
Event Driven Architecture EDA
Avec l'Event Driven Architecture (EDA), les avantages sont nombreux. Citons l'indépendance totale des producteurs et des consommateurs qui sont complétement dissociés, les consommateurs peuvent répondre immédiatement aux événements dès leur arrivée, l'architecture est hautement scalable et distribuée, les sous-systèmes ont des vues indépendantes du flux d’événements.
Un problème cornélien de l’EDA, Event Driven Architecture, est de s’assurer de l’exactitude sémantique de livraison d’un message, Kafka l’aurait-il résolu ?
Comment gérer l’idempotence de l’envoi d’un même message ?
La non réception d’un accusé signifie que le broker (serveur de messages asynchrones) n’a pas pu écrire le message et dans ce cas il faut que le producteur l’envoie à nouveau ce qui correspond au mode de livraison “au moins un”.
Ou bien le broker l’a bien écrit mais un dysfonctionnement est survenu juste après l'empêchant d’envoyer l’accusé auquel cas le producteur le renverra en double, correspondant au mode de livraison “au plus un”.
Tel est le dilemme cornélien auquel l’EDA est confrontée. Disruptif, l’open source Kafka tente d’apporter des solutions, y parvient-il réellement ?
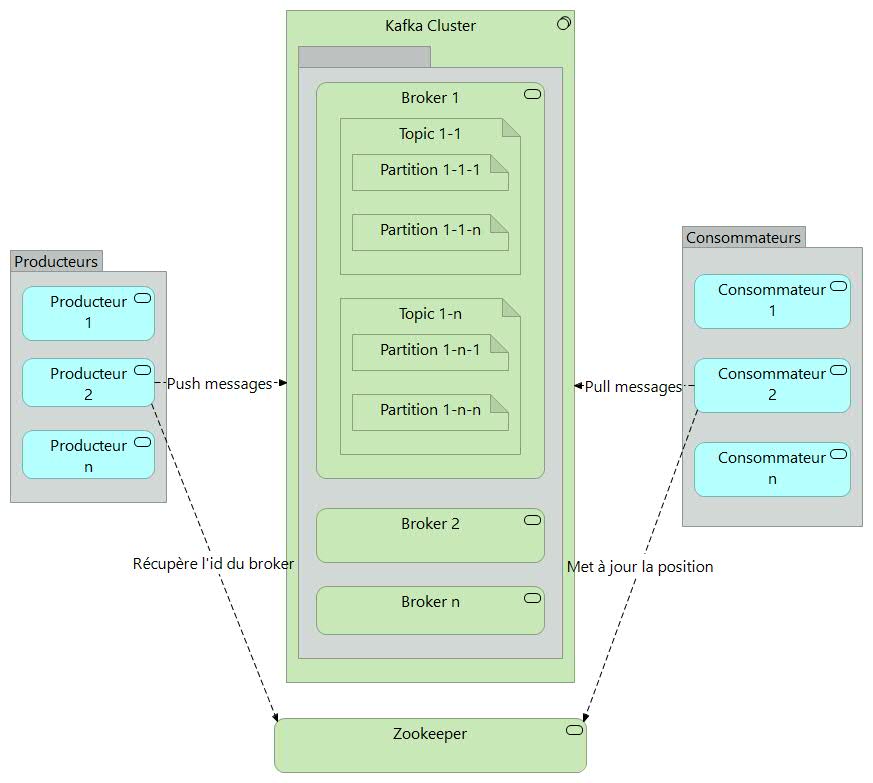
Architecture Apache Kafka
Scénario nominal
Soit une application (producteur) implémentant le processus d’ouverture de dossier de prestation d’assurance qui envoie un message de création d’un nouveau dossier sinistre à un topic (entité Kafka, similaire à un dossier dans un système de fichiers où les événements sont les fichiers de ce dossier).
Supposons maintenant qu’une autre application (consommateur) extrait les données et crée une action dans la corbeille applicative du gestionnaire chargé de créer les nouveaux dossiers sinistres.
Dans une journée idéale, sans dysfonctionnement, le message est écrit exactement une seule fois sur la partition du topic. L’application consommatrice extrait le message, le traite et indique que l’action est terminée. Même si cette application se bloque et redémarre, elle ne recevra pas à nouveau le message.
La probabilité de défaillances des systèmes augmente à forte volumétrie.
Un broker (serveur) peut tomber en panne. Kafka est un système hautement disponible, persistant et durable où chaque message écrit sur une partition est persistant et répliqué..
Mais que se passe-t-il en cas de panne totale ?
La question critique pour un système de traitement de flux est la suivante : "Est-ce que mon application de traitement de flux obtient la bonne réponse, même si l'une des instances tombe en panne au milieu du traitement ? " La clé, lors de la récupération d'une instance défaillante, est de reprendre le traitement exactement dans le même état qu'avant le crash.
Maintenant, le traitement de flux n'est rien d'autre qu'une opération de lecture-traitement-écriture sur un topic Kafka ; un consommateur lit les messages d'un topic Kafka, une logique de traitement transforme ces messages ou modifie l'état maintenu par le processeur, et un producteur écrit les messages résultants dans un autre topic Kafka.
