
Ingénierie Dirigée par les Modèles (IDM)
Vous cherchez un outil pour gérer le mapping entre les objets métier et une base de données relationnelle, générer les scripts SQL et produire du code à partir de vos modèles ? Obeo ISD S.1 Ep.5
L’atelier Entity d’Obeo Information System Designer (ISD) va vous permettre de modéliser vos entités métier. Avec l’autre atelier Database, vous pourrez modéliser votre base de données relationnelle, générer des scripts SQL, rétromodéliser des bases existantes, gérer des Modèles Logiques de Données (MLD) et des Modèles Physiques de Données (MPD).
Et grâce aux deux, vous serez assuré de la synchronisation efficiente entre vos objets métier et votre base SQL. ISD a plus d’un tour dans son sac avec ses nombreux frameworks qui vous permettront de générer une partie du code de votre application, à partir de vos modèles de conception et d'analyse.
Vous créez votre modèle d'entités persistantes, puis, à partir de ce modèle, ISD va générer le MLD ;
vous lui indiquez votre moteur SQL, ISD génère le MPD, puis les scripts correspondants
et enfin vous les exécutez directement dans ISD.
Résumé des épisodes précédents
Nos 4 précédents articles détaillent toutes les étapes, depuis l'analyse du besoin
jusqu'à la conception d'une architecture micro-services.
Les différents modeleurs et leurs fonctions
- Épisode 1 : présentation des fonctionnalités et installation d’ISD.
A lire > Alimenter le référentiel d’Architecture d’Entreprise pour la couche Application de TOGAF avec l’outil Information System Designer (ISD) d’Obeo - Modélisation de l’analyse des besoins S.1 Ep.1
- Épisode 2 : l’atelier Graal de modélisation des acteurs, des use cases, des tâches, des enchaînements d’actions, des diagrammes de séquence et de machine à états.
A lire > Méthode Graal, le NoUML d’Obeo, parfaite fusion entre un UML phagocyté et un BPMN édulcoré. S.1 Ep.2
- Épisode 3 : l'atelier Graal de gestion des User Stories, l’atelier Requirement pour gérer le référentiel des exigences et leur traçabilité, l’atelier Cinematic pour la modélisation des maquettes et la cinématique des écrans
A lire > Comment assurer la traçabilité des exigences avec les user stories, les use cases, les processus métier, la cinématique et les maquettes d'écrans ? Une solution dans notre test Obeo ISD S.1 Ep.3
- Épisode 4 : l’atelier SOA pour modéliser des API (REST ou SOAP) avec leurs composants applicatifs micro-services ou Web Services, leurs interfaces de communications, leurs relations, leurs opérations avec les données échangées (DTO), pour générer des documents OpenAPI et pour rétromodéliser des interfaces REST.
A lire > Quelle solution pour concevoir la modélisation d’une architecture micro-services, l’intégrer dans une architecture d’entreprise et permettre une collaboration avec l’ensemble des acteurs projet ? Obeo ISD S.1 Ep.4
Créez des entités persistantes
Jouez la partition
En préambule, quelques mises au point sur la terminologie d’ISD :
- les Domain classes représentent les entités métier définies par les experts métier et modélisées par les business analysts avec la méthode Graal,
- les Entities correspondent aux classes persistantes gérées par un ORM (Object Relational Mapping) offrant la dualité objet/relationnel SQL.
- les DTO, créés à partir des attributs des Entities, représentent les données échangées entre les services dans une SOA.
Un diagramme Entities Namespaces Hierarchy est créé dans le conteneur de l'Entity Model.
Le NoUML de modélisation d’Obeo ISD est en fait un DSL (Domain-Specific Language), dans lequel le package UML est renommé namespace, avec un nombre restreint de relations.
De manière similaire à la vue Domain Classes Namespaces Hierarchy du modèle Graal ou celle DTO Namespaces Hierarchy, il faut créer au préalable au moins un namespace :
- File ou clic droit sur votre Modeling Project > New > Other > IS Designer > Entity Model
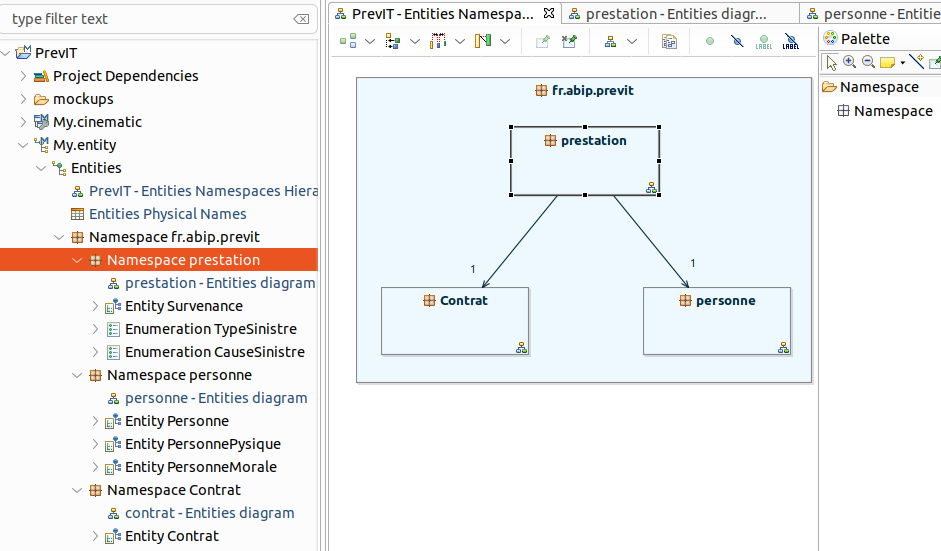
Les pictos en bas à droite des namespaces indiquent qu’en double-cliquant,
on peut accéder au diagramme d’entités.
Ce diagramme permet de modéliser les classes, qu'elles soient internes ou externes au namespace. S’il existe des relations entre des classes appartenant à des namespaces différents, alors ISD génère automatiquement les relations dans le diagramme des namespaces.
- Une fois le namespace créé, le sélectionner via le menu contextuel > New Representation > Entities Diagram
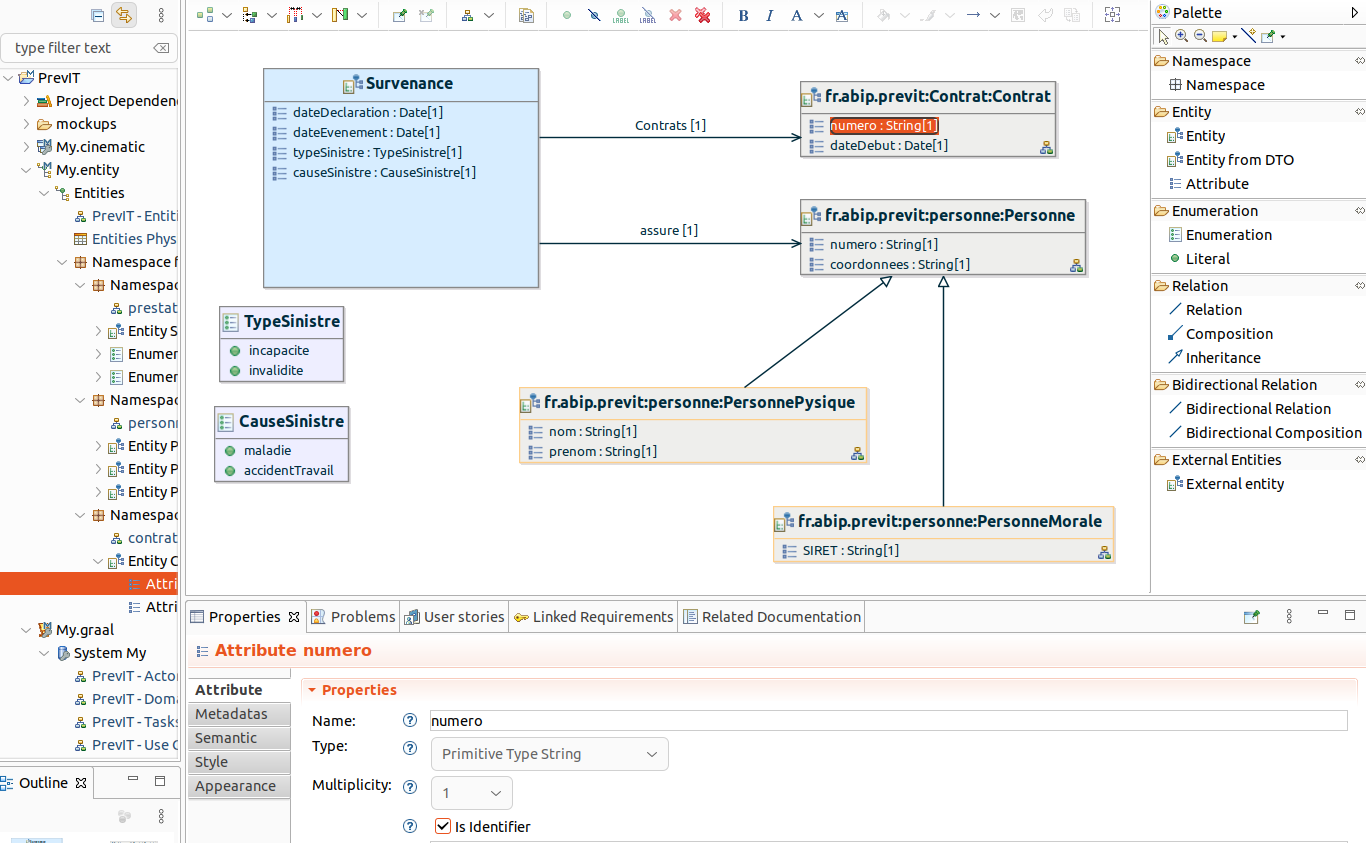
On retrouve exactement le même type de diagramme que les Domain Classes ou les DTO,
sauf que cette fois-ci les classes sont stéréotypées Entity.
ISD supporte les visions entités persistantes vers DTO ou bien l’inverse. Dans le diagramme d’entités, on a Entity from DTO et dans celui des DTO on a DTO from Entity.
Ce choix est judicieux, car il permet une souplesse de conception bidirectionnelle qui se présente souvent dans un contexte agile, où l’on doit ajouter des données, soit dans les entités persistantes et les répercuter dans les DTO, soit l’inverse.
Un bémol à la clé
Par contre, il est impossible de récupérer les classes métier (Domain Classes) modélisées dans le modèle Graal de l’analyse. Dommage, car en pratique la plupart des entités persistantes proviennent des classes participantes ou métier !
Il nous a été impossible de créer une relation entre une entité et une énumération, on a donc créé à la place un attribut du type énumération.
En choisissant de générer toutes les entités à partir de nos DTO, nous avons constaté que :
Les liens d’héritage ne sont pas repris, bien que l’on ait sélectionné toutes les relations à importer, mais les attributs sont dupliqués dans l’entité héritière.
Les énumérations n'apparaissent pas, bien qu’un attribut d’une entité soit de type énumération.
Ajoutez à vos entités persistantes
les informations spécifiques à la base SQL
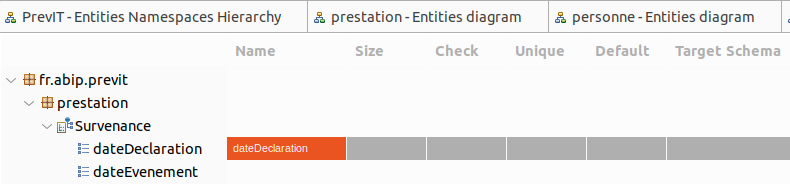
Préparez la correspondance de vos entités persistantes
avec les noms des colonnes, type, taille, unicité, index...
La vue Entities Physical Names est un tableau qui reprend en lignes toutes les entités définies précédemment et permet dans les colonnes d’ajouter les informations spécifiques à la base de données, comme le nom physique d'une colonne, la taille, les contraintes de vérification, les contraintes d’unicité, la valeur par défaut, le choix des schémas pour les tables intermédiaires.
Par exemple, sur un attribut indexé, on peut mettre dans la colonne Unique ASC pour ascendant ou DESC pour descendant.
Pour une contrainte d’unicité portant sur plusieurs champs, on doit adopter un langage spécial (sur l’entité et non plus sur l’attribut, dans la colonne Unique, on doit saisir champ1:ASC,champ2,champ3,etc. avec éventuellement un | pour séparer des index différents).
Il est impossible de saisir dans les colonnes Name, etc. les attributs des entités créées à partir des DTO. Par contre, si nous ajoutons une nouvelle entité avec des attributs, elle se retrouve bien dans le tableau et nous pouvons bien saisir dans les colonnes des attributs.
Générez automatiquement le modèle logique
de données (MLD) à partir du modèle Entités
Construisez l'échafaudage de votre architecture :
le système de génération Scaffolding d'ISD
- Menu File ou clic droit sur votre Modeling Project > New > Other > IS Designer > Database Model > Laissez toutes les valeurs par défaut (Data Base, Logical Types et UTF-8)
Un diagramme de schéma logique de base de données, encore appelé MLD (Modèle Logique de Données) pour les nostalgiques de la méthode Merise, est créé, dans lequel on peut modéliser des tables, vues, colonnes, clés primaires et étrangères, des séquences, des index…
Le système Scaffolding d’ISD permet de transformer des modèles, suivant les concepts MDA (Model Driven Architecture) de l’OMG.
