthode de conception DDD (Domain Driven Design) et Architecture Hexagonale, exemple de mise en pratique de la méthode DDD Domain Driven Design).
La difficulté consiste à bien délimiter les contours. Pour les identifier, il faudra alors faire appel à l’expérience et à des heuristiques propres.
|
|
Rhona Maxwel @rhona_helena |
“Apprendre à penser, à réfléchir, à être précis (…), à écouter l’autre, c’est être capable de dialoguer, c’est le seul moyen d’endiguer la violence effrayante qui monte autour de nous. La parole est le rempart contre la bestialité.”
Jacqueline de Romilly
Compléments de lecture
- L’Architecture Micro-Services expliquée à ma fille
- Inconvénients de l'Architecture Micro-Services
- Orchestration des micro-services avec BPMN
- Conseils pour réussir vos micro-services et éviter qu’ils ne se transforment en véritable pensum
- Estimation de la complexité d’une Architecture Micro-Services
- Solutions sur étagère pour la gestion des défaillances des Micro-Services
- Comment éviter la loi de Conway et faciliter ainsi l’agilité avec l’approche Micro-Services ?
- Les couches de l'Architecture Microservices et la méthode de conception DDD (Domain Driven Design)
- Architecture Hexagonale, exemple de mise en pratique de la méthode DDD Domain Driven Design
- Urbanisation, SOA et BPM d’Yves Caseau
Avec toutes les nouvelles techniques de RIA (Rich Internet Application), y a de quoi y perdre son Java !
1) ExtJS est la technique la plus tendance avec le pattern MVC (Model View Controller) implémenté au niveau client avec une bibliothèque Javascript, distribué par la société Sencha, permettant de construire des applications web interactives. C'était, au départ, une extension à la bibliothèque Javascript YUI de Yahoo.
ExtJs apporte un certain nombre de composants visuels d'une grande qualité comme des champs de formulaires avancés, des arbres, des tableaux, des panels, des fenêtres, des onglets, des boîtes de dialogue... Il facilite aussi la gestion des évènements, du glisser déplacer (drag and drop), des requêtes Ajax et le support de plusieurs formats d'échange de données comme le XML ou le Json.
En plus d'apporter une multitude de composant pour le développement web, ExtJs change le concepts de la programmation pour le web. En effet, avec ExtJs, la programmation web se rapproche beaucoup plus du logiciel client : Généralement dans les développements pour le web, le langage serveur est le pilote de l'application. C'est lui qui génère la couche graphique. Avec ExtJs, le langage pilote est le Javascript. C'est votre interface graphique qui va appeler le langage serveur lorsqu'il aura besoin de récupérer des données en base.
ExtJS 4 est une avancée révolutionnaire dans le développement d'applications web. Presque tous les composant principaux ont été améliorées, dans de nombreux cas de façon drastique. Il y a également de nombreux composants et sous-systèmes neufs depuis ExtJs3.
ExtJs4 supporte tous les navigateurs principaux depuis internet explorer6 jusqu'aux dernières version de Google Chrome.
Vous n'avez pas besoin de serveur WEB pour faire fonctionner EXTJS4 mais cela est vivement conseillé.
2) GWT propose de nombreuses fonctionnalités pour développer une application exécutable dans un navigateur et présentant des comportements similaires à ceux d'une application desktop :
- création d'applications graphiques s'exécutant dans un navigateur
- pas besoin d'écrire du code Javascript sauf pour des besoins très spécifiques comme l'intégration d'une bibliothèque JavaScript existante
- utilisation de CSS pour personnaliser l'apparence
- mise en oeuvre d'Ajax sans manipuler l'arbre DOM de la page mais en utilisant des objets Java
- un ensemble riche de composants (widgets et panels)
- communication avec le serveur grâce à des appels asynchrones en échangeant des objets Java et en utilisant des exceptions pour signifier des problèmes
- internationalisation
- un système de gestion de l'historique sur le navigateur
- un parser XML
- détection des erreurs à la compilation
- ...
L'utilisation de GWT présente plusieurs avantages :
- pas de code JavaScript à écrire
- utilisation de Java comme langage de développement
- une meilleure productivité liée à l'utilisation du seul langage Java (un seul langage à utiliser, mieux connu que d'autres technologies notamment JavaScript, mise en oeuvre d'un débogueur, utilisation d'un IDE Java, ...)
