
Architecture Micro-Services
Le nouveau style d’architecture pour concevoir des applications informatiques, voire pour urbaniser enfin le Système d’Information de l’entreprise.
L’Architecture Micro-Services expliquée à ma fille
Le nouveau style d’architecture pour concevoir des applications informatiques, voire pour urbaniser enfin le Système d’Information de l’entreprise.

C’est le premier article d’une nouvelle série qui vise à expliquer l’Architecture Micro-Services.
Evolution de l’architecture logicielle
Tentons de résumer l’évolution de l’architecture logicielle en trois grandes étapes, forcément réductrices, qui ont mené à l’Architecture Micro-Services :
1- Architecture monolithique
A la fin du 20e siècle, les applications informatiques développées étaient monolithiques, c.-à-d. constituées d’un seul bloc, parfois très gros. Ce qui n’empêchait pas la programmation modulaire. Seul le stockage des données, centralisé, était confié à un Système de Gestion de Base de Données (SGBD).
De nombreuses applications monolithiques sont encore en production aujourd’hui (souvent une application monolithique par domaine métier), tellement cloisonnées entre elles que l’on parle alors d’architecture en silos.
2- Architecture Orientée Services
Au début du 21e siècle, disons vers 2005, un premier effort de partitionnement a été effectué avec l’Architecture Orientée Services (SOA), pour supporter l’avènement des processus métier et leur orchestration. Les données étaient toujours centralisées dans un SGBD.
Les solutions techniques mises en œuvre, peut-être trop lourdes (protocole SOAP et autres Web Services sur un ESB - Enterprise Service Bus), n’ont pas permis à la SOA de rencontrer le succès escompté : son usage s’est souvent limité aux gros projets dans les grandes entreprises.
3- Architecture Micro-Services
Le terme micro-service fut utilisé pour la première fois en 2011, lors d’une conférence pour les architectes. Un des objectifs était de proposer un mécanisme de mise à l’échelle (scaling) plus performant et surtout plus flexible pour faire face à l’accroissement du nombre de visites des sites web les plus populaires (Amazon, eBay, Google, Netflix).
Au lieu de dupliquer en entier des applications monolithiques, il s’agit désormais de distribuer, et même de dupliquer, certains micro-services uniquement, sur différents serveurs. Tout en gagnant en flexibilité et en agilité, pour effectuer plus rapidement des changements, le plus souvent des améliorations.
Une application partitionnée en micro-services est plus robuste qu’une application monolithique. Un micro-service en panne ne bloque pas forcément toute l’application, qui devient alors résiliente.
C’est une évolution de la SOA (Service Oriented Architecture) : certains parlent de l’Architecture Micro-Services comme la SOA à grains fins. Elle ne remet pas en cause la SOA, mais propose des solutions techniques plus légères, souvent Open Source, comme RESTful notamment.
Principes de l’Architecture Micro-Services
C’est un style d’architecture dont l’approche est de :
- concevoir une application en une suite de petits services, appelés micro-services,
découplés le plus possible les uns des autres,
- chaque micro-service :
- répond à une fonctionnalité métier unique,
- est simple ou moins complexe,
- est indépendant, voire autonome,
- s’exécute dans son propre processus,
- dispose de sa propre base de données,
- peut être développé dans un langage de programmation quelconque,
- communique avec un protocole léger,
- est déployable indépendamment des autres,
- est déployable de façon continue et automatisée,
- la gestion centralisée des micro-services doit être réduite au strict minimum
(service discovery, par exemple ; il s’agit d’un dispositif pour découvrir les services).
Le fait que chaque micro-service doit disposer de sa propre base de données est sans aucun doute la différence principale avec l’Architecture SOA et provoque un fort impact sur la conception.
Partitionnement et granularité
L’Architecture Micro-Service se doit de répondre à une question primordiale : Comment partitionner une application volumineuse ou le Système d’Information de l’entreprise en micro-services ? Et ce partitionnement a son pendant : quelle granularité pour ces micro-services ?
Si vous comptez sur The Open Group (l’auteur de TOGAF) pour connaitre la bonne granularité d’un micro-service, vous serez fort déçu : « les bons micro-services sont situés entre les monolithes et les nanoservices ». Nous n’osons pas reproduire ici le diagramme lapalicien associé à cette affirmation, visible à cette adresse https://www.opengroup.org/soa/source-book/msawp/p6.htm.