Une opération de lecture-traitement-écriture doit être exécutée exactement une fois.
Dans ce cas, obtenir la bonne réponse signifie ne manquer aucun message d'entrée ou produire une sortie en double. Le comportement qu’attendent les utilisateurs correspond au mode “exactement un” qui garantit qu’un message soit bien délivré, et ce une seule fois.
L'arme fatale : des topics transactionnels
Le journal des transactions est un topic Kafka et fournit les garanties ACID (Atomicité, Cohérence, Isolation et Durabilité).
Le moniteur transactionnel, qui gère l'état de la transaction par producteur, s'exécute au sein du broker et en cas de panne, s'appuie naturellement sur l'algorithme d'élection du système maître de Kafka qui gère les réplications.
Pour les applications de traitements de flux créées à l'aide de l'API Streams, Kafka tire parti du fait que le référentiel d'états et des positions dans le journal sont des topics Kafka.
Ces données sont embarquées de manière transparente dans des transactions qui écrivent de manière atomique sur plusieurs partitions, et qui fournissent la garantie de les traiter exactement une fois pour les flux, à travers les opérations de lecture-traitement-écriture.
Des tests de chaos distribués ont été réalisés dans un cluster Kafka complet avec plusieurs clients transactionnels. Des messages ont été produits de manière transactionnelle, puis lus simultanément, tandis que les les clients et les serveurs étaient arrêtés pendant le processus afin de s’assurer que les données n’étaient ni perdues ni dupliquées.
Les différentes garanties de livraison de message
- Au plus une fois : les messages peuvent être perdus mais ne sont jamais redistribués.
- Au moins une fois : les messages ne sont jamais perdus mais peuvent être renvoyés.
- Exactement une fois : c'est ce que l’on veut réellement, chaque message est délivré une fois et une seule.
A noter que cela se décompose en deux problèmes : les garanties de pérennité pour la publication d'un message et les garanties lors de la consommation d'un message.
La plupart des systèmes fournissent une sémantique de livraison "exactement une fois",
mais ne gèrent pas le cas où les consommateurs ou les producteurs peuvent tomber en panne, les cas où il y a plusieurs processus consommateurs ou encore les cas où les données écrites sur disque peuvent être perdues.
Stratégies mise en œuvre côté producteur
Lors de la publication d'un message, une information est commitée dans le journal. Une fois qu'un message publié est validé, il ne sera pas perdu tant qu'un broker qui réplique la partition sur laquelle ce message a été écrit reste actif.
Si un producteur tente de publier un message et rencontre une erreur réseau, il ne peut pas être sûr si cette erreur s'est produite avant ou après la validation du message.
Pour de nombreux systèmes, si un producteur ne reçoit pas de réponse indiquant qu'un message est validé, il n'a d'autre choix que de renvoyer le message. Cela fournit une sémantique de livraison “au moins une fois” puisque le message peut être réécrit dans le journal lors du renvoi si la demande d'origine a en fait réussi.
Avec Kafka, le producteur prend en charge une option de livraison idempotente qui garantit que le renvoi n'entraînera pas d'entrées en double dans le journal. Pour ce faire, le broker attribue à chaque producteur un identifiant et déduplique les messages à l'aide d'un numéro de séquence envoyé par le producteur avec chaque message.
Le producteur prend également en charge la possibilité d'envoyer des messages à plusieurs partitions de topic en utilisant un système de transaction : c'est-à-dire, soit tous les messages sont écrits avec succès ou soit aucun d'entre eux ne l'est. Le principal cas d'utilisation pour cela est la sémantique de traitement “exactement une fois” entre les topics Kafka.
Des options permettent au producteur de spécifier le niveau de durabilité qu'il souhaite. Cependant, le producteur peut également spécifier qu'il souhaite effectuer l'envoi de manière complètement asynchrone ou qu'il souhaite attendre uniquement que le système primaire (maître) ait le message, mais pas nécessairement les systèmes secondaires.
Stratégies mise en œuvre côté consommateur
Toutes les répliques ont exactement le même journal avec les mêmes positions. Le consommateur contrôle sa position dans ce journal. Si le consommateur n’a jamais subi de pannes, il pourrait simplement stocker cette position en mémoire, mais si le consommateur échoue et que cette partition de topic doit être prise en charge par un autre processus, celui-ci devra choisir une position appropriée à partir de laquelle commencer le traitement.
Si par exemple, le consommateur lit certains messages, il dispose de plusieurs options pour traiter les messages et mettre à jour sa position.
Il peut lire les messages, puis enregistrer sa position dans le journal, et enfin traiter les messages. Dans ce cas, il est possible que le processus consommateur se bloque après avoir enregistré sa position mais avant d'avoir enregistré la sortie de son traitement de message. Dans ce cas, le processus qui a repris le traitement commencera à la position enregistrée même si quelques messages antérieurs à cette position n'avaient pas été traités. Cela correspond à la sémantique "au plus une fois" car dans le cas d'une panne du consommateur, les messages peuvent ne pas être traités.