- hormis les styles CSS et la page HTML qui encapsule l'application, il n'y a pas d'utilisation directe de technologies web
- le code généré par GWT supporte les principaux navigateurs
- la prise en main est facile même pour des débutants ce qui lui confert une bonne courbe d'apprentissage
Le code de l'application est entièrement écrit en Java notamment la partie cliente qui devra s'exécuter dans un navigateur. Ce code Java n'est pas compilé en bytecode mais en JavaScript ce qui permet son exécution dans un navigateur.
Le coeur de GWT est donc composé du compilateur de code Java en JavaScript. L'avantage du code JavaScript produit est qu'il est capable de s'exécuter sur les principaux navigateurs sans adaptation particulière du source Java puisque le compilateur crée un fichier JavaScript optimisé pour chacun de ces navigateurs.
Google s’est désisté officiellement du projet et en a donné la responsabilité à un comité (GWT Steering Committee). Les objectifs majeurs :
- Plus de rapidité dans la compilation, développement…
- Support Java 7, 8
- Découpage du projet pour une meilleure intégration Maven
- Amélioration du rendu sur Mobile
- Correction des TOP 100 bugs GWT
- Déprécation de IE6, 7 et 8
3) PrimeFaces, l’intérêt principal réside dans la diversité et la qualité des composants proposés. Ils sont nombreux, plus de 100, et répondent le plus souvent en standard aux besoins des applications. Ce sont des composants graphiques avancés qui possèdent des fonctionnalités prêtes à l’emploi, aidant ainsi à créer aisément des RIA (Rich Internet Application). L’ensemble des composants est présenté dans une page de démonstration, avec le code (à la fois xhtml et Java) s’y rapportant.
Il existe 13 catégories de composants :
- Ajax Core : les fonctionnalités ajax de PrimeFaces
- Input : De composant d’entrée utilisateur
- Button : Remplacement des boutons de JSF
- Data : Présentation des données
- Panel : Mise en page
- Overlay : Fenêtre de dialog
- Menu : Menus contextuels
- Charts : Graphiques
- Message : Messages destinés à l’utilisateur
- Multimedia : Intégration avec des images, utilisation d’une webcam,
- File : Upload et download de fichier
- DragDrop : Déplacement d’élément du DOM
- Misc : Catégorie fourre-tout (lecteur de flux rss, Captcha)
Comme certains pourraient le constater, les composants graphiques ressemblent à ceux de jQuery ui, puisqu’ils étaient à la base des encapsulations de ces derniers. De cette encapsulation il reste les classes css et la structure html du composant. C’est un gage de qualité de rendu des composants.
Par ailleurs, le code généré est simple, lisible et évite (contrairement à RichFaces) l’utilisation de tableaux pour la mise en page, ce qui est un plus indéniable.
Il est à noter que l’utilisation d’ajax est très présente dans PrimeFaces. Par exemple, l’action déclenchée par les boutons qu’il propose est par défaut en ajax.
J'ai pu constater qu'il y a des afficionados de l'une et de l'autre, chacun ayant tous les bons arguments pour critiquer l'autre. Il ne faudra donc pas céder aux tendances de modes ou de buzz, garder la tête froide et faire en sorte que le pragmatisme et le contexte de votre projet l'emporte dans les critères de choix.
"De la discussion jaillit la lumière"
Voir aussi : http://urbanisation-si.over-blog.com/
http://urbanisation-des-si.blogspot.fr/
http://urbanisation-si.eklablog.com/
A ma gauche Hibernate version 4.3.6 contre MyBatis version 3.2.8, qui va remporter le titre 2014 de champion ORM toute catégorie ?
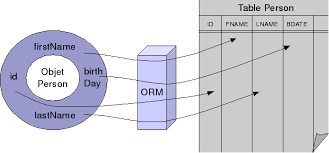
Hibernate est l'outil standard d'ORM (Object Relational Mapping), pour avoir une correspondance entre un modèle objet et un modèle relationnel (SQL).