Le partitionnement en tant que tel ne doit pas être un objectif, mais la conséquence de l’application des principes de l’Architecture Micro-Services. La démarche à suivre sera sans doute différente selon qu’il s’agisse de refondre une application monolithique existante (et même tout le Système d’Information de l’entreprise) ou de concevoir une nouvelle application en partant d’une feuille blanche.
L’approche de type top-down, orientée décomposition, est la plus courante, mais une approche alternative de type bottom-up, orientée agrégation, n’est pas exclue. Nous reviendrons sur ce sujet crucial du partitionnement d’une application et de la granularité des micro-services.
Prochains articles
Après les principes-avantages de l’Architecture Micro-Services, que nous venons de présenter dans ce premier article, nous nous intéresserons dans le deuxième article aux :
- Considérations techniques, inconvénients et impact sur l’organisation de l’Architecture Micro-Services,
Puis nous développerons le sujet de l’Architecture Micro-Services, souvent associé à d’autres sujets plus conceptuels, déjà abordés sur ce blog (liste non exhaustive) :
- Le partitionnement d’une application et la granularité des micro-services,
- L’Architecture Micro-Services dans les cadres d’Architecture d’Enterprise (Praxeme, TOGAF),
- Les méthodes de conception de l’Architecture Micro-Services,
- La modélisation de l’Architecture Micro-Services avec UML, ArchiMate ou autres,
- L’Architecture Micro-Services et les bases de données,
- L’Architecture Micro-Services et les processus métier,
- L’Architecture Micro-Services et les règles métier,
- La gestion des API et la gouvernance des micro-services.
N’hésitez pas à poster un commentaire en cliquant sur le lien ci-dessous.
Thierry BIARD
Architecte d’Entreprise, Spécialiste EDI, BPMN et DMN, je propose mes compétences aux leaders du Transport et de la Logistique, pour mettre en place des échanges B2B efficients. J’ai fait mienne cette citation de Nelson Mandela : « Je ne perds jamais. Soit je gagne, soit j’apprends ». En fait, j’apprends plus souvent que je gagne !
« La vie ce n’est pas d’attendre que l’orage passe, c’est d’apprendre à danser sous la pluie ».
Inconvénients de l'Architecture Micro-Services
Intéressons-nous à quelques considérations techniques importantes, puis aux inconvénients de l’Architecture Micro-Services et enfin à son impact sur l’organisation.

Dans notre premier article L’Architecture Micro-Services expliquée à ma fille, nous avons résumé l’évolution de l’architecture logicielle, présenté les principes de ce style d’architecture et posé les questions du partitionnement d’une application monolithique et de la granularité des micro-services.
Considérations techniques
L’architecture idéale est sans doute celle qui dépend le moins de toutes considérations techniques, mais au moment où il faut la réaliser, il est nécessaire de disposer des outils adéquats. La panoplie des outils dont on dispose pour mettre en place les micro-services, selon l’architecture préalablement établie, est très large.
Pour être précis, il vaudrait mieux parler de composants logiciels qui proposent des micro-services. Les composants favorisent la réutilisation du code déjà développé et limitent automatiquement la redondance (du code, mais aussi des données), que l’on trouve bien souvent dans une architecture en silos. Attention toutefois à ce que cette lutte contre la redondance n’augmente pas le couplage entre les micro-services.
Ces composants sont encapsulés et accessibles uniquement via leurs API (Application Programming Interface), soit selon le style RESTful (REpresentational State Transfer), qui s’appuie sur le protocole synchrone HTTP, soit via un système de messagerie au protocole asynchrone (de type message broker). Ce principe de composants encapsulés et échangeant entre eux via leurs interfaces n’est pas sans rappeler le paradigme de la Programmation Orientée Objet (OOP).
Tandis que les micro-services peuvent échanger entre eux directement via leurs API, les Clients externes peuvent éventuellement accéder à toutes les API de façon unifiée, grâce à une passerelle (API Gateway). Le couplage entre les micro-services peut être réduit en utilisant le mécanisme d’Inversion des Dépendances : les micro-services doivent dépendre de leurs abstractions (couches de haut niveau), mais pas de leurs implémentations (couches de bas niveau).
Autre considération, les micro-services sont exécutés par des serveurs qui n’ont pas besoin de connaitre leurs contextes d’utilisation (stateless servers), ce qui permet de les distribuer et de les dupliquer plus facilement.
La dernière considération technique importante est la conteneurisation (containerization), qui facile grandement le déploiement des micro-services, avec une règle simple à appliquer : un seul micro-service, ou plutôt un seul composant logiciel donc, par conteneur.