A lire > nos articles dans la catégorie : Ingénierie Dirigée par les Modèles (IDM)
Après avoir modélisé vos entités persistantes et défini les propriétés physiques (nom de table, taille…) avec l’atelier Entities, vous pouvez générer vos tables dans le diagramme de schéma pour une base de données relationnelle (MLD), pour l’instant vide, grâce au système Scaffolding Entity to Logical database d’ISD.
- Sélectionnez à la fois, en maintenant la touche Ctrl enfoncée, le conteneur (Entities) sous la vue (.entity) et le conteneur Data Base sous la vue (.database) > clic droit > IS Designer > Scaffolding > Entity to Logical database (remarque : on dispose aussi de l’option inverse) > les schémas générés à partir des namespaces du modèle Entities apparaissent :
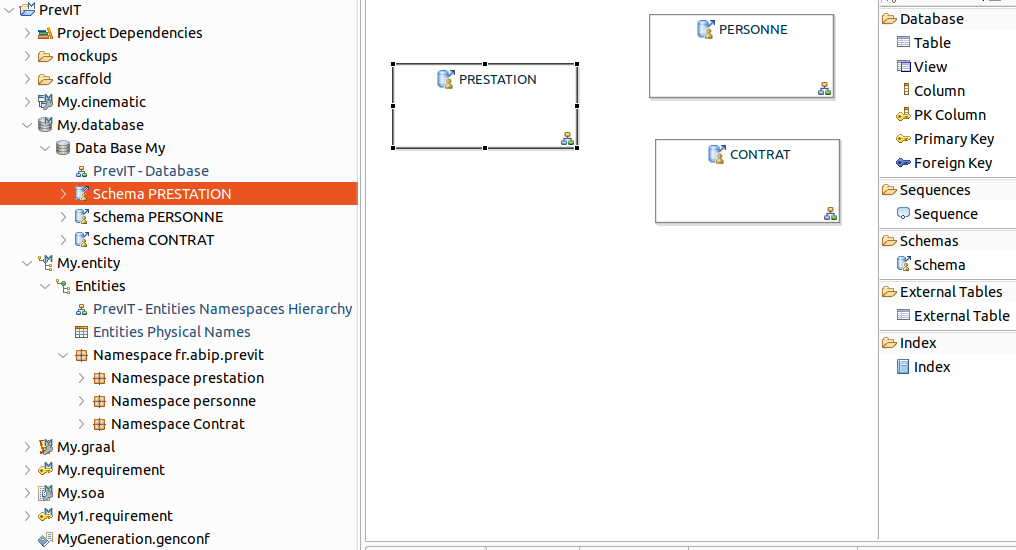
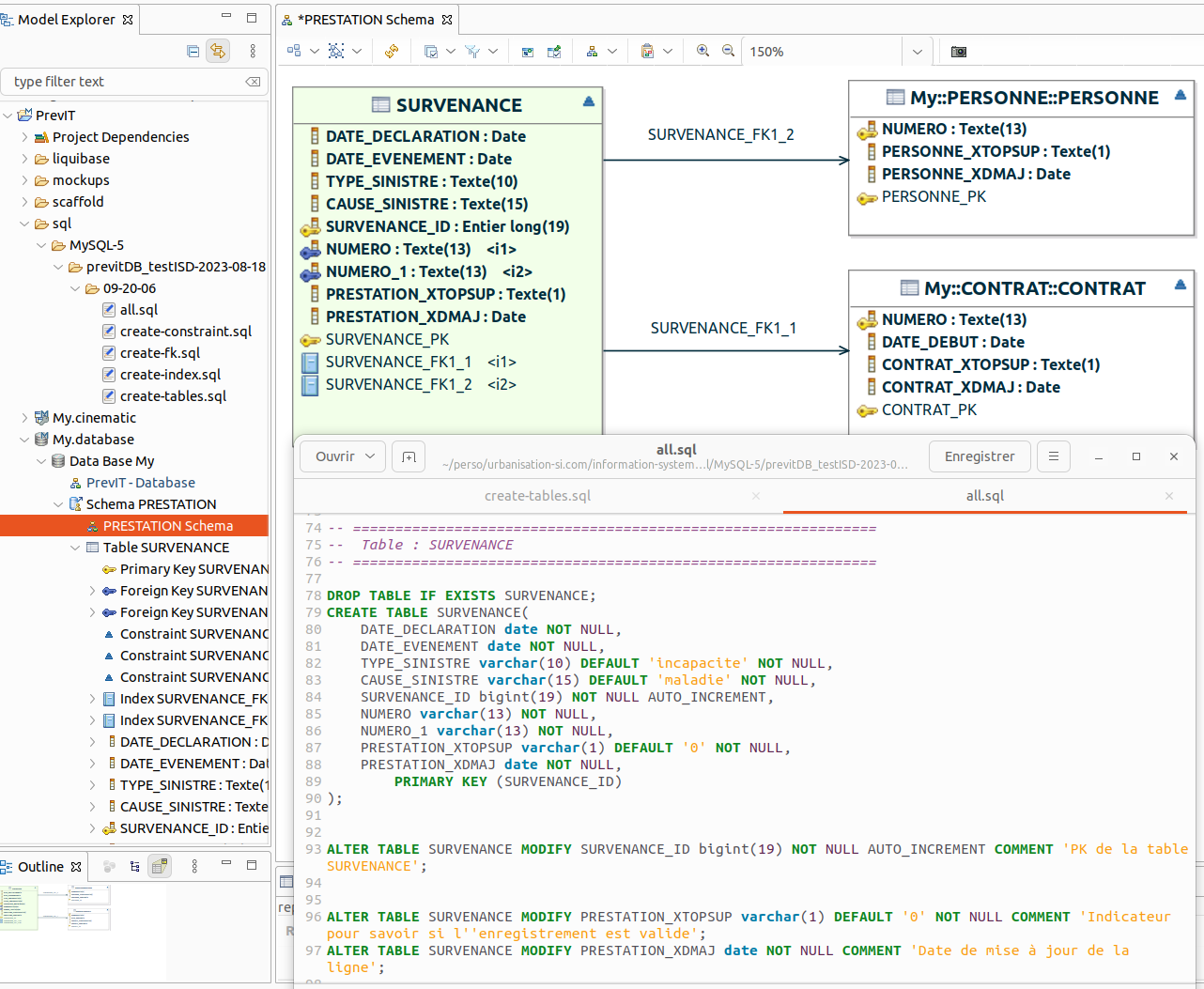
Dans le schéma logique de base PrevIT, 3 sous-namespaces sont créés correspondant
aux 3 contextes métier (Domain Driven Design) Prestation, Personne et Contrat.
Pour avoir le détail, double-cliquez sur un schéma :
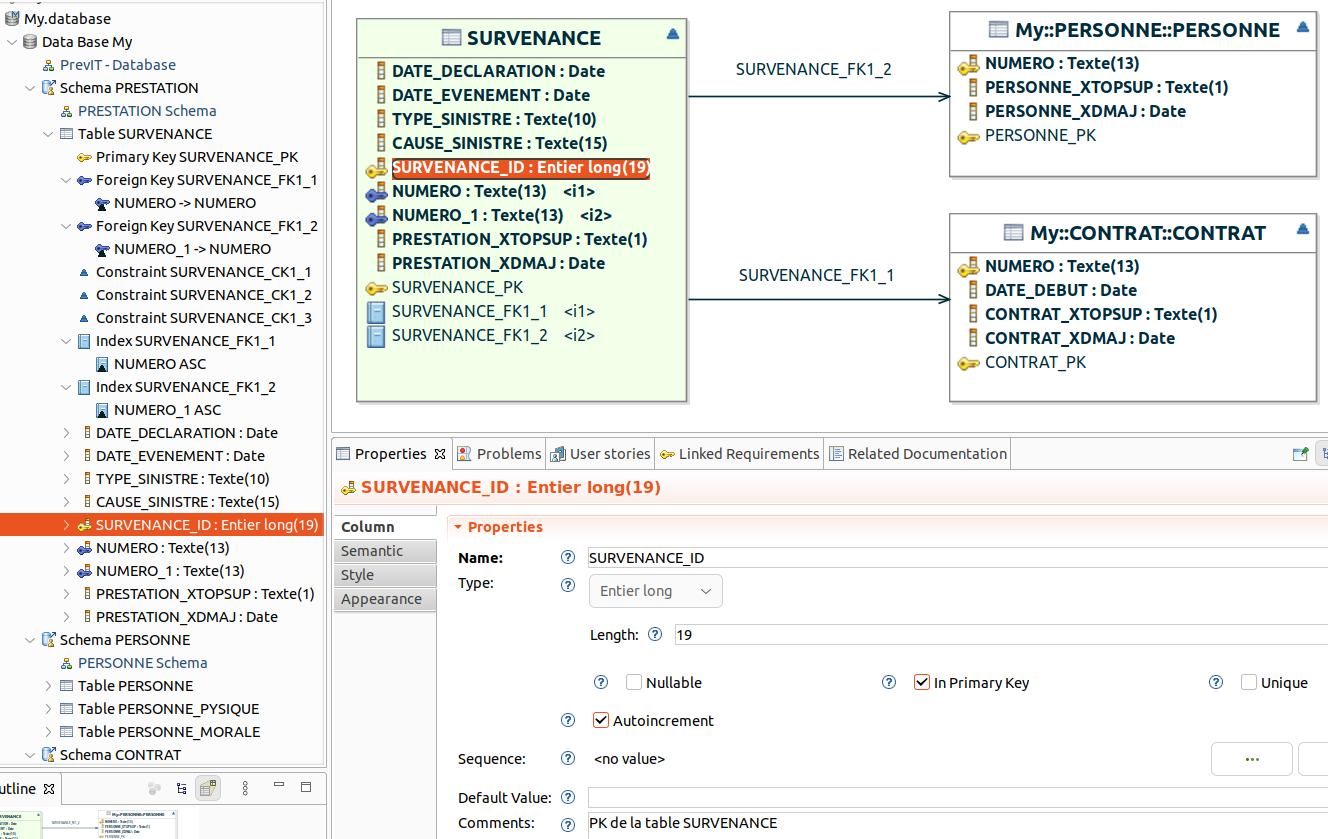
On retrouve les concepts des bases de données relationnelles, avec les clés primaires, étrangères,
les contraintes de check (triangle sur les tables), etc. Vous pouvez réorganiser les colonnes.
Le MLD est bien créé à partir du modèle entities. Des colonnes de pistes d'audit ont été ajoutées par le générateur d'ISD comme PRESTATION_XTOPSUP (Indicateur pour savoir si l'enregistrement est valide) et PRESTATION_XDMAJ (Date de mise à jour de la ligne). La table SURVENANCE est en relation avec la table PERSONNE dans le schéma PERSONNE et avec la table CONTRAT dans le schéma CONTRAT.
Pour la génération de l'héritage, l'échafaudage est bancal
Les bases de données relationnelles n'ont pas de moyen simple de mapper les hiérarchies de classes sur les tables de base de données. Pour résoudre ce problème, plusieurs stratégies existent :
- MappedSuperclass - les classes parentes ne peuvent pas être des entités,
- Table unique – Les entités de différentes classes ayant un ancêtre commun sont placées dans une seule table,
- Table jointe - Chaque classe a sa table, et interroger une entité de sous-classe nécessite de joindre les tables,
- Table par classe - Toutes les propriétés d'une classe sont dans sa table, donc aucune jointure n'est requise.
La stratégie d’héritage choisie est celle d’une table par classe. Cette stratégie mappe donc chaque entité à sa table, qui contient toutes les propriétés de l'entité, y compris celles héritées.
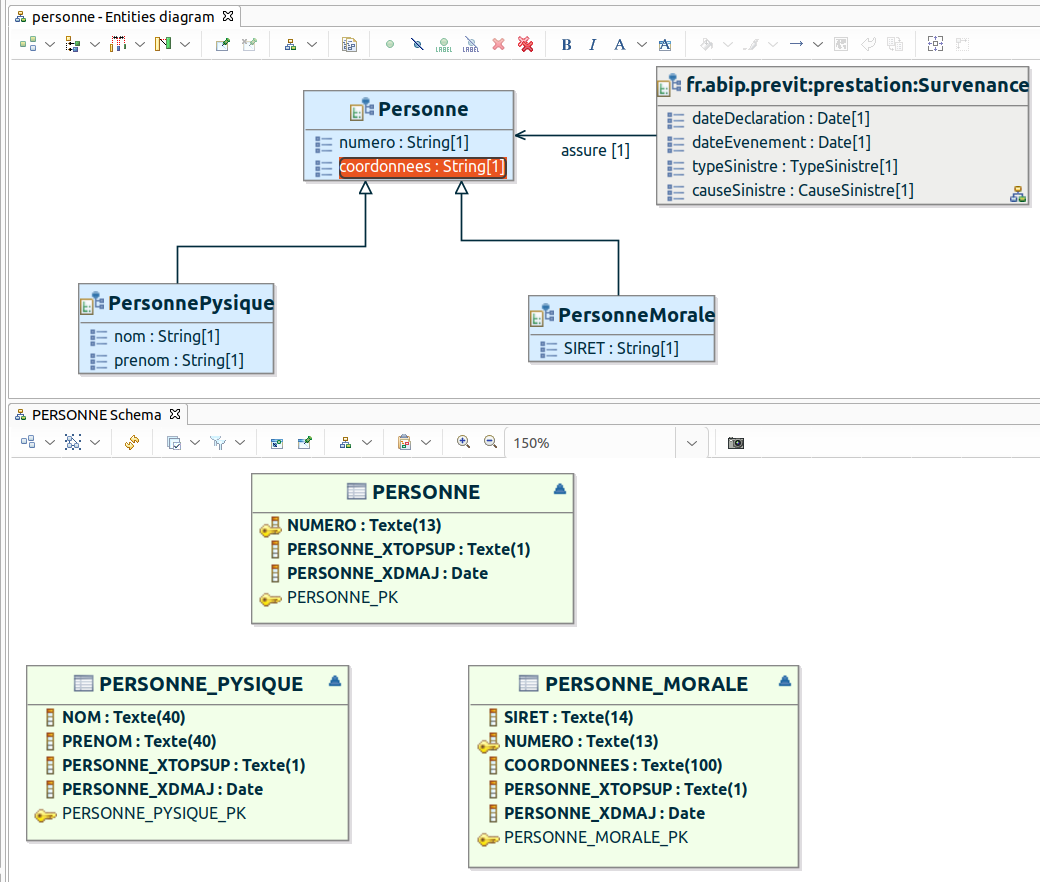
3 tables ont bien été générées. Seule la table PERSONNE_MORALE est correcte compte tenu des relations d'héritage modélisées dans le diagramme Entities. En effet, les colonnes NUMERO et COORDONNES héritées sont bien présentes, en plus du SIRET spécifique à la table.