Une des forces d'Hibernate est sa gestion de cache de niveau 1. Quand on demande à Hibernate de récupérer un objet, par défaut, il procède à un chargement paresseux (lazy loading) c'est à dire que tout le graphe objet n'est pas chargé en mémoire. Dans les relations 1 à plusieurs, les collections ne sont pas chargées. Hibernate a ses propres proxy permettant à la demande de charger véritablement les collections d'objets. Une des critiques à l'encontre du choix d'Hibernate au profit de MyBatis, est le fait qu'on ne peut pas synchroniser le cache de niveau 1 lorsqu'il est accédé par plusieurs applications comme c'est le cas dans la cohabitation d'anciennes applications Mainframe avec des nouvelles utilisant Java. C'est totalement inexacte, le cache peut être rafraîchi ( API refresh() ). Mais quand on se pose ce genre de questions, c'est la misère, c'est vraiment qu'on ne s'est pas posé les bonnes questions dés le départ sur l'architecture fonctionnelle et applicative. D'autre part Hibernate est le champion de la mise en oeuvre simplissime pour la gestion des accès concurrentiels avec les verrous optimistes (optimistic lock). Ce système classique consiste à gérer un numéro de version dans une colonne de la table SQL. Par exemple on récupère une ligne avec la version 10, on met à jour en mettant comme critère numéro de version = 10 qu'on va mettre à jour avec 11. Si quelqu'un d'autre entre temps a mis à jour avant vous, le numéro est déjà passé à 11 donc votre mise à jour échouera. D'une manière statistique, il se peut que le plus souvent vous soyez le seul à mettre à jour et dans ce cas tout marchera correctement.
Hibernate nécessite de solides compétences en persistances et sur l'architecture du framework (la gestion de la session, le lazy loading, ...). Si les développeurs ne maîtrisent pas Hibernate et la norme JPA (Java Persistance API : JPA est à l'ORM ce que JDBC (Java Data Base connectivity) est au accès aux bases SQL pour les programmes Java).
MyBatis est du JDBC amélioré ! Il ne posséde pas de langage de requêtes objet comme le HQL (Hibernate Query Language) d'Hibernate, permettant de faire du zéro SQL et de rester 100 % objet. L'avantage donc de MyBatis est de rester plus proche du SQL. Mais le problème d'accès concurrentiels reste le même avec MyBatis, il n'y a pas d'objets JDBC qui gardent les objets en mémoire !
Pour des besoins simples avec une équipe peu rodée aux piéges des ORM, maîtrisant parfaitement SQL, MyBatis s'impose. Par contre pour les gros projets, dans le cas de la normalisation de l'architecture technique pour toutes les applications d'un SI urbanisé, Hibernate est le grand gagnant des solutions ORM.
"Connaître autrui n'est qu'une science ; se connaître, c'est l'intelligence."
Voir aussi : http://urbanisation-si.over-blog.com/
http://urbanisation-des-si.blogspot.fr/
http://urbanisation-si.eklablog.com/
11/11 Projet informatique, passer du moyen âge à l'ère industrielle. Devenez parano en vérifiant chaque jour votre développement logiciel avec l'intégration en continue.
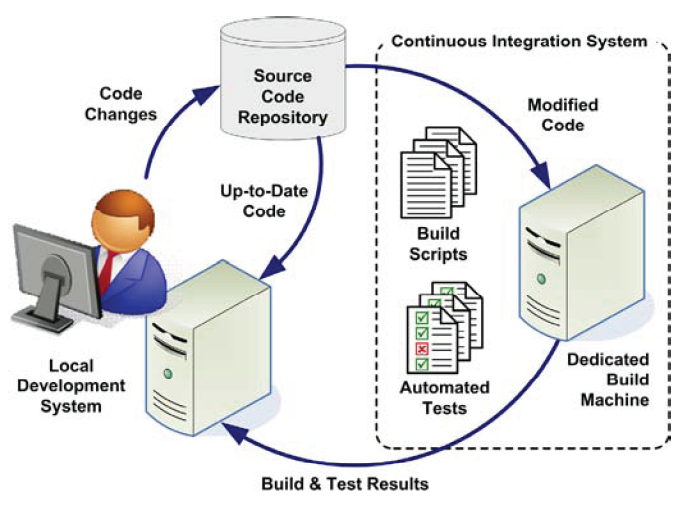
N'attendez surtout pas que les développements soient commencés pour mettre en place la plate forme d'intégration continue car vous risqueriez de "brûler du gaz" pour rien. Au contraire investissez dés le départ et soyez audacieux et innovateur, ce sont les clés du retour sur investissement.
En fait l'objectif c'est de rechercher la sérénité. En effet en investissant au départ dans les vérifications automatiques journalières c'est pouvoir dormir comme un bébé chaque nuit.
Chaque évolution ou modification du code peut engendrer des régressions. N'est il pas rageant de s'apercevoir qu'une fonctionnalité complexe difficile à mettre au point et dûment testée ne marche plus ! L'automatisation des tests de régression exécutés au moins une fois par jour permet de voir au plus tôt ce qui ne va pas et empêche d'ajouter des nouvelles fonctionnalités qui ne feraient qu'aggraver la situation.