Ces considérations techniques seront approfondies dans nos prochains articles.
Inconvénients de l’Architecture Micro-Services
Tandis que les principes de l’Architecture Micro-Services sont généralement partagés par tous, car ils constituent autant d’avantages, les inconvénients sont plus rarement évoqués. Ces inconvénients sont bien souvent les conséquences de ces principes et constituent parfois des contradictions. Il est toutefois possible d’atténuer ces inconvénients : c’est en fait là que réside le talent de l’architecte.
1- Terme « micro » très relatif : la difficulté est de bien définir la granularité des micro-services. Cette granularité est variable d’un micro-service à l’autre. Ce n’est pas une bonne idée d’essayer d’obtenir une granularité uniforme pour tous les micro-services.
2- Problème de mise à jour des bases de données cloisonnées (chaque micro-service ayant sa propre base et pouvant être instancié plusieurs fois par le mécanisme de mise à l’échelle). Le mécanisme usuel de transaction de type « commit » n’est plus suffisant ; un mécanisme plus complexe appelé « saga » est nécessaire.
3- Défi en matière de débogage, test, déploiement des applications constituées de micro-services. Chaque micro-service aura été testé individuellement au préalable, mais ensuite, il faudra bien les tester tous ensemble, de façon automatisée de préférence.
4- Changements compliqués à cause des éventuelles dépendances entre les micro-services. Les micro-services supportent toutefois le versioning et plusieurs versions d’un même micro-service peuvent coexister, permettant une migration progressive vers la dernière version.
5- Application globale moins performante (latence), car dépendante du réseau (éventuellement moins fiable). Un protocole de communication asynchrone sera souvent préféré à un protocole synchrone, afin d’éviter d’attendre trop longtemps une réponse « immédiate » à chaque requête. De plus, l’usage d’un mécanisme de lecture via une mémoire cache est recommandé, afin d’optimiser la performance.
6- Besoin d’authentification, voire de chiffrage, pour diminuer les failles de sécurité du réseau.
(Liste non exhaustive, sans doute)
Impact sur l’organisation
Ce serait très réducteur de résumer l’Architecture Micro-Services à son aspect purement technique, car elle a également un impact fort sur l’organisation de la direction informatique de l’entreprise et l’exploitation d’une infrastructure distribuée et automatisée va induire de nouvelles pratiques, et même un changement de culture.
Ainsi, la frontière entre le build et le run (selon ITIL) disparaît. Cette approche est alignée avec la tendance DevOps (Development & Operations) avec Intégration et Livraison Continues (CI/CD). A noter que l’imbrication de la conception avec le déploiement en production des micro-services nécessite un champ très large de compétences.
Exemple concret de l’impact sur l’organisation : La taille de l’équipe responsable d’un micro-service est plus ou moins proportionnelle à la taille de ce micro-service. Chaque équipe, malgré sa taille réduite, doit pouvoir travailler de manière autonome. Amazon conseille de limiter la taille de l’équipe à une douzaine de personnes (two-pizza team !).
Les responsabilités nouvelles sont distribuées par micro-service, et sont étendues d’un bout à l’autre du cycle de vie du micro-service, c.-à-d. depuis la conception jusqu’à la production et même le support. Aussi faut-il raisonner en termes de Produit (alors qu’il s’agit d’un Service…), comme dans une méthode Agile, et non en termes de Projet, avec une fin planifiée.
Thierry BIARD
“In theory, there is no difference between theory and practice, while in practice, there is.”
Benjamin Brewster
Orchestration des micro-services avec BPMN
Pas de monolithe non plus dans la modélisation !

Image by Gerd Altmann from Pixabay
Il n’est pas question de vouloir reproduire en modélisation ce que l’on souhaite désormais éviter en architecture applicative : le monolithe. Pas de modélisation d’un unique processus généralement long. Préférez à la place la modélisation de plusieurs processus courts, avec une règle très simple à appliquer (quand la décomposition en micro-services a déjà était faite préalablement) :
-
-
- 1 micro-service <==> 1 pool BPMN
-
Vous choisirez alors un diagramme BPMN de collaboration qui représentera les échanges entre les pools (micro-services) par des flux de messages.