Dans le modèle des entités persistantes (partie supérieure de l'illustration), PersonnePhysique et PersonneMorale héritent des attributs numero et coodonnees de Personne. Dans le schéma généré (partie inférieure de l'illustration), on constate que coordonnees n’apparaît pas dans la table PERSONNE, ni dans la table PERSONNE_PHYSIQUE, alors que bizarrement elle est bien présente dans la table PERSONNE_MORALE. Auparavant, nous avons bien pris soin de spécifier la colonne coordonnees dans le tableau Entities Physical Names du modèle Entities, avec une taille de 100.
Autre bizarrerie, la colonne NUMERO de la table PERSONNE et PERSONNE_MORALE apparait bien, conformément à la stratégie d’implémentation de l’héritage, mais pas dans la table PERSONNE_PHYSIQUE !
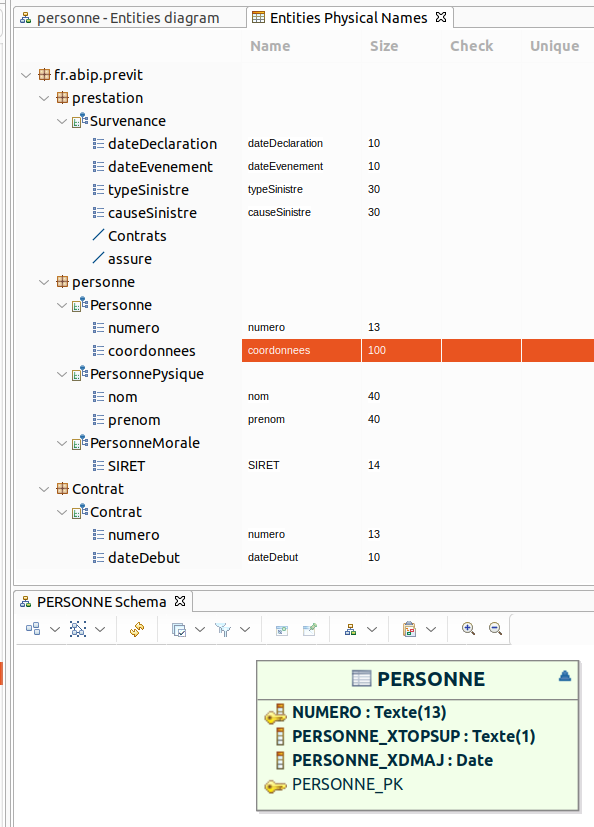
Dans le tableau Entities Physical Names du modèle Entities, permettant de configurer le MLD qui va être généré, à l'attribut coordonnees de la classe Personne, on a fait correspondre la colonne du même nom avec une taille 100, qui pourtant n'apparaît pas dans la table PERSONNE.
Gestion des modifications
Si l’on fait d’autres modifications, et que l’on refait l’opération de scaffolding, ISD propose de créer une nouvelle version ou d’écraser l’ancienne.
- Par exemple, on modifie le nom du schéma, il suffit de sélectionner le conteneur .scaffold sous le répertoire scaffold > IS Designer > Scaffold > Entity to Logical database. Un nouveau schéma EB apparaît, on crée un nouveau diagramme (New representation > nouveau nom Schema) et l’on retrouve un nouveau MLD avec en préfixe le nom du nouveau schéma.
Générez automatiquement
le Modèle Physique de Données (MPD)
Prenons MySQL comme RDBMS de test.
Créez tout d’abord un schéma (database) vide dans MySQL, par exemple previtDB_testISD, puis dans ISD, menu File > Import > Database > Import Database > saisissez les informations de connexion à votre database MySQL :
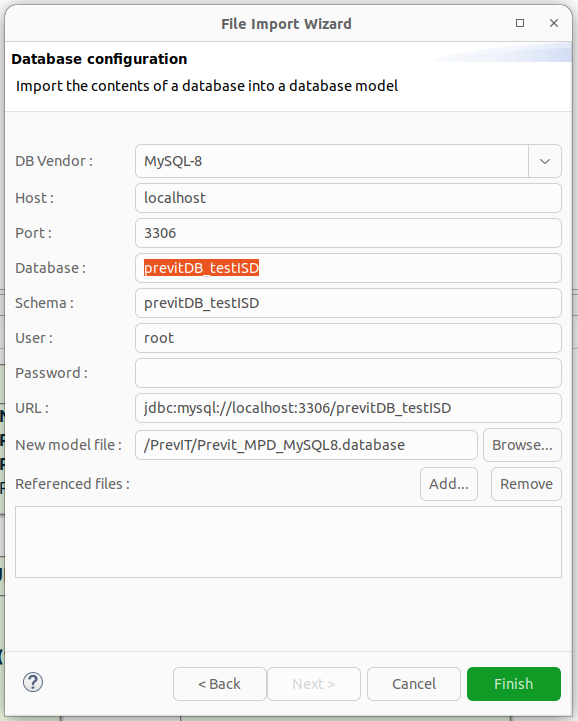
Remarque importante : dans le champ New model file, vous devez saisir
un modèle de database inexistant, par exemple Previt_MPD_MySQL8.database
Générez le MPD avec le système de scaffolding d’ISD, en procédant de la même manière que pour générer le MLD à partir des entités :
- Sélectionnez simultanément votre MLD (Data Base My) et votre MPD vide, que vous venez de créer (Data Base previtDB_testISD)
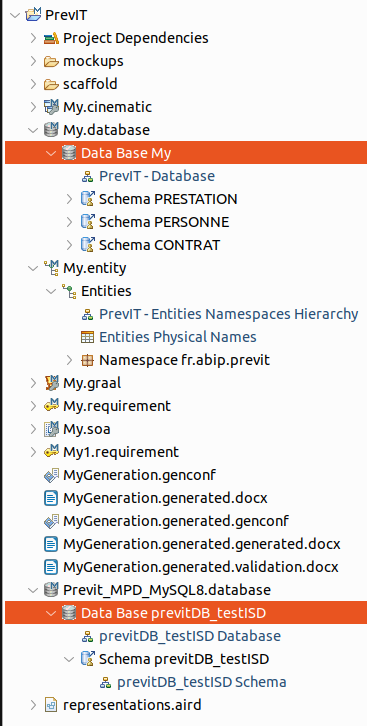
A partir de votre MLD généré précédemment, le système Scaffolding d'ISD va générer
votre MPD nouvellement créé et qui pointe sur votre database vide MySQL.
- Menu contextuel sur le MPD > IS Designer > Scaffolding > Logical database to Physical database (on dispose aussi du reverse engineering Physical database to Logical database).
Le MPD est créé avec les 4 schémas MySQL correspondants aux 4 namespaces : le namespace previtDB_testISD correspondant au namespace de base et PRESTATION, PERSONNE et CONTRAT correspondant aux 3 sous-namespaces.
Générez les scripts SQL
Sur le conteneur Previt_MPD_MySQL8.database, on peut générer les scripts SQL :
- Menu contextuel > IS designer > Generate SQL Scripts, un répertoire sql est créé, comportant 4 scripts pour les créations de contraintes, de clés étrangères, d'index et de tables et un script complet rassemblant les 4 précédents.
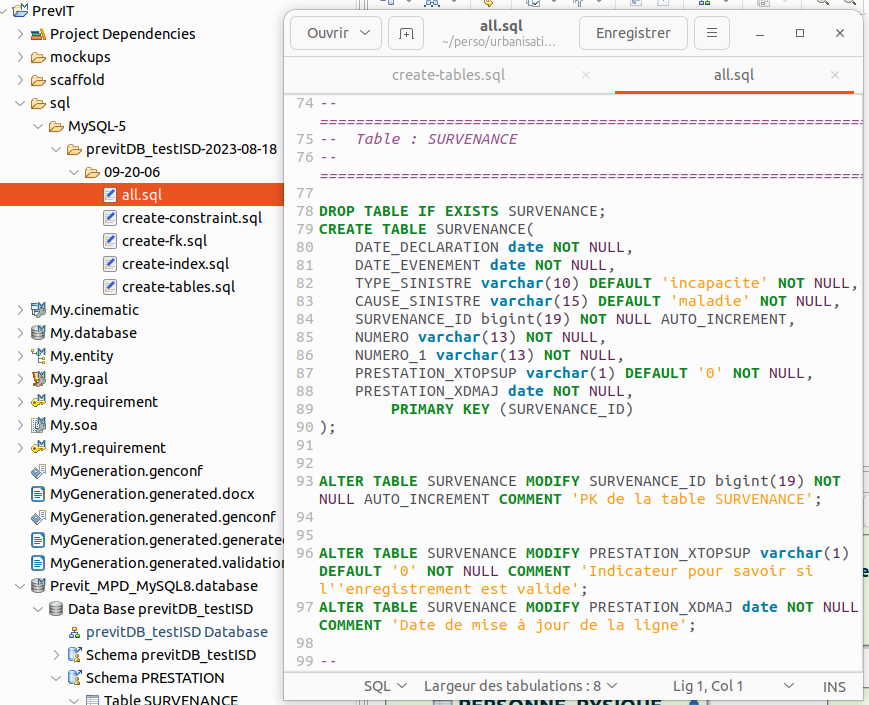
On trouve les scripts SQL correspondant au MPD. Ces scripts SQL devront être exécutés manuellement.
Exécutez les scripts SQL directement dans la base
Le générateur Liquibase permet d’exécuter directement des scripts dans la base.
- Sur le conteneur MySQLtest2.database, on peut générer les scripts SQL :
Menu contextuel > IS designer > Generate Liquibase changelog
Un répertoire liquibase est créé, contenant un fichier de propriété, permettant de configurer les accès à la base de données, et un fichier XML contenant les propriétés sous forme de balises avec les instructions SQL qui seront envoyées à la base par liquibase.
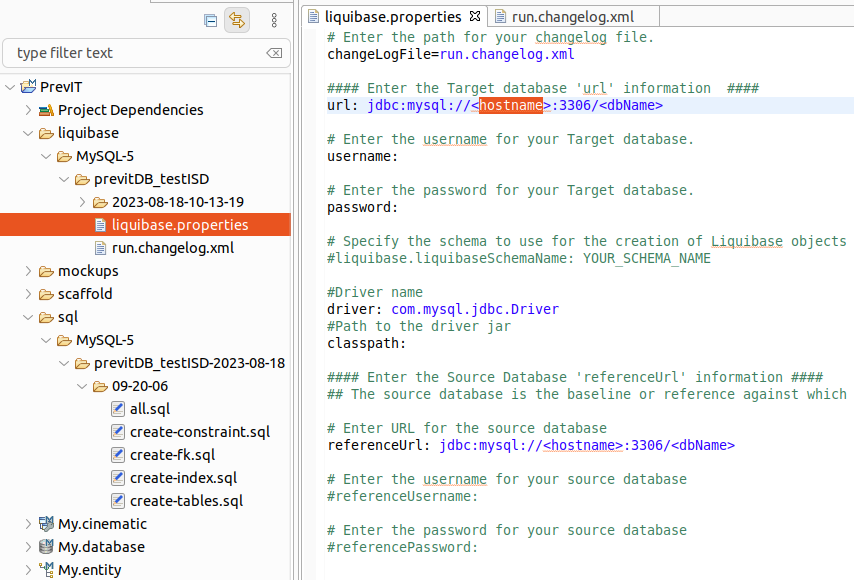
Vous devez valoriser les variables du fichier liquidbase.properties (<hostname>…).
Au lieu de configurer le fichier de propriétés liquibase, il existe une manière plus facile en utilisant le fichier run.changelog.xml :
- menu contextuel sur le fichier run.changelog.xml > Liquibase > Apply changing > saisir l’URL (jdbc:mysql://localhost:3306/previtDB_testISD), le user et le password
A ce moment, liquibase va se connecter directement et exécuter le fichier XML.