Mais que doit faire la plate forme?
Tout d'abord récupérer le code source, depuis le dépôt qui est la plupart du temps un outil de gestion de source (CVS, SVN, Git, SourceSafe, …).
Ensuite vérifier et optimiser le code par des outils d'audit (voir mon article : 9/11 Projet informatique, passer du moyen âge à l'ère industrielle. Comment vérifier que les développeurs n'ont pas mijoté un plat de spaghetti ? (qualité du code, audit, style, ...)
Bien évidement, il faut compiler des sources. Si un projet ne peut pas être compilé complètement, il faut remonter rapidement l’information, pour que le code problématique soit corrigé. Un projet qui ne compile pas peut bloquer l’ensemble des développeurs qui travaillent dessus.
Puis passer les tests unitaires et générez un rapport avec les messages liés aux tests en échecs.
Préparer les artefacts de déploiement de manière à ce que l'application puisse être exécutée dans l'environnement cible.
Déployer l’application sur le serveur d'application cela peut se résumer à une simple copie des artefacts de déploiement. Tous les fichiers de log doivent être activés pour pouvoir analyser si besoin est les erreurs de déploiement. Ce qui parfois peut se révéler difficile à réaliser tellement les facteurs peuvent être nombreux.
On termine par les tests fonctionnels correspondant aux Use Case. Un rapport structuré doit être généré.
Et qu'est ce qu'on oublie ? La génération automatique de la documentation de développement, qui est faite à partir des informations présentes dans le code source. C'est toujours plus facile de développer quand on a sous la main une version à jour de la documentation.
À la fin de l’exécution de toutes ces actions, la plate-forme doit envoyer des messages aux personnes concernées par les problèmes relevés. Ces messages ne doivent pas se transformer en spam, car ils deviendraient inutiles (personne n’y ferait plus attention). Il faut donc faire attention à remonter les vrais problèmes, et ne pas mettre tous les développeurs en copie sauf dans les cas nécessaires.
La résolution des bugs remontés doit être lapriorité première d’une équipe de développement. C’est simple, si on continue à développer en sachant qu’il y a des bugs, on sait pertinemment qu’il faudra encore plus de temps et d’énergie pour les corriger, tout en risquant de devoir refaire les « sur-développements ».
En bout de course, l’application déployée par l’intégration continue doit être accessible à l’équipe de test, qui peut ainsi procéder à ses vérifications complémentaires sans avoir à se soucier des étapes techniques en amont (compilation, packaging, déploiement).
Mettre en place une plate-forme d’intégration continue est un tâche technique assez longue. Mais une fois que c’est fait, c’est à la fois un confort de travail et une sécurité dont on ne peut plus se passer.
L’écriture des tests unitaire est quelque chose d’un peu fastidieux, qu’il est souvent difficile d’imposer à une équipe qui a pris de mauvaises habitudes. Un développeur ne voit souvent le code source comme seul élément constitutif de son travail, et oublie la documentation et les tests. Encourager l’écriture de tests unitaire est un travail de longue haleine sur lequel il faut maintenir une pression constante, sous peine de laisser prendre la poussière. Et un test qui n’est pas tenu à jour devient rapidement inutile.
N'attendez surtout pas que les développements soient commencés pour mettre en place la plate forme d'intégration continue car vous risqueriez de "brûler du gaz" pour rien. Au contraire investissez dés le départ et soyez audacieux et innovateur, ce sont les clés du retour sur investissement.
Voir aussi : Bonnes pratiques des SI
10/11 Projet informatique, passer du moyen âge à l'ère industrielle. Ne jouez pas perso, travaillez en équipe.