Orchestration versus chorégraphie
Des micro-services autonomes et suffisamment intelligents pourraient, en communiquant directement entre eux, composer une chorégraphie d’apparence séduisante (bien que sans vision globale du processus). Ce serait sans compter sur la prise en charge des blocages qui pourraient survenir et des reconfigurations de processus métier, qui compliqueraient inévitablement cette chorégraphie.
Pour éviter les complications de la chorégraphie, il convient de privilégier la mise en place d’une orchestration de micro-services. Un processus principal, celui qui gère les interactions avec le Client (front-office) et nommé l’Orchestrateur, va commander les processus secondaires (micro-services en back-office), via des flux de messages adéquats. On comprend tout de suite que la reconfiguration d’un processus métier sera plus simple : seul l’ordre d’appel aux micro-services par l’Orchestrateur sera alors modifié ; aucun impact sur les micro-services eux-mêmes.
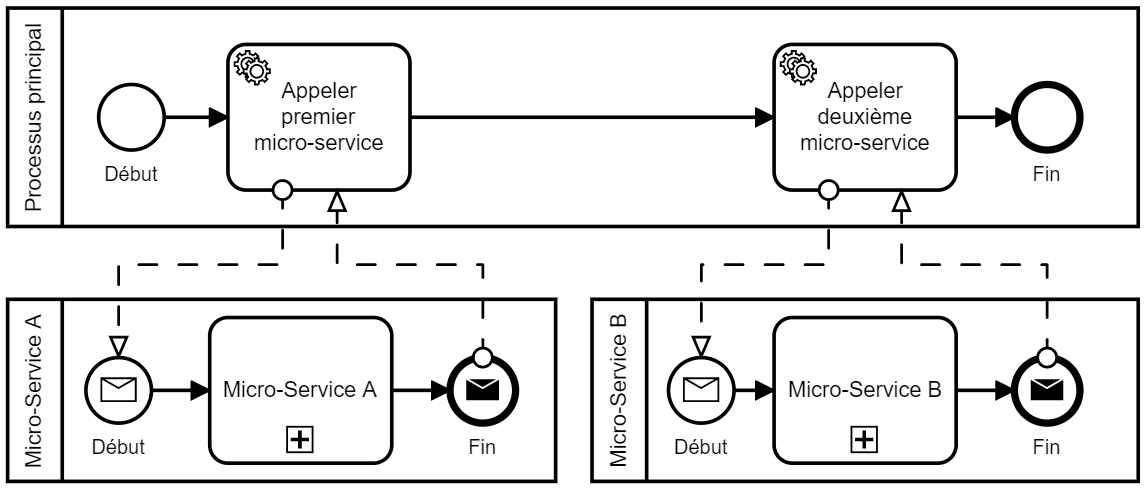
BPMN est souvent utilisé pour modéliser des processus métier relativement longs, mais les durées d’exécutions des tâches automatisées confiées à des micro-services peuvent être extrêmement courtes (mesurées en millisecondes). Cela ne pose pas de problème particulier : seule l’échelle du temps (non formalisée en BPMN) sera différente, plusieurs jours, mois, voire années, à l’échelle du processus métier en entier, contre quelques millisecondes à l’échelle de certaines tâches, celles exécutées par les micro-services.
Communications synchrones versus asynchrones
Les messages figurant sur un diagramme de collaboration peuvent représenter aussi bien des communications synchrones (protocole REST notamment) que des communications asynchrones (MQ par exemple). Ils semblent, par contre, peu adaptés pour représenter le data streaming (Kafka notamment). Mais l’éditeur Confluent notamment propose, sur sa plate-forme, l’API REST Proxy pour accéder au data streaming de Kafka.
Ce n’est pas l’objet principal de cet article, mais rappelons que les communications asynchrones entre les micro-services sont conseillées, afin de limiter le couplage et favoriser la mise à l’échelle d’une architecture micro-services.
La principale caractéristique du protocole de communication synchrone est d’attendre systématiquement un accusé de réception (bonne ou mauvaise). Mais il faut attendre cet accusé avant de continuer : cette attente peut durer longtemps dans certains cas (lors d’un pic de charge notamment) et bloquer la communication ; elle constitue l’exemple parfait d’un couplage fort. Le diagramme de collaboration simple ci-dessus représente des communications synchrones avec les micro-services.
Il existe toutefois des solutions, comme les modèles Circuit Breaker (disjoncteur) et Bulkheads (cloisons), pour limiter l’impact de ce couplage fort (pour aller plus loin, lire cet article de Rhona : https://www.urbanisation-si.com/solutions-sur-etagere-pour-la-gestion-des-defaillances-des-micro-services).