Nous avons rencontré 2 types d’exceptions :
- la 1re concernait l’impossibilité dans le fichier run.changelog.xml, de prendre en charge la propriété : column autoIncrement="true". Nous avons remplacé partout true par false,
- la 2e disait que les schémas (database) CONTRAT, PERSONNE et PRESTATION n’existaient pas. Effectivement, comme nous avions créé 3 sous-namespaces dans le namespace de base, 3 schémas ont été créés dans ISD, il faut donc naturellement les créer dans MySQL (dans notre cas MariaDB, compatible MySQL).
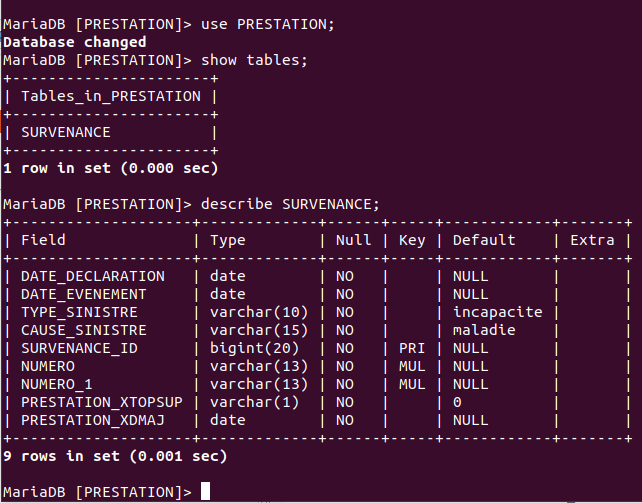
Extrait de la vérification de l'exécution des scripts SQL dans la console de la base de données.
Vous pouvez analyser les changements apportés grâce à l’historique :
- Menu contextuel sur le conteneur MLD .database > Compare With > Local History
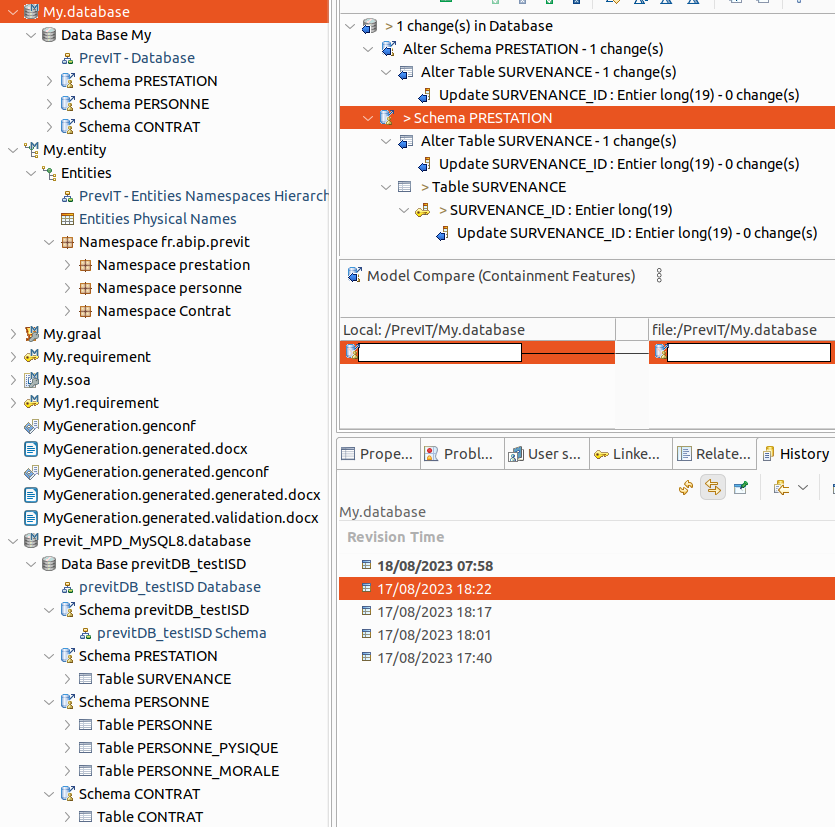
Exemple d'utilisation de l'historique.
Rétromodélisation et intégration de l’existant

Capacité à se connecter au format OpenAPI, en import, mais aussi en export.
Liquibase permet de piloter les schémas d’une base de données
à partir d’un diagramme de classes de conception.
On peut exporter et générer des previews avec SwaggerUI. Voir les copies d’écran dans la documentation github.
Génération documentaire
M2Doc généré à partir d’un template variabilisé.
La valorisation se fait à partir des modèles créés dans ISD.
Le Graal de l’agilité : générer une application directement à partir des modèles et de manière bidirectionnelle

La génération de code est basée sur des templates. Voir un exemple de template Acceleo en annexe 1.
Avec ISD, le processus est simple : vous modélisez la conception, puis vous générez le code. Vous pouvez modifier le code que vous avez généré. Si vous modifiez la conception, votre code est conservé. Le concept de génération se fait en round-trip, c’est-à-dire que l’on peut intégrer les parties de codes réalisées par les concepteurs/développeurs.
Plus on remonte dans les couches de l'architecture, moins on pourra générer de code.
Ainsi, 80 % du code backend peuvent être générés. Par exemple, 100 % des entités seront générés et plus de 50 % pour le métier. La couche de persistance est entièrement créée par le générateur d’ISD, auquel Obeo a ajouté les tests unitaires, ce qui n’est pas le cas des ORM classiques.
Les 20 % restants concernent les écrans laissés aux spécialistes frontend et certaines parties métier, comme des règles métier ou les machines à états, car les développeurs séniors produiront un code plus efficient.
Toute la partie architecture est sécurisée, car elle est mise en place par le générateur.
ISD utilise plusieurs générateurs de code open source, comme Acceleo de la fondation Eclipse et PACMAN du Ministère des Armées de la France.
A lire > Les générateurs de codes Acceleo et PACMAN
La mise en œuvre de ces outils passera souvent par les services payants d'Obeo.
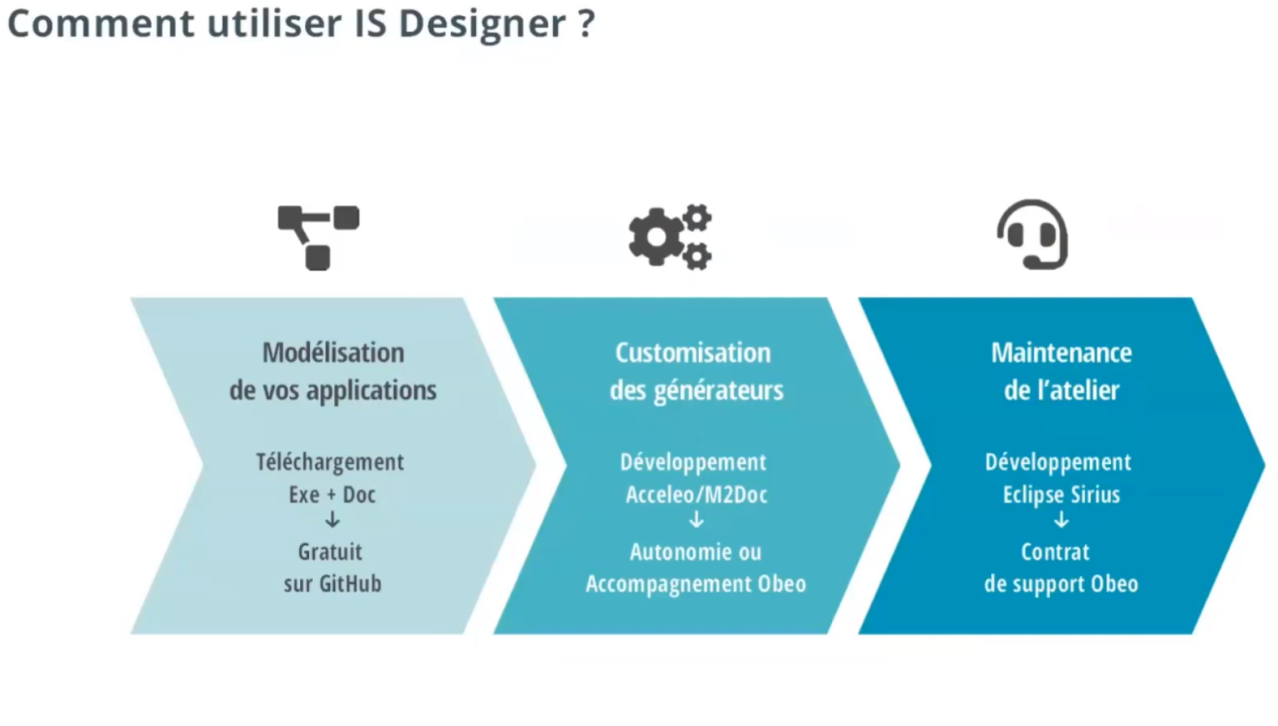
Ne vous enthousiasmez pas trop vite, à moins d'avoir une connaissance approfondie des techniques de génération de code, l'utilisation efficiente de ces générateurs demandera l'aide d'experts.
Obeo vous propose toute une série de modeleurs gratuits pour la partie analyse et modélisation de votre application. Si la fourniture des générateurs de code l’est aussi, leur utilisation reste extrêmement complexe. Obeo peut alors vous proposer, moyennant finance, un accompagnement. Il en va de même pour la maintenance et le support d’ISD.
Travail collaboratif avec l’extension payante
Obeo Designer Team
Pour le travail collaboratif, là encore il faudra mettre la main au porte-monnaie. En effet Obeo Designer Team est une extension commerciale, non-open source, permettant de partager des modèles, à la manière Google Doc.
Conclusion

Le couple de frameworks Sirius & Acceleo permet à ISD de produire
le code correspondant aux modèles de conception.
Les éloges
ISD d’Obeo est indubitablement un outil basé sur la collaboration de toutes les parties prenantes d’un projet de réalisation d’une application.
Avec ses différents ateliers, ISD vous aidera dans l’élaboration de la phase d’analyse (atelier Graal). Le cadre apporté par la méthode Graal vous facilitera la formalisation des use cases, avec les enchaînements d’actions, l’intégration des user stories, le modèle métier de vos données et la mise en place du référentiel d’exigences. L’atelier Cinematic vous permettra de concrétiser les scénarios des use cases, en maquettant les écrans et en planifiant la navigation. L’atelier SOA vous permettra d’élaborer votre architecture distribuée à base de micro-services ou de services web. Avec l’atelier Entity, vous définirez, parmi vos classes métier et DTO, lesquels doivent être persistants.
Les déceptions
Après avoir fait du NoUML, il est étrange qu’ISD ne supporte pas le NoSQL, comme (MongoDB, Cassandra…).
Nous regrettons aussi que le modeleur SOA Designer ne couvre que le type d’exposition REST. SOAP n’est disponible dans le studio qu’à titre indicatif, aucun outillage spécifique n’ayant été développé pour l’exploiter. Que vous utilisiez l'approche top-down, concevoir le contrat WSDL (Web Services Description Language), puis, à partir de celui-ci, faire générer le code ou l'approche inverse bottom-up, il vous faudra vous tourner vers les frameworks open source conventionnels du marché en fonction de votre langage de programmation. Autre solution, demander à Obeo, d'implémenter cette fonctionnalité, qui sera alors payante.
Open source oui, closed pour le reste.
A notre avis, l’atelier Database, qui génère les schémas logiques de base SQL, les scripts SQL et qui les exécute, ne présente que peu d'intérêt, car la plupart des technologies, Java, Python… possédant déjà des frameworks de synchronisation bidirectionnels entre les objets et le moyen de persistance, quelque soit son paradigme : SQL, NoSQL, voire XML.
Y a-t-il encore un intérêt pour les outils de génération de code
face à l'IA générative comme ChatGPT ?
La génération de code utilise des paradigmes comme MDA et des frameworks comme Acceleo, qui sont déjà anciens et qui semblent quelque peu désuets face à la puissance, la facilité et l’expansion phénoménale des nouvelles IA génératives (OpenAI ChatGPT, Microsoft Bing Chat, Google Bard ou encore Meta Llama, Anthropic Claude pour les plus connues).
Quelles sont leurs places dans le domaine de l’Architecture d’Entreprise, de l’Architecture Logicielle et la modélisation de système ? C’est l’étude que nous allons effectuer et que nous vous livrerons dans nos articles à venir.
Merci pour vos commentaires et peut-être serez-vous désireux de faire partager vos retours d’expérience ou vos idées sur l’architecture d’entreprise et l’art de la modélisation de système.