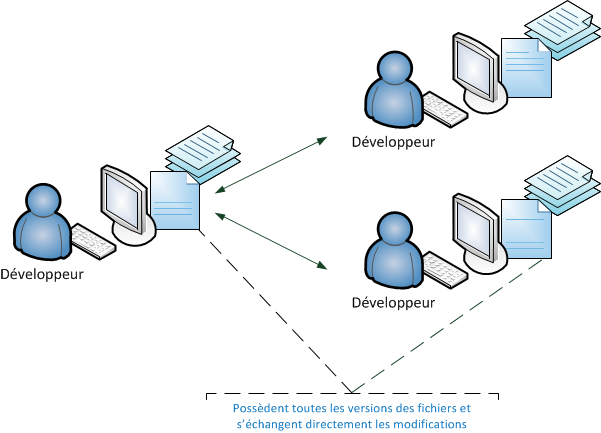
Pendant les phases d'inception et d'élaboration des méthodes UP (Unified Process), la discipline "Environnement" permet la mise en place des outils pour l'ensemble des acteurs du projet. Un logiciel de type GCL (Gestionnaire de Configuration Logiciel) ou VCS (Version Control System) a pour but de partager les sources, de gérer des versions et d'éventuels conflits dans un même bloc de code. Il y a quelques années, pour un projet de gestion de clients, j'étais intervenue pour mettre en place une nouvelle méthode de gestion de projet s'appuyant sur UP. Je formais alors les différents profils, chef de projet, experts métier, analystes et développeurs aux concepts d'itération, de gestion du changement, de phases et disciplines du processus unifié, de la modélisation UML, des processus métier, des Use Case, de la méthode d'estimation basée sur les UC... Une des priorités étant de valider l'architecture, j'avais recommandé Eclipse comme IDE (Environnement de Développement Intégré) ainsi que de mettre tout de suite un serveur avec Subversion qui était à l'époque le standard open source des GCL. Mais le client à ses raisons que le consultant ne connaît pas. L'outil de développement retenu fut jDeveloper d'Oracle et la mise en place de la gestion de versions fut différée pour des problèmes internes. Le projet était composé de 2 équipes de développeurs l'une à Paris et l'autre à Dijon. La "réseautique" devait installé une nouvelle ligne et configurer les firewalls pour gérer la sécurité. J'alertais sur le fait qu'il y aurait un gros risque pour recentraliser tous les sources de Paris et Dijon dans 6 mois, qu'il y aurait des conflits et d'énormes différences ingérables manuellement. Malgré ma désapprobation le projet démarra sans GCL ! Je structurais alors les fonctionnalités entre le sites de Paris et Dijon dans des domaines fonctionnels indépendants et les répartis entre Paris et Dijon. Les interdépendances furent bouchonnées. . Voilà vraiment la chose à ne pas faire, laissez 5 développeurs produire du code sans gestion de version. Le client aurait du mettre en place le système de GCL dés l'étude de faisabilité du projet.
Les GCL permettent de mettre à jour ses sources à partir des modifications des autres développeurs. Et réciproquement d'enregistrer ses propres modifications pour qu'elles puissent être récupérées par l'équipe Le référentiel peut être distribué, c'este cas des outils les plus modernes comme Git (développé par Monsieur Linux Linus Torvald en personne). A partir de la version courante de l'application, celle qui évolue, appelée trunk, on peut sauvegarder des clichés(tags) correspondants par exemple à des versions stables livrées, on peut créer des branches à partir du trunk qui suivront leurs propres évolutions pour des clients différents. Lorsque 2 développeurs modifient le même bloc de code par exemple simultanément, il y a alors conflit. Tous les commits seront représentés entourés de marqueurs, il s'agira alors pour un développeur de trancher en validant une version du code et en supprimant les autres. On doit pouvoir accéder à un historique complet de tous les commits effectués et éventuellement pouvoir revenir à une ancienne version ou annuler le dernier commit.
La grande nouveauté dans les GCL réside dans la distribution du référentiel (DVCS en anglais pour Distributed Version Control Systems). Dans un DVCS (tel que Git, Mercurial, Bazaar ou Darcs), les clients n'extraient plus seulement la dernière version d'un fichier, mais ils dupliquent complètement le dépôt. Ainsi, si le serveur disparaît et si les systèmes collaboraient via ce serveur, n'importe quel dépôt d'un des clients peut être copié sur le serveur pour le restaurer. Chaque extraction devient une sauvegarde complète de toutes les données. De plus, un grand nombre de ces systèmes gère particulièrement bien le fait d'avoir plusieurs dépôts avec lesquels travailler, vous permettant de collaborer avec différents groupes de personnes de manières différentes simultanément dans le même projet. Cela permet la mise en place de différentes chaînes de traitement qui ne sont pas réalisables avec les systèmes centralisés, tels que les modèles hiérarchiques.
Comme le préconise les méthodes UP, l'architecture et l'environnement doivent être stabilisés dés les premières phases d'initialisation et d'élaboration. Le système de gestion de version doit être opérationnel immédiatement, sinon gare à la facture salée du rattrapage manuel.
Voir aussi : http://bonnes-pratiques-si.eklablog.com/