Par contre, avec un protocole de communication asynchrone, cet accusé de réception sera envoyé plus tard (lors d’une prochaine session de communication). L’attente de cet accusé ne sera donc pas bloquante. On imagine ici la difficulté de représentation dans un diagramme BPMN… Cet accusé est toutefois optionnel : on peut considérer par exemple qu’il n’y aura jamais de problème à déposer un objet métier dans une file d’attente, qui absorbera sans difficulté un pic de charge, et se dispenser alors de demander un accusé de réception, toujours bonne. Dans ce cas, le couplage n’en sera qu’encore plus faible. Mais l’accusé de réception n’est pas le résultat de l’appel au micro-service, qu’il faudra bien attendre.
BPMN pas seulement pour la modélisation !
Chaque micro-service n’est pas seulement représenté par un pool dans un diagramme de collaboration. Outre le fait que chaque micro-service doit disposer de son propre magasin de données (Data Store), conformément à l’un des principes fondateurs de l’Architecture Micro-Services, on peut encore améliorer son autonomie en lui donnant son propre moteur d’exécution (un moteur différent par micro-service, donc). C’est désormais possible avec des moteurs poids légers, comme le Camunda Workflow Engine.
Thierry Biard
Conseils pour réussir vos micro-services et éviter qu’ils ne se transforment en véritable pensum
N’abusez pas des Micros-Services et n’oubliez pas : sans DevOps et sans le Cloud, mieux vaut encore un bon vieux monolithe Java dans un serveur d’applications JEE ou COBOL dans un antédiluvien mainframe IBM. Les micro-services font le buzz, alors faut-il suivre cette tendance aveuglément ? N’y a-t-il pas des cas où ça équivaudrait à se tirer une balle dans le pied ?
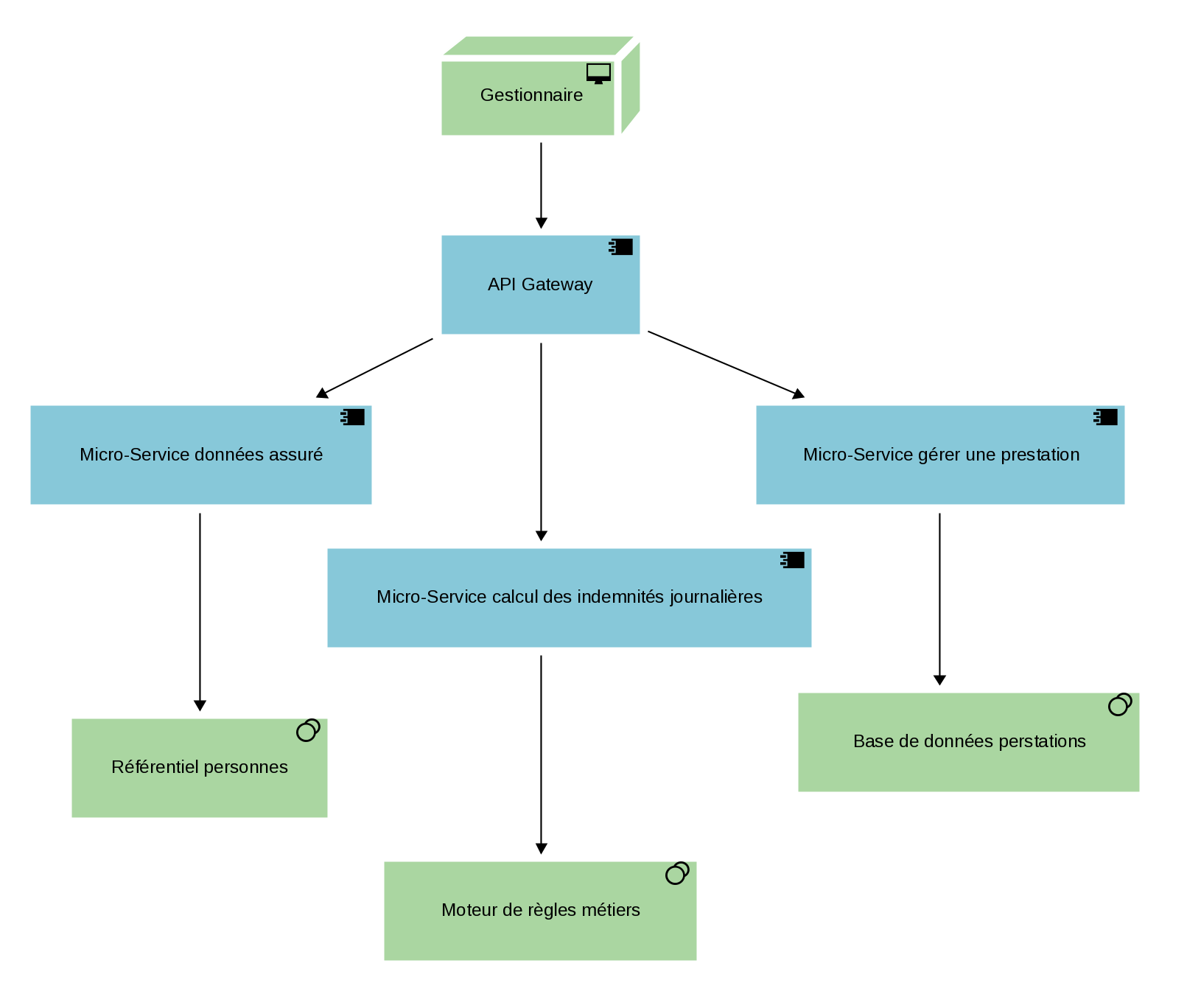
(Macro-modèle de la communication entre micro-services)
L’utilité des micro-services a été prouvée par un grand nombre d’entreprises de taille colossale (Netflix, Google…) qui les ont mis en œuvre pour résoudre une catégorie de problèmes liés à des cas d’utilisation bien particuliers.
Les limites des monolithes, comme celles des antédiluviennes applications COBOL sur mainframe, voire plus récemment Java dans les serveurs d’applications JEE, ont été atteintes en ce qui concerne, par exemple, leur gérabilité, leur évolution dans le Cloud, leur mise à l’échelle et la difficulté rencontrée à intégrer les méthodes agiles.

(Exemples de monolithes : les mainframe IBM et les serveurs d’application Java)