Alors, écrivez-nous et nous serons heureux de publier vos articles.
|
|
Rhona Maxwel @rhona_helena |
« Je me suis un peu amusée à tester ces nouveaux outils et ce que je trouve très intéressant, c’est que pour utiliser l’IA dans la phase de recherche et de documentation, il faut entrer des mots. Ça nous force quelque part à mettre des mots dès le départ sur une intention créative. C’est très utile pour formaliser et conceptualiser des idées. »
Adèle Hennion
Compléments de lecture
- Alimenter le référentiel d’Architecture d’Entreprise pour la couche Application de TOGAF avec l’outil Information System Designer (ISD) d’Obeo - Modélisation de l’analyse des besoins S.1 Ep.1
- Méthode Graal, le NoUML d’Obeo, parfaite fusion entre un UML phagocyté et un BPMN édulcoré. S.1 Ep.2
- Comment assurer la traçabilité des exigences avec les user stories, les use cases, les processus métier, la cinématique et les maquettes d'écrans ? Une solution dans notre test Obeo ISD S.1 Ep.3
- Quelle solution pour concevoir la modélisation d’une architecture micro-services, l’intégrer dans une architecture d’entreprise et permettre une collaboration avec l’ensemble des acteurs projet ? Obeo ISD S.1 Ep.4
- Ingénierie Dirigée par les Modèles (IDM) : tutoriel ATL (ATLAS Transformation Language)
- Query View Transform (QVT) Operational : tutoriel
- Démarche d’urbanisation du SI : les questions techniques, organisationnelles, voire existentielles
- Top 5 2023 des outils gratuits ou open source pour l’Architecture d'Entreprise et la modélisation du Système d’Information
Le meilleur outil pour transformer, dériver, parcourir, requêter sur des modèles afin de mettre en œuvre MDA (Model Driven Architecture)
Convaincue que certains outils open source et les normes sont aujourd'hui arrivés à maturités et présentent pour les entreprises de nombreux avantages, nous avons volontairement écarté les produits commerciaux et leurs langages propriétaires comme MEGA, IBM Rational, Entreprise Architect, ... pour nous consacrer uniquement à 2 solutions open source QVT (Query View Transformation) et ATL (ATLAS Transformation Language) implémentées dans Eclipse Modeling Tools.

Tous les langages de modélisation unanimement reconnus et largement utilisés que ce soit UML, OCL, BPMN, SysML, MDA, … proviennent de l'OMG (Object Management Group).
Dans le cadre de son framework MDA (Model Driven Architecture, ou on veut s’affranchir de cette marque déposée, on parle plus généralement de MDE Model Driven Engineering ou en français IDM Ingénierie Dirigées par les Modèles), l’OMG proposait, il y a maintenant 12 ans, QVT comme langage de manipulations de modèles.
Voir les articles sur MDA :
- Transformation de modèles et Ingénierie Dirigées par les Modèles (IDM ou MDE Model Driven Engineering ou bien encore MDA Model Driven Architecture)
- Ingénierie Dirigée par les Modèles : présentation MDA ( Model Driven Architecture ), mais est ce utilisé dans la vraie vie ?
Comme à son habitude, l'OMG fournit une documentation abondante très théorique à charge comme ils disent aux éditeurs de fournir des implémentations. Plus facile à dire qu’à faire.
Mais que signifie QVT ?
« Q » pour « Query », on peut sélectionner des éléments sur un modèle. Le langage utilisé pour cela est OCL (Object Constraint Language) légèrement modifié et étendu, avec une syntaxe différente et simplifiée.
Voir les articles sur OCL :
- Modélisation de système : comment utiliser OCL avec Eclipse, c'est bien la question que tout le monde se pose
- Modélisation de système : UML n'est rien sans OCL !
- Modélisation de système : OCL ça se complique !
- Modélisation de système : OCL vous en redemandez ?
- Modélisation de système : tutoriel OCL, la gestion des évènements
« V » pour « View » : une vue est une sous-partie d'un modèle et est définie via une query. Une vue est un modèle à part, avec éventuellement un méta modèle restreint spécifique à cette vue.
« T » pour « Transformation » : transformation d'un modèle en un autre.
Les habitués de l’OMG savent que leurs normes sont complètes et complexes afin de couvrir un périmètre très large.
QVT n’échappe pas à la règle puisqu’on dispose, excuser du peu, de 3 langages et 2 modes pour définir des transformations.
QVTo (Query View Tranformation Operational)
En utilisant ce langage, il vous faudra écrire l’algorithme d’implémentation comme dans un langage de programmation classique comme Java ou le langage C.
On exprime ce qu’on veut sans dire comment le réaliser comme par exemple XSLT pour les transformations d’arbre XML.
On trouve :
QVTr (Query View Tranformation Relational) : il s’agit d’un langage de haut niveau où on spécifie des correspondances entre des ensembles/patrons d'éléments de 2 modèles.
QVTc (Query View Tranformation Core) : plus bas niveau que QVTr, le langage est plus simple, mais avec le même pouvoir d'expression de transformations que QVTr.
La seule plateforme open source solide que j’utilise est Eclipse et pour l’IDM, la suite « Eclipse Modeling Tools ».
Le métamétamodèle maison est Ecore.
Voir les articles sur Ecore :
- Eclipse Modeling Framework (EMF) : revoyons les fondamentaux
- Le métamodèle Eclipse Ecore DMN ( Decision Model and Notation ) : comment concevoir son propre outil de modélisation DMN ? [2/4]
Au cours de mes différentes mission, l’outillage de cartographie des systèmes d’information et la conception de méta modèle ont toujours reposé sur Ecore.
On trouve des méta modèles Ecore pour les langages de modélisation (DMN, …), les différents cadres d’architectures d’entreprise (Praxeme, TOGAF, Urba-EA, ...), des langages aussi spécifiques comme ceux de règles métiers (DROOLS), …
A la date de cet article, la version Oxygen d'Eclipse, intègre la plupart des plugins (Ecore, OCL, Sirius) et ceux qui manquent peuvent être installés directement dans le menu Help – Install Modeling Components, c'est le cas de QVTo et ATL.
Plus la peine d’être un geek pour installer un plugin.
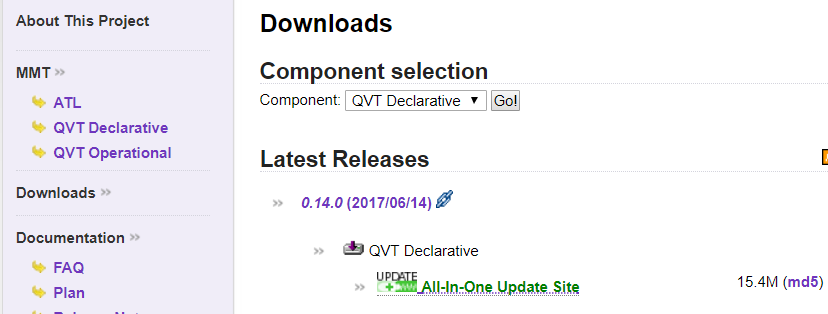
Malheureusement, c’était trop beau pour être vrai, si effectivement ATL et QVTo ne pose pas de problèmes, QVTr (appélé QVTd Declarative dans Eclipse) n’est pas proposé dans la liste et pour cause, le projet est en incubation.
Voici le lien si vous voulez évaluez l’état d’avancement.
http://www.eclipse.org/mmt/downloads/?project=qvtd
Il vous faudra donc vous bagarrez, téléchargez, dézippez et installez dans Eclipse qvtd-incubation-Update-0.14.0.zip.
QVTr (Query View Tranformation Relational, (appélé QVTd Declarative dans Eclipse)

QVTr par sa nature, est limité aux relations entre les éléments de modèle source et cible.
Il permet d'exprimer une représentation de haut niveau des transformations de modèle à modèle. Mais il est parfois difficile de faire des transformations complexes dans un style déclaratif tel qu'utilisé dans QVTr.
QVTr suffit pour les transformations simples.
La performance est très faible.
Il est possible de manipuler de petits modèles contenant quelques centaines d'éléments mais l'utiliser avec des modèles plus gros donne des résultats de temps d'exécution énormes.
La principale raison en est le mécanisme d’identification de schémas et le fait que chaque relation doit être établie pour que la transformation réussisse.
Pour chaque relation dans la transformation, il est nécessaire de passer en revue tout le modèle pour toutes les correspondances et de les maintenir.

QVTo (Query View Tranformation Operational)
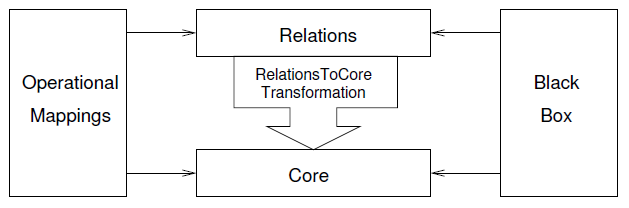
QVTo (Query View Tranformation Operational) pour le mode impératif, étend QVTr avec des constructions impératives comme le « if », … (extension d’OCL). Il possède une « Black Box », qui est un mécanisme pour appeler un programme externe.
Pour un exemple complet des possibilités de QVTo, voir le tutoriel :

ATL (ATLAS Transformation Language)

Le langage de transformation ATL (ATLAS Transformation Language) est un langage (french tech) et un ensemble de transformation prêtes à l’emploi, développé et maintenu par OBEO et INRIA-AtlanMod (2006). Il a été initié par l'équipe AtlanMod (précédemment appelée ATLAS Group).
Les objectifs sont de :
- Faciliter la résolution de problème d’interopérabilité entre systèmes,
- Résoudre les problèmes de développement logiciel
- Traiter des structures de données hétérogènes
Dans le domaine de l'IDM (MDE), ATL fournit des moyens de produire un ensemble de modèles cibles à partir d'un ensemble de modèles sources.
Publié selon les termes de la Licence publique Eclipse, ATL est un composant M2M (Eclipse), à l'intérieur du Projet de modélisation Eclipse (EMP Eclipse Modeling Project).
ATL est basé sur QVT qui est un groupe de gestion des objets standard pour effectuer des transformations de modèles. Il peut être utilisé pour faire une traduction syntaxique ou sémantique.
ATL est construit sur une machine virtuelle de transformation de modèles.
Les outils de transformation liés à ATL sont intégrés sous forme de plug-in ADT (ATL Development Tool) pour l’environnement de développement Eclipse.
Un modèle de transformation ATL se base sur des définitions de métamodèles au format XMI. Sachant qu’il existe des dialectes d’XMI, ADT est adapté pour interpréter des métamodèles décrits à l’aide d’EMF Ecore (Eclipse) ou MDR (NetBeans).
ATL est défini par un modèle MOF pour sa syntaxe abstraite et possède une syntaxe concrète textuelle.
Pour accéder aux éléments d’un modèle, ATL utilise des requêtes sous forme d’expressions OCL. Une requête permet de naviguer entre les éléments d’un modèle et d’appeler des opérations sur ceux-ci.
Une Called Rule est appelée explicitement en utilisant son nom et en initialisant ses paramètres.
ATL supporte deux modes d’exécution différents : le mode standard et le mode par raffinement.
Dans le mode standard, les éléments sont créés seulement quand les patterns sources définis dans les règles déclaratives ont été reconnus dans le modèle ; le système instancie alors les éléments du pattern cible. Une fois l’étape d’instanciation passée, un lien de traçabilité est créé, et associe chaque élément reconnu du modèle source à un élément du modèle cible. Finalement, le système évalue ensuite ces liens de traçabilité afin de déterminer les valeurs des propriétés des éléments instanciés.
Dans le mode par raffinement, les éléments dont les patterns sources non pas été matchés par les règles sont automatiquement copiés dans le modèle cible par le moteur d’exécution. Ceci réduit considérablement le développement de transformations destinées à modifier une petite partie d’un modèle en gardant le reste inchangé.
L'écriture d’une transformation dans ATL est assez simple et la partie impérative d'une règle ATL aide beaucoup à gérer la création des éléments et le flux d’exécution. Il est également possible de générer la cible et de lier les modèles directement dans une exécution afin de rendre la règle plus intuitive.
ATL est une implémentation de la proposition QVT, mais c'est un langage hybride à la fois déclaratif et impératif. Cela améliore son expressivité et s'accorde avec la capacité à exprimer toute forme de transformation mais contrairement à QVT, les transformations ATL sont unidirectionnel.
Dans QVTr, les appels d'une relation à l'autre se font via la clause where mais dans ATL, ce n'est pas le seul moyen d'appeler d'autres règles.
Il est possible de spécifier dans une règle que la spécification d’un élément mappé doit être transformé en transformant un élément spécifique du modèle source.
En utilisant ce mécanisme, il est possible de réduire le nombre d'éléments qui doivent être adaptés dans une règle de transformation.
Le fait que ATL est également compilé et exécuté dans une machine virtuelle rend l'exécution plus rapide que l'interprétation classique des règles de transformation.
Le plugin ATL pour Eclipse est depuis plusieurs années dans un état finalisé, complet, stable, robuste, performant, supportant des modèles volumineux et s’inspire de QVTr et QVTo.
Je l’ai utilisé pour la migration d’un modèle de données vers un nouveau dans le cadre d’une fusion de 2 organisations qui en profitaient pour urbaniser et intégrer des innovations dans leur nouveau Système d’Information.
Vous trouverez ci-dessous un cours exhaustif en français sur ATL.