Il peut lire les messages, traiter les messages et enfin enregistrer sa position. Dans ce cas, il est possible que le processus consommateur se bloque après avoir traité les messages mais avant d'avoir enregistré sa position. Dans ce cas, lorsque le nouveau processus prendra le relais, les premiers messages qu'il recevra auront déjà été traités. Cela correspond à la sémantique "au moins une fois" en cas de défaillance du consommateur. Dans de nombreux cas, les messages ont une clé primaire et les mises à jour sont donc idempotentes ce qui signifie que deux réceptions du même message, écrase simplement un enregistrement avec une autre copie de lui-même..
Le mode "exactement un"
Lors de la consommation à partir d'un topic Kafka et de la production vers un autre topic (comme dans une application Kafka Streams), les nouvelles fonctionnalités de producteur transactionnel entrent en action.
La position du consommateur est stockée sous forme de message dans un topic, on peut donc écrire la position dans Kafka dans la même transaction que les topics de sortie recevant les données traitées. Si la transaction est abandonnée, la position du consommateur reviendra à son ancienne valeur et les données produites sur les topics de sortie ne seront pas visibles pour les autres consommateurs qu'en fonction de leur "niveau d'isolement".
Dans le niveau d'isolement par défaut "read_uncommitted", tous les messages sont visibles pour les consommateurs même s'ils faisaient partie d'une transaction abandonnée, mais dans "read_committed", le consommateur ne renverra que les messages des transactions qui ont été validées et tous les messages qui ne faisaient pas partie d'une transaction.
Commit à 2 phases pour les systèmes externes
Exemples de connecteurs Kafka Connect
Lors de l'écriture sur un système externe, la limitation réside dans la nécessité de coordonner la position du consommateur avec ce qui est réellement stocké en tant que sortie. La manière classique d'y parvenir serait d'introduire un commit à deux phases entre le stockage de la position du consommateur et le stockage de la sortie du consommateur.
Mais comme de nombreux systèmes de sortie sur lesquels un consommateur peut vouloir écrire ne prennent pas en charge un commit à deux phases, il est préférable de laisser le consommateur stocker sa position au même endroit que sa production.
Par exemple, un connecteur Kafka Connect qui remplit les données dans HDFS (Hadoop Distributed File System, est un système de stockage faisant partie de Apache Hadoop, le framework open source standard utilisé dans le Big Data), avec les positions des données qu'il lit afin de garantir que les données et les positions sont tous les deux mis à jour ou qu'aucun ne l'est.
Conclusion
Le support complet des transactions par le producteur et le consommateur lors du transfert et du traitement des données entre les topics Kafka, permet d’assurer la livraison en mode “exactement un” qui garantit qu’un message soit bien délivré, et ce une seule fois, le dilemme cornélien exposé en début de cet article est donc résolu.
A part la spécificité fondamentale précédente, voici les autres critères discriminants par rapport aux produits classiques de l’EDA comme ActiveMQ et RabbitMQ :
- supporte des débits très importants
- système de messagerie en mode “pull”, le consommateur extrait les messages du broker
- conserve les messages sur une durée paramétrable
- un consommateur peut rembobiner vers une ancienne position et re-consommer les données
- fonctionnalité de compactage
- Kafka Streams apporte la possibilité d’effectuer des traitements parallélisés sur des messages en flux continus
- de nombreux connecteurs, basés sur Kafka Connect, permettent de transférer facilement de gros volumes de données en provenance ou vers de multiples systèmes
- possibilité de capturer tous les événements impliquant un changement d’état d’un composant du SI
Ces innovations par rapport à l’existant montre bien que Kafka a le potentiel d’une technologie de rupture. Et en tant que tel, il pourrait bien contribuer au développement de l’EDA comme l’indique Forrester dans ses prévisions pour 2022.
|
|
Rhona Maxwel @rhona_helena |
“La jeunesse est heureuse parce qu'elle a la capacité de voir la beauté. Quiconque conserve la capacité de voir la beauté ne vieillit jamais.”
Franz Kafka
Compléments de lecture
- Les couches de l'Architecture Microservices et la méthode de conception DDD (Domain Driven Design)
- Architecture Hexagonale, exemple de mise en pratique de la méthode DDD Domain Driven Design
- L’Architecture Micro-Services expliquée à ma fille
- Inconvénients de l'Architecture Micro-Services
- Orchestration des micro-services avec BPMN
- Conseils pour réussir vos micro-services et éviter qu’ils ne se transforment en véritable pensum
- Estimation de la complexité d’une Architecture Micro-Services
- Solutions sur étagère pour la gestion des défaillances des Micro-Services
- Comment éviter la loi de Conway et faciliter ainsi l’agilité avec l’approche Micro-Services ?
- Les couches de l'Architecture Microservices et la méthode de conception DDD (Domain Driven Design)
- Le projet d'urbanisation du SI de Christophe Longépé