Certains d’entre vous reconnaîtront peut-être ce contexte d'architecture technique ci-dessus, montrant comment, au fil des années, les architectes techniques ont savamment fait un lifting du monolithe à coup de crème d’interfaces et de gateways. Cette couche cosmétique offre la possibilité à des applications de front office (client lourd ou client léger de type web) d’accéder aux dizaines de milliers de lignes de code COBOL enfouies dans les oubliettes du mainframe.
Les connaisseurs apprécieront le logiciel IBM ECI (External Call Interface) permettant à une application cliente d'appeler un programme CICS de manière synchrone ou asynchrone et le Saint Graal IBM CICS Transaction Gateway (CTG) qui est un connecteur conçu pour la modernisation des monolithes d’entreprise. Tous types d’applications Java JEE (renommer Jakarta depuis son transfert d’Oracle vers la fondation Eclipse), Microsoft .NET… peuvent communiquer avec CICS et des Web Services en COBOL.
Le tsunami de micro-services pourrait entraîner certains décideurs à les utiliser dans la conception et la réalisation de produits dans des contextes où ils ne sont pas censés être utilisés, entraînant dans certains cas des échecs.
Les microservices sans XOps (DevOps, DevSecOps, MLOps) ? Même pas en rêve !
Les microservices provoquent une explosion d'éléments (entités métiers, DAO/persistance, contrôleurs, sérialisation, annuaire/repository, gateway, load balancing, sécurité, logs, cloud...) à assembler. Ce n'est pas une bonne idée d'essayer de mettre en œuvre des microservices sans déploiement sérieux ni automatisation de la production du produit logiciel et de sa gouvernance.
Vous devriez être en mesure d'appuyer sur le bouton de votre CI/CD (Intégration et Livraison Continues) et de déployer votre application. En fait, vous devriez même ne rien faire. Le code de validation doit faire déployer votre application via la gestion évènementielle de validation, qui déclenche le pipeline de livraison, au moins en développement.
Ne gérez pas votre propre infrastructure
Les microservices intègrent souvent plusieurs bases de données, brokers de messages, gestionnaires de caches de données et autres services qui doivent tous être maintenus en état opérationnel.
Pour cela, on a toute la panoplie du Cloud.
- Infrastructure as a Service (IaaS) dans lequel le fournisseur Cloud gère le matériel serveur, les couches de virtualisation, le stockage, les réseaux.