- Ingénierie Dirigée par les Modèles (IDM) : tutoriel ATL (ATLAS Transformation Language), concevez les métamodèles avant de passer aux choses sérieuses
- Ingénierie Dirigée par les Modèles (IDM) : tutoriel ATL (ATLAS Transformation Language), le "Da Vinci code" de la transformation ATL
- Ingénierie Dirigée par les Modèles (IDM) : documentation ATL (ATLAS Transformation Language), vous saurez tout ou presque sur les modules
- Ingénierie Dirigée par les Modèles (IDM) : cours complet sur ATL (ATLAS Transformation Language)
- Ingénierie Dirigée par les Modèles (IDM) : cours complet sur ATL (ATLAS Transformation Language) : librairie ATL
- Ingénierie Dirigée par les Modèles (IDM) : cours complet sur ATL (ATLAS Transformation Language) : les types ATL
- Cours complet sur ATL (ATLAS Transformation Language) : les types primitifs
- Cours complet sur ATL (ATLAS Transformation Language) : les collections
- Cours complet sur ATL (ATLAS Transformation Language) : les énumérations
- Cours complet sur ATL (ATLAS Transformation Language) : les tuples
- Cours complet sur ATL (ATLAS Transformation Language) : les éléments de modèles des métamodèles
- Cours complet sur ATL (ATLAS Transformation Language) : Les expressions déclaratives dans OCL / ATL
- Cours complet sur ATL (ATLAS Transformation Language) : quelques trucs et astuces sur les expressions
- Cours complet sur ATL (ATLAS Transformation Language) : les helpers
- Cours complet sur ATL (ATLAS Transformation Language) : introduction aux règles ATL
- Cours complet sur ATL (ATLAS Transformation Language) : le code impératif ATL, l’instruction d’affectation
- Cours complet sur ATL (ATLAS Transformation Language) : le code impératif ATL, l’instruction de test : if
- Cours complet sur ATL (ATLAS Transformation Language) : le code impératif ATL, l’instruction de boucle : for
- Cours complet sur ATL (ATLAS Transformation Language) : les “Matched Rules” (les règles de correspondance), présentation (1/5)
- Cours complet sur ATL (ATLAS Transformation Language) : les “Matched Rules”, la section “from” (pattern source) (2/5)
- Cours complet sur ATL (ATLAS Transformation Language) : les “Matched Rules”, la section des variables locales (3/5)
- Cours complet sur ATL (ATLAS Transformation Language) : les “Matched Rules”, le pattern élément cible (4/5)
- Cours complet sur ATL (ATLAS Transformation Language) : les “Matched Rules”, la section bloc impératif (5/5)
- Cours complet sur ATL (ATLAS Transformation Language) : les règles paresseuses (Lazy Rules)
- Cours complet sur ATL (ATLAS Transformation Language) : les règles appelées (Called Rules)
- Cours complet sur ATL (ATLAS Transformation Language) : l’héritage des règles
- Cours complet sur ATL (ATLAS Transformation Language) : De la bonne utilisation des règles dans le langage ATL
- Cours complet sur ATL (ATLAS Transformation Language) : le mode “affiné” ATL
- Cours complet sur ATL (ATLAS Transformation Language) : les requêtes ATL
- Cours complet sur ATL (ATLAS Transformation Language) : les mots clés ATL
- Cours complet sur ATL (ATLAS Transformation Language) : pour terminer, une dernière chose à laquelle il faut prendre garde !
- Le plugin ATL (ATLAS Transformation Language) pour Eclipse : les étapes pour réaliser une transformation (1/2)
- Le plugin ATL (ATLAS Transformation Language) pour Eclipse : les étapes pour réaliser une transformation (2/2)
Rhona Maxwel
@rhona_helena
"Créer, c'est donner une forme à son destin."
Albert Camus
Articles conseillés :
- Pour trouver les services logiques, les modèles sémantiques et pragmatiques tu dériveras. (« Praxeme 4ème commandement extrait de la bible de l’aspect logique »).
- Urbanisation SI : comment marche le méta-modèle ?
- Libérez-vous, laissez votre stratégie prendre le leadership"
- Avec un peu de métier, métamodéliser la vue métier pour assurer la traçabilité avec la stratégie
- En urbanisation SI, comment définit-on la vue fonctionnelle et quels sont les liens avec la vue métier et applicative ?
- En urbanisation SI, comment met on en oeuvre la traçabilité entre la vue applicative et les vues fonctionnelle et infrastructure ?
- Le Big-Mac de l'urbanisation SI
Transformation de modèles et Ingénierie Dirigées par les Modèles (IDM ou MDE Model Driven Engineering ou bien encore MDA Model Driven Architecture)
L'architecture d'entreprise qui inclut l'urbanisation des Systèmes d'Information ne cesse de prôner la transformation ou dérivation des couches la composant, stratégie en métier, métier en fonctionnelle, fonctionnelle en applicative et applicative en infrastructure à des fins d'automatisation, de traçabilité et de gouvernance.
C'est la que rentre en jeu, l’Ingénierie Dirigées par les Modèles (IDM ou MDE Model Driven Engineering ou bien encore MDA Model Driven Architecture) qui repose sur la volonté de décrire précisément les besoins des clients par des CIM (Computational Independent Models) et la connaissance métier d’une organisation dans des modèles abstraits indépendants des plates-formes (PIM - Platform Independent Models).
Ayant isolé le savoir-faire métier dans des PIM, on a besoin soit de transformer ces modèles en d’autres PIM (besoin d’interopérabilité, migration vers un nouveau système, fusion de SI en cas d’acquisition d’une autre organisation, …), soit de produire ou de créer des modèles PSM (Platform Specific Models) ciblant une plate-forme d’exécution spécifique (pour améliorer la portabilité et augmenter la productivité).
Dans le cadre de l’IDM, les artefacts manipulés sont des modèles.
Ces types de modèles sont donc des méta-modèles.
Un méta-modèle est un modèle qui définit les concepts d'un modèle d'instance.
Cette relation est purement syntaxique.

La Meta-Object Facility (MOF) de la norme OMG à quatre couches (M0, M1, M2, M3) est l’architecture de méta-modélisation.
Voir ci-dessous un article que j'avais consacré aux métamodèles :
Par exemple, le métamodèle de UML (Unified Modeling Language) est un modèle M2 du MOF.
De même, tous les langages spécifiques à un domaine (DSL Domain Specific Language) peuvent également être exprimé en modèles MOF.
Le noyau de MOF permet seulement d'exprimer des propriétés structurelles simples,
Associations similaires entre éléments, encapsulation, cardinalité, etc.
Le langage de contraintes d'objet (OCL Object Constraint Language) est un langage de contrainte déclaratif d’instructions ordonnées standard et un langage de requête, qui est utilisé pour associer des règles à des modèles.
Par exemple, on peut spécifier une structure, des invariants, des définitions et des pré/post conditions, des opérations MOF abstraites dans la langue OCL.
Voir mes tutoriaux sur OCL :
- Modélisation de système : comment utiliser OCL avec Eclipse, c'est bien la question que tout le monde se pose
- Modélisation de système : UML n'est rien sans OCL !
- Modélisation de système : OCL ça se complique !
- Modélisation de système : OCL vous en redemandez ?
- Modélisation de système : tutoriel OCL, la gestion des évènements
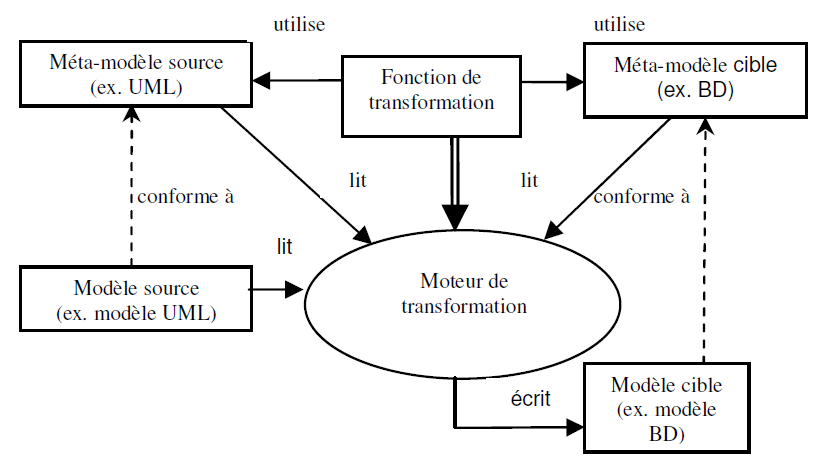
Le métamodèle de transformation contient trois éléments essentiels : source, cible et relation de transformation ou dérivation.
La relation de transformation est un ensemble de liens explicites entre les éléments de la source et le modèle cible.
Ces liens explicites jouent un rôle clé dans l’approche IDM.
Les relations entre les métamodèles définissent la structure des liens et des propriétés qu'ils doivent satisfaire et le méta-modèle de transformation, les liens qui doivent exister.
Une transformation de modèles est la génération d’un ou de plusieurs modèles cibles à partir d’un ou de plusieurs modèles sources.
Une transformation des entités du modèle source met en jeu deux étapes.
L’approche par modélisation consiste quant à elle à appliquer les concepts de l’ingénierie des modèles aux transformations des modèles elles-mêmes.
Une transformation endogène se situe dans le même espace technologique et les modèles source et cible sont conformes au même méta- modèle.
Par exemple transformation d'un modèle UML en un autre modèle UML
Une transformation exogène se situe entre 2 espaces technologique différents et les modèles source et cible sont conformes à des méta- modèles différents.

Une transformation en série peut servir à réaliser une application ou un processus basé sur une série de transformations de modèles.
Les types d’outils de transformation de modèles :
- Langage de programmation « standard » : Ex : Java, pas forcément adapté pour tout, sauf si interfaces spécifiques, ex : framework Eclipse/EMF
- Langage dédié d'un atelier de génie logiciel : Ex : MDG pour l’AGL Enterprise Architect, Langage de script de l’AGL MEGA, MDA Modeler IBM Rational, souvent propriétaire et inutilisable en dehors de l'AGL
- Langage lié à un domaine/espace technologique : Ex: XSLT dans le domaine XML, AWK pour fichiers texte ...
- Langage/outil dédié à la transformation de modèles : Ex : la norme QVT (Query View Transform) de l'OMG, le standard de l’industrie actuellement : ATL (Atlas Transform Language)
3 grandes familles de modèles et outils associés :
- Données sous forme de séquence : Ex : fichiers textes (AWK)
- Données sous forme d'arbre : Ex: XML (XSLT)
- Données sous forme de graphe : Ex : diagrammes UML, outils : QVT, ATL, …
3 grandes catégories de techniques de transformation :
- Approche déclarative : recherche de certains patrons (d'éléments et de leurs relations) dans le modèle source. Chaque patron trouvé est remplacé dans le modèle cible par une nouvelle structure d'élément. L’écriture de la transformation est « assez » simple mais ne permet pas toujours d'exprimer toutes les transformations facilement.
- Approche impérative : proche des langages de programmation usuels, on parcourt le modèle source dans un certain ordre et on génère le modèle cible lors de ce parcours. L’écriture transformation peut être plus lourde mais permet de toutes les définir, notamment les cas algorithmiquement complexes.
- Approche hybride : à la fois déclarative et impérative. La plupart des approches déclaratives offrent de l'impératif en complément car plus adapté dans certains cas.
Les référentiel pour stocker les modèles et méta-modèles utilise XMI (XML Interchange, norme de l'OMG).
Les principales implémentations des langages de transformation de modèles ATL et QVT utilisent le métamétamodèle Ecore d'Eclipse qui est le standard de l'industrie. On retrouve tous les principaux concepts du niveau M3 UML du MOF de l'OMG.
On trouve les métamodèles Ecore à peu près pour tout, les langages de modélisation normalisés (UML, SysML, BPMN, DMN, BMM, SOAML, ...) et même des langages open source comme celui de DROOLS, le moteur de règles métier, standard de l'industrie.
Voir mes articles sur Ecore :
- Eclipse Modeling Framework (EMF) : revoyons les fondamentaux
- Ingénierie Dirigée par les Modèles (IDM) : tutoriel Eclipse Ecore, le corps à corps avec les méta modèles
Les cadres d'architecture d'entreprise comme TOGAF (The Open Group Architecture Framework), Praxeme, ... énoncent des principes de dérivation des différents niveaux ou aspects. Mais aucune ne précise avec quels outils.
Alors, la question qui me tourmente, avez-vous ou votre organisation, mis en place des transformations de modèles et avec quels outils ?
Rhona Maxwel
@rhona_helena
"Parmi les objets répandus au hasard, le plus beau c'est le cosmos. L'harmonie invisible est plus belle que le visible."
Héraclite d'Ephèse
Articles conseillés :
- INGÉNIERIE DIRIGÉE PAR LES MODÈLES (IDM)
- Pour trouver les services logiques, les modèles sémantiques et pragmatiques tu dériveras. (« Praxeme 4ème commandement extrait de la bible de l’aspect logique »).
- Model-Driven Engineering (MDE) : modèles, métamodèles, métamétamodèles, méta... ?
- Ingénierie Dirigée par les Modèles (IDM) : le tour de passe-passe des transformations de modèles
- Le métamodèle Eclipse Ecore DMN ( Decision Model and Notation ) : comment concevoir son propre outil de modélisation DMN ? [2/4]
Pour trouver les services logiques, les modèles sémantiques et pragmatiques tu dériveras. (« Praxeme 4ème commandement extrait de la bible de l’aspect logique »).
La bible de la méthodologie d’architecture d’entreprise franco française Praxeme, énonce entre autres que l’architecture logique prolonge les décisions d’urbanisation du SI et que les services et données dérivent des modèles amont c’est-à-dire des aspects sémantique (entités métiers) et pragmatique (processus métiers et cas d’utilisation).