- Platform as a Service (PaaS) où le fournisseur maintient la plate-forme d'exécution de ces applications : les serveurs, les systèmes d'exploitation, les systèmes de bases de données et les infrastructures de réseau ainsi que de sauvegarde.
- Software as a Service (SaaS) est un modèle d'exploitation commerciale des logiciels dans lequel ceux-ci sont installés sur des serveurs distants plutôt que sur la machine de l'utilisateur.
- Function as a Service (FaaS) est une catégorie de services de Cloud qui fournit une plate-forme permettant aux clients de développer, d'exécuter et de gérer des fonctionnalités d'une application sans la complexité de la création et de la maintenance de l'infrastructure généralement associée au développement et au lancement d'une application.
Construire une application suivant ce modèle est un moyen de parvenir à une architecture « sans serveur » et est généralement utilisé lors de la création d'applications de micro-services.
Ne créez pas trop de microservices
Chaque nouveau micro-service utilise des ressources. L'utilisation cumulative des ressources peut dépasser les avantages de l'architecture, si vous dépassez le nombre de micro-services que DevOps, l'organisation, le processus et le système peuvent gérer. Les rendre trop petits transfère la complexité des microservices vers une tâche d'intégration de services.
N'oubliez pas de garder un œil sur le problème de latence potentiel
Rendre les services trop granulaires ou exiger trop de dépendances sur d'autres microservices peut introduire de la latence. Des précautions doivent être prises lors de l'introduction de microservices supplémentaires. Lors de la décomposition d'un système en micro-services autonomes plus petits, vous
augmentez le nombre d'appels passés au-delà des limites supportables par le réseau et par les CPUs, ce qui va dégrader les temps de réponse et le système de multithreading.
Ces appels peuvent être soit de service à service, soit de service à composant de persistance. Par conséquent, exécuter des tests de performance pour identifier les sources de toute latence dans l'un de ces appels est fondamental. De nombreux outils sont disponibles dans l’offre commerciale : on peut citer IBM Rational Performance Tester, Oracle Load Testing et dans l’open source très utilisé Apache JMeter. Vous devez identifier les goulots d'étranglement.
Conclusion
Ces anti-cas d’utilisation permettent d'éviter le battage médiatique des micro-services qui entraînerait des échecs sans certaines précautions.
Ne donnons pas l’occasion aux détracteurs d'alimenter une polémique qui n’a pas raison d’être sur une technologie saine, aidant à l’agilité, réduisant le time to market et servant la stratégie de l’entreprise.
Pour finir, un dernier conseil : si la valeur de partage est une valeur universellement reconnue, ne l'appliquez pas aux micro-services qui ne doivent en aucun cas être liés à plusieurs systèmes différents.
Rhona Maxwel
@rhona_helena
"La courbe de tes yeux fait le tour de mon cœur,
Un rond de danse et de douceur,
Auréole du temps, berceau nocturne et sûr,
…
Le monde entier dépend de tes yeux purs
Et tout mon sang coule dans leurs regards."
Paul Eluard
Pour en savoir plus sur les micro-services :
- L’Architecture Micro-Services expliquée à ma fille
- Inconvénients de l'Architecture Micro-Services
- Estimation de la complexité d’une Architecture Micro-Services
Estimation de la complexité d’une Architecture Micro-Services
pour la comparer avec la complexité d’une architecture monolithique.


Dans notre premier article sur l’Architecture Micro-Services, nous avons indiqué parmi les principes que :
- une application composée de micro-services serait plus simple et donc moins complexe qu’une application monolithique équivalente (c.-à-d. ayant les mêmes fonctionnalités).
Il s’agit là d’une sorte d’intuition, présentée comme un postulat. Pourrions-nous le démontrer ?
Postulats et formule magique
La programmation modulaire est apparue peu après les prémices de l’informatique, dès les années 1970, et quelques connaisseurs se sont intéressés à l’impact de la modularité sur la complexité d’un système. Cette complexité est liée au nombre de fonctions dans un système. Une constatation généralement faite par tous permet de formuler un second postulat :
- la complexité d’un système croît exponentiellement avec le nombre de ses fonctions.
Comment quantifier cette croissance exponentielle ? Selon l’étude de Scott N. Woodfield en 1979 :
- accroitre de 25 % le nombre de fonctions d’une solution logicielle double sa complexité.
Cette constatation est connue comme la loi de Robert L. Glass, qui porte le nom de celui qui l’a exprimée en 2003. Puis Roger Sessions l’a formulée ainsi en 2011, après une simplification mathématique justifiée : Complexité(NombreFonctions) = NombreFonctions3,11.
Dans le cadre d’une Architecture Orientée Services (SOA), il convient d’appliquer cette formule pour estimer la complexité de chaque partition, une partition étant un module contenant une ou plusieurs fonctions. Roger Sessions a constaté que la complexité dépendait également du nombre de dépendances entre les partitions-modules. La complexité totale est donc formulée ainsi :
ComplexitéTotale(NombreFonctions,NombreDépendances) =
NombreFonctions3,11 + NombreDépendances3,11
N.B. Afin de ne pas compter les dépendances deux fois, on les comptera au niveau de chaque module qui dépend d’autres modules (les pointes de flèches sur un diagramme de dépendances).
Vous noterez qu’une dépendance a la même pondération d’une fonction. L’unité de mesure est la SCU (Standard Complexity Unit). Il ne s’agit pas vraiment d’une mesure absolue, mais d’une mesure relative, qui va permettre de comparer la complexité des différentes solutions d’architecture d’un système.
Vers la simplexité ?
Appliquons cette formule d’estimation de la complexité à un exemple relativement simple. Soit une application de vente de livres en ligne, avec 5 fonctions principales :
- Gestion des utilisateurs (les clients, mais aussi les libraires),
- Catalogue des livres,
- Avis des lecteurs,
- Gestion des achats (paniers, commandes),
- Vitrine (interface utilisateur).
Les dépendances entre ces 5 fonctions principales peuvent être représentées comme cela :
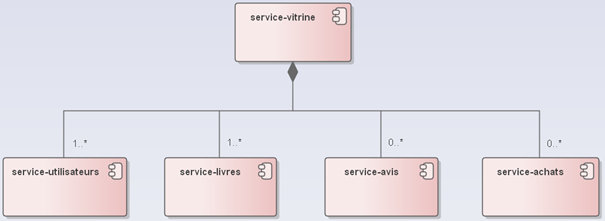
Comparons la complexité d’une application monolithique, qui contient ces 5 fonctions, avec une application où chaque fonction a été partitionnée en un micro-service :
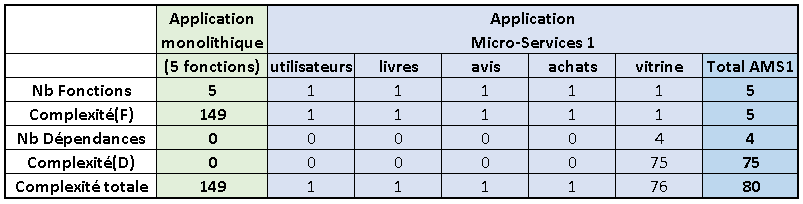
On constate que l’estimation de la complexité de l’application micro-services avec ce partitionnement maximum est presque deux fois moins élevée que celle de l’application monolithique.
Considérons maintenant qu’il serait logique de regrouper l’avis des lecteurs avec le catalogue des livres, soit deux fonctions dans le même module-micro-service :
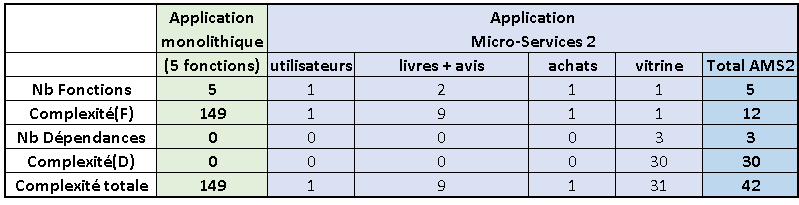
Ce regroupement divise encore par deux l’estimation de la complexité ! En effet, on obtient un module-micro-service un peu plus complexe, car contenant deux fonctions au lieu d’une seule, mais on supprime une dépendance, ce qui a un impact plus fort.
Compromis, chose due
Bien sûr, nous pourrions débattre sur le postulat de départ et notamment sur la valeur 3,11 de la puissance, qui traduit l’augmentation exponentielle de la complexité selon le nombre de fonctions. Mais une chose est sûre :
- la complexité du système conçu ne sera maitrisée que si l’architecte trouve un compromis entre son partitionnement en modules et la dépendance entre ces modules.
Thierry BIARD
« En mettant au premier plan l'expérience vécue et le corps en action, la simplexité est également utile pour penser un environnement mieux adapté à l'homme. »
Petit traité de cyber-psychologie de Serge Tisseron