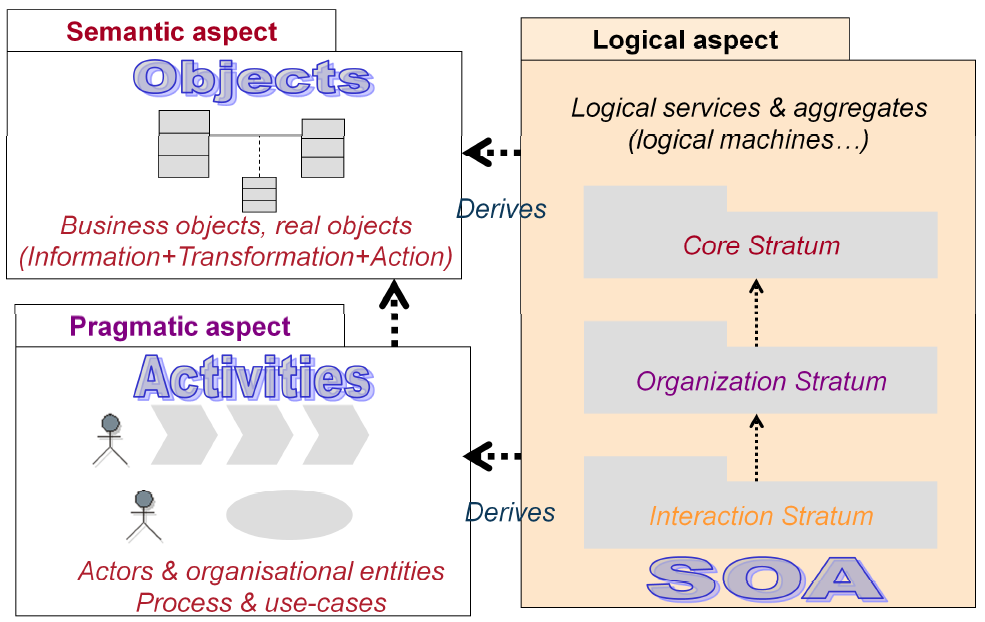
En 2006, le buzz était sur l’architecture SOA (Service Oriented Architecture) et je me suis intéressée à Praxeme qui était une des seules méthodes SOA open source et cerise sur le gâteau en français.
Aujourd’hui, Praxeme est à l’architecture d’entreprise ce que la théorie unifiée est à la physique.
Praxeme agrège toutes les bonnes pratiques en cours, allant de la stratégie d’entreprise à la réalisation d’applications informatiques en passant par l’urbanisation du Système d’Information, la gouvernance SI, l’architecture technique, SOA, l’ingénierie dirigée par les modèles jusqu’aux bonnes pratiques de conception.
On peut dire que Praxeme n’a rien inventé, mais elle a le mérite d’avoir intégré avec succès toutes ces bonnes pratiques avec une terminologie bien à elle.
Par exemple, la dérivation des aspects sémantique et pragmatique en aspect logique s'inspire de MDA (Model Driven Architecture, norme OMG) à la transformation du niveau CIM (Computational Independent Model) en PIM (Platform Independent Model) ou bien encore dans le monde de l’urbanisation du Système d’Information, à la cartographie métier qui se projette sur la cartographie fonctionnelle.
Voici quelques articles que nous avions consacrés sur ces sujets :
1) Sur les transformations des vues de l'urbanisation du Système d'Information
- Urbanisme SI : la nécessité d'un "espéranto"
- On remet une couche sur le cadre d'urbanisation SI ?
- Urbanisation SI : comment marche le méta-modèle ?
- Libérez-vous, laissez votre stratégie prendre le leadership"
- En cas d'évènements imprévus, votre SI doit savoir jouer les "Transformers" !
- Avec un peu de métier, métamodéliser la vue métier pour assurer la traçabilité avec la stratégie
- En urbanisation SI, comment définit-on la vue fonctionnelle et quels sont les liens avec la vue métier et applicative ?
- En urbanisation SI, comment met on en oeuvre la traçabilité entre la vue applicative et les vues fonctionnelle et infrastructure ?
2) Sur l'Ingénierie Dirigée par les Modèles (MDE Model Driven Engineering)
- Model-Driven Engineering (MDE) : modèles, métamodèles, métamétamodèles, méta... ?
- Ingénierie Dirigée par les Modèles : présentation MDA ( Model Driven Architecture ), mais est ce utilisé dans la vraie vie ?
Pour pouvoir manipuler un modèle, on doit avoir son méta-modèle.
Mais où est passé le méta-modèle Praxeme ?
Sur le site officiel :
http://www.praxeme.org/telechargements/catalogue/
il est indiqué que le document PxMDS-05 traitant du méta-modèle est « en cours ».
Mais il y a un bouton « Visiter » qui nous renvoie sur la page :
http://wiki.praxeme.org/index.php?n=Modus.PraxemeMetamodel
Le lien « Le méta-modèle Praxeme » nous envoie à :
http://wiki.praxeme.org/Praxeme.MetaModel/index.html
Nous arrivons sur un diagramme de package cliquable mais malheureusement quand on clique sur un package, on arrive sur une description textuelle des entités mais point de diagramme de classe représentant le méta-modèle.
Plus grave, quand on clique sur le deuxième lien « Caisse d’allocations Familiales », un autre lien « méta-modèle Praxeme » nous répond « Error 404, page not-found ».

Notre objectif est de réaliser des prototypes, les extraits fournis dans les différents évangiles Praxeme seront donc parfaits pour nos démonstrateurs.
Voyons d’un peu plus près à quoi ressemblent les règles de dérivation.
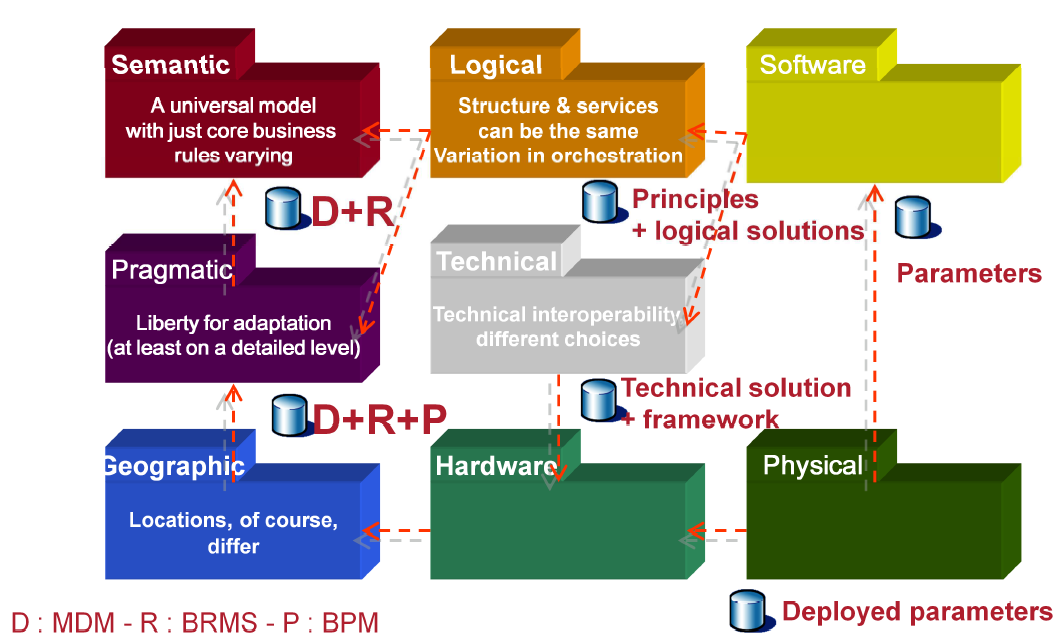
Par exemple une classe sémantique (métier) devient une Machine Logique Métier élémentaire (attributs, opérations, associations et navigations) et une Machine Logique Métier ensembliste (services sur les collections).
Le modèle pragmatique composé de la vue de l’utilisation (use case) et la vue de l’organisation (processus métier, diagramme d’activité).
Par exemple, concernant la première, un use case devient une Machine Logique Organisation et un Service Logique Transactionnel.
Pour la dérivation des processus métier, la méthode parle d’un dispositif transverse chargé de l’ordonnancement et de l’exécution des services autrement dit un moteur de processus exécutables, BPM Business Process Management.
Pour la dérivation des règles métiers 2 solutions sont envisagées :
- La programmation de la règle en dur
- L’enregistrement dans un dispositif ad hoc autrement dit un moteur de règles, BRMS Business Rules Management System.
La méthode devrait intégrer plus clairement le couple de normes (BPMN, DMN).
BPMN (Business Process Model and Notation) pour les processus métiers (aspect pragmatique vue organisation), et la norme DMN (Decision Model and Notation) pour les règles métiers (aspect sémantique).
Et pourquoi pas SOAML (SOA Modeling Language) pour les aspects logiques et les services ?
L’OMG (Object Management Group) fourni pour toutes ces normes, les méta-modèles complets avec leurs diagrammes de classes accompagnés des description textuelles.
Ainsi en utilisant des outils de transformation de modèles, il est possible d'industrialiser les processus et les règles de dérivation des aspects Praxeme.
Les aspects stratégiques peuvent être modélisés en utilisant la norme BMM (Business Motivation Model) que l'on pourrait dériver en aspects sémantique et pragmatique.
Et pourquoi pas dériver le couple (BPMN, DMN) en modèle de code (PSM Platform Specific Model) d’un moteur de processus métier ou de règles métiers, par exemple le couple open source bien intégré (jBPM, Drools).
Voir la série d’articles sur jBPM :
- Exemple d'un moteur de processus exécutable : tutorial jBPM #01
- Exemple d'un moteur de processus exécutable : tutorial jBPM #02
Voir la série d’articles sur les moteurs de règles métiers :
- Drools le moteur de règles métiers open source (BRMS)
- A quoi sert un moteur de règles ?
- Les étapes d’un projet avec un moteur de règles
- Quand faut il utiliser un moteur de règles ?
- Qui fait fonctionner un moteur de règles ?
- Comment concevoir une règle ?
- BRMS Moteur de règles : mais que fait IBM ?
Comment automatiser ces transformations, (en praxemien on parle de dérivations car le terme transformation implique une modification du modèle source) ?
De nombreuses solutions existent comme XSLT (XML Stylesheet Language Transformation), ATL (Atlas Transformation Language), QVT (Query View Language), …
Voir par exemple le cours complet sur ATL et le tutoriel QVT.
1) ATL (Atlas Transformation Language)
- Ingénierie Dirigée par les Modèles (IDM) : tutoriel ATL (ATLAS Transformation Language), concevez les métamodèles avant de passer aux choses sérieuses
- Ingénierie Dirigée par les Modèles (IDM) : tutoriel ATL (ATLAS Transformation Language), le "Da Vinci code" de la transformation ATL
- Ingénierie Dirigée par les Modèles (IDM) : documentation ATL (ATLAS Transformation Language), vous saurez tout ou presque sur les modules
- Ingénierie Dirigée par les Modèles (IDM) : cours complet sur ATL (ATLAS Transformation Language)
- Cours complet sur ATL (ATLAS Transformation Language) #01
- Cours complet sur ATL (ATLAS Transformation Language) #02
- Cours complet sur ATL (ATLAS Transformation Language) #03
- Cours complet sur ATL (ATLAS Transformation Language) #04
- Cours complet sur ATL (ATLAS Transformation Language) #05
- Cours complet sur ATL (ATLAS Transformation Language) : pour terminer, une dernière chose à laquelle il faut prendre garde !
2) QVT
Mais laquelle choisir ?
C’est ce que nous verrons prochainement.
Rhona Maxwel
@rhona_helena
"Et le secret de toute la méthode est là : en toute choses repérer soigneusement ce qui est le plus absolu."
René Descartes
Articles conseillés :
Comment être efficace dans la modélisation de vos cas d'utilisation (UML use case diagram) ?
SysML pour les nuls : de la modélisation des exigences à la réalisation du système
Query View Transform (QVT) Operational : tutoriel, plus simple tu meurs !
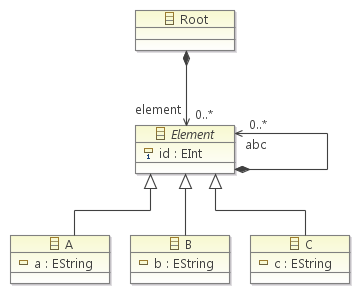
Mes derniers articles sont consacrés au langage de transformation de modèles ATL (Atlas Transformation Language).
Voir par exemple le tutoriel complet :
ou bien le cours complet qui commence :
ATL est un langage opensource, largement utilisé utilisé dans l'industrie. Son implémentation est robuste et performante. Et surtout il existe des outils fiables comme le plugin pour Eclipse.
Mais ATL n'est pas une norme.
Son concurrent à l'avantage d'être une norme de l'OMG Object Management Group , l'organisation qui a fait notamment UML, MDA, ...
Il s'agit de QVT (Query View Transform). Il existe 2 types de QVT : QVTd (déclaratif, diisé en QVTr Relation et QVTc Core), équivalent des "matched rules" ATL et QVT Operational (impératif), équivalent des "called rules" ATL.
QVT avec son pédigré, pourrait être "La Solution" ultime pour transformer des modèles.
Seulement voilà, comme très souvent dans les normes, QVT souffre d'une grande complexité.
Mais il y a pire ! Les outils l'implémentant sont rares et incomplet. Seul QVTo commence à être implémenté alors que QVT-Relation est à l'état d'embryon.
Eclipse propose un plugin pour QVT Operational et un autre non finalsé pour QVT Relation.
Pour l'installer :
- http://projects.eclipse.org/projects/modeling.mmt.qvt-oml/downloads
- Décompressez le zip dans un répertoire.
- Dans Eclipse, allez dans le menu Help - Install new software - Add - Local - sélecionnez le répertoire - nommez et OK
N'échapperons pas à la règle de commencer par le traditionnel "Hello world" que font tous les débutants dans un langage.
Tout d'abord le métamodèle source et cible dans notre cas de tutoriel "plus simple tu meurs", voici son fichier Ecore (ABC.ecore) :
<ecore:EPackage xmi:version="2.0" xmlns:xmi="http://www.omg.org/XMI" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:ecore="http://www.eclipse.org/emf/2002/Ecore" name="ABC" nsURI="http:///ABC.ecore" nsPrefix="ABC">
<eClassifiers xsi:type="ecore:EClass" name="Root">
<eStructuralFeatures xsi:type="ecore:EReference" name="element" upperBound="-1"
eType="#//Element" containment="true"/>
</eClassifiers>
<eClassifiers xsi:type="ecore:EClass" name="A" eSuperTypes="#//Element">
<eStructuralFeatures xsi:type="ecore:EAttribute" name="a" eType="ecore:EDataType http://www.eclipse.org/emf/2002/Ecore#//EString"/>
</eClassifiers>
<eClassifiers xsi:type="ecore:EClass" name="B" eSuperTypes="#//Element">
<eStructuralFeatures xsi:type="ecore:EAttribute" name="b" eType="ecore:EDataType http://www.eclipse.org/emf/2002/Ecore#//EString"/>
</eClassifiers>
<eClassifiers xsi:type="ecore:EClass" name="C" eSuperTypes="#//Element">
<eStructuralFeatures xsi:type="ecore:EAttribute" name="c" eType="ecore:EDataType http://www.eclipse.org/emf/2002/Ecore#//EString"/>
</eClassifiers>
<eClassifiers xsi:type="ecore:EClass" name="Element" abstract="true">
<eStructuralFeatures xsi:type="ecore:EAttribute" name="id" lowerBound="1" eType="ecore:EDataType http://www.eclipse.org/emf/2002/Ecore#//EInt"/>
<eStructuralFeatures xsi:type="ecore:EReference" name="abc" upperBound="-1" eType="#//Element"
containment="true"/>
</eClassifiers>
</ecore:EPackage>
Créer un nouveau projet : File - New - Project - Eclipse Modeling Framework -Empty EMF Project
Clic droit sur ABC.ecore - Initialize ecore diagram : pour générer le diagramme du modèle, cela ne peut pas faire de mal !
Double clic droit sur ABC.genmodel - clic droit sur ABC (2 ème icône dans la hiérarchie) - Generate All
Clic droit sur le projet - run As - Run Configurations - onglet Arguments - VM arguments :
-Dosgi.requiredJavaVersion=1.6 -Xms256m -Xmx768m -XX:MaxPermSize=256m
puis Run
Une nouvelle instance d'Eclipse se lance pour exécuter le nouveau plugin.
File - New - Project - Model to Model Transformation - Operational QVT Project.
Nommez votre projet
Ecrire le source de la transformation :
transformation NewTransformation(in source:ABC, out target:ABC);
main() {
source.rootObjects()[Root]->map Root2Root();
}
mapping Root :: Root2Root() : Root {
element += self.element->select(a |
a.oclIsKindOf(A))[A]->map A2B();
}
mapping A :: A2B() : B
when {
self.id > 0
}
{
result.id := self.id;
result.b := self.a + " World!";
}
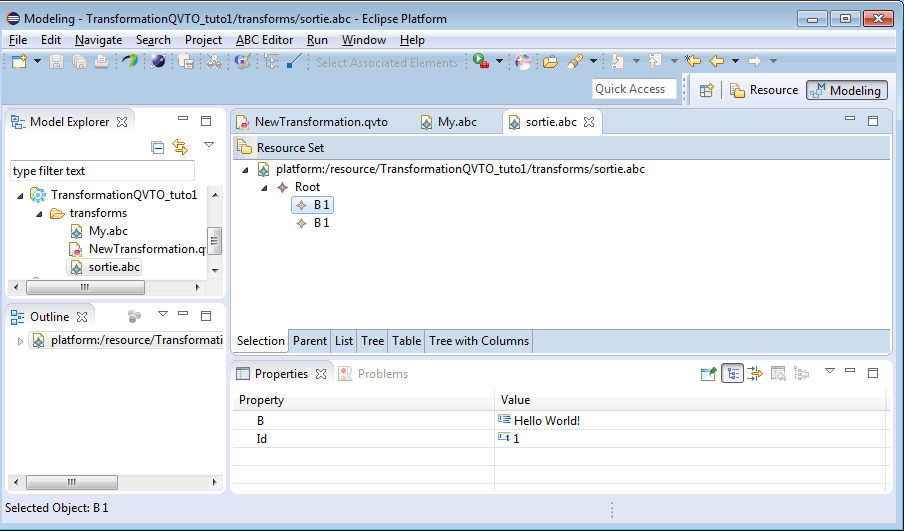
A est transformé en B, en utilisant le même id et en concaténant l'attribut "a" à la chaîne "World" pour créer l'attribut "b".
Créer le modèle à transformer :
Clic droit sur le projet - New - Other - Example EMF Model Creation Wizards - ABC Model
Double clic sur le modèle vide - clic droit sur Root - New chlid - ajouter et modifier dans la vue Properties :
- A: id=1, A=”Hello”
- A: id=-1, A=”World”
- C: id=1, C=”C'est quoi ce truc ?”
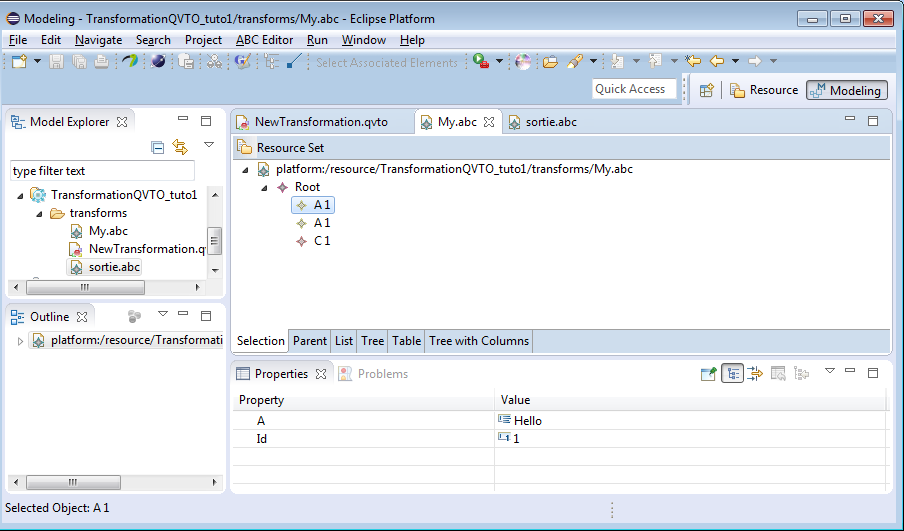
Pour exécuter la transformation :
Clic droit sur le fichier de transformation (.qvto) - Run As - Run Configuration - Operational QVT Interpreter - New_configuration - Run
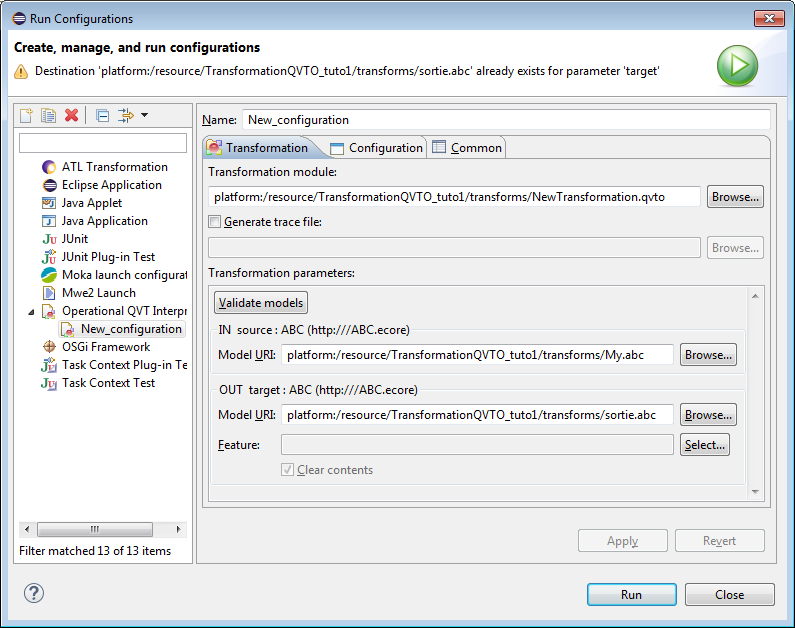
Le modèle transformé se trouve dans le fichier "sortie.abc" :
"La vraie valeur d'un homme réside, non dans ce qu'il a, mais dans ce qu'il est."
Oscar Wilde
Voir aussi :
http://urbanisation-si.wix.com/blog
http://urbanisme-si.wix.com/blog
http://urbanisation-si.wix.com/urbanisation-si
http://urbanisation-si.over-blog.com/
http://rhonamaxwel.over-blog.com/
http://urbanisation-des-si.blogspot.fr/
Le plugin ATL (ATLAS Transformation Language) pour Eclipse : les étapes pour réaliser une transformation (2/2)
Surcharge de module et exécution de la configuration de lancement
Tandis que les modules et requêtes ATL sont exécutés un par un, il est aussi possible d'exécuter des modules par dessus d'autres.
Le résultat final est une transformation contenant l'union de toutes les règles de transformations et helpers, quand il est possible pour un module de surcharger des règles et helpers du module inférieur.
Exemple :
Ce module est réutilisé et surchargé quand c'est nécessaire par le module :
http://ssel.vub.ac.be/viewcvs/viewcvs.py/UML2CaseStudies/uml2cs-transformations/UML2Profiles.atl?view=markup
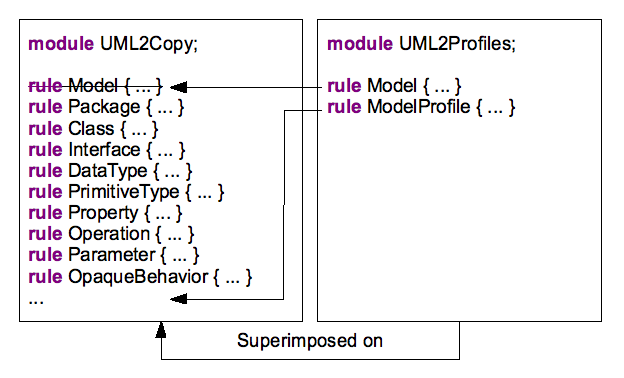
La transformation UML2Copy inclu la règle de transformation pour chaque instance de méta-classe qu'il doit copier.
Ce qui fait approximativement 200 règles pour la totalité du métamodèle
Chaque transformation spécifique doit copier toutes les méta-classse exceptées les quelques méta-classes qui sont redéfinies.
La transformation UML2Profiles applique un profil aux instances de "uml::Model" instance, tous les autres éléments sont juste copiés.
Pour terminer, le module UML2Profiles est exécuté par dessus le module UML2Copy.
Il redéfini la règle "Model" qui copie chaque instance de "uml::Model", avec une version vérifiant que le profil que nous voulons appliqué a déjà été appliqué.
Il introduit aussi une nouvelle règle "ModelProfile", qui vérifie que le profil que nous voulons appliquer n'a pas été appliqué et dans ce cas applique le profil.
Le résultat de la transformation contient toutes les règles figurant ci-dessus qui n'ont pas été barrées.
La surimpression se est faite à l'exécution : il n'y a pas de module représentant la surimpression des différents modules les uns par dessus les autres.
Il y a juste plusieurs modules chargés les uns au dessus des autres, surchargeant les règles existantes et en ajoutant des nouvelles.
La surimpression est configurée dans l'onglet "Advanced", "Run..." de la configuration de l'exécution.
Attention : quand on ajoute des modules en surimpression, dans l'onglet "Advanced", ils surchargent le module "main" spécifié dans l'onglet "ATL Main Configuration".
Exécution de la configuration
Une fois la configuration de la transformation correctement effectuée, elle peut être lancée autant de fois que l'on désire.
Il suffit juste d'aller dans la fenêtre Run, pour sélectionner la transformation et clique sur "Run".
"Tu dois devenir l'homme que tu es. Fais ce que toi seul peux faire. Deviens sans cesse celui que tu es, sois le maître et le sculpteur de toi-même."
Friedrich Nietzsche
Voir aussi :
http://urbanisation-si.wix.com/blog
http://urbanisme-si.wix.com/blog
http://urbanisation-si.wix.com/urbanisation-si
http://urbanisation-si.over-blog.com/
http://rhonamaxwel.over-blog.com/
http://urbanisation-des-si.blogspot.fr/
Le plugin ATL (ATLAS Transformation Language) pour Eclipse : les étapes pour réaliser une transformation (1/2)
Comment réaliser une transformation ATL avec l'IDE ATL d'Eclipse
Check liste des fichiers :
- métamodèle source (ecore)
- métamodèle cible (ecore)
- modèle source à transformer (xmi)
- fichier de transformation (atl)
Créer un projet ATL.
Les métamodèles source et cible peuvent être importés. La tache la plus ardue consistant bien sur à concevoir la transformation elle même.
Pour créer un projet ATL : New->ATL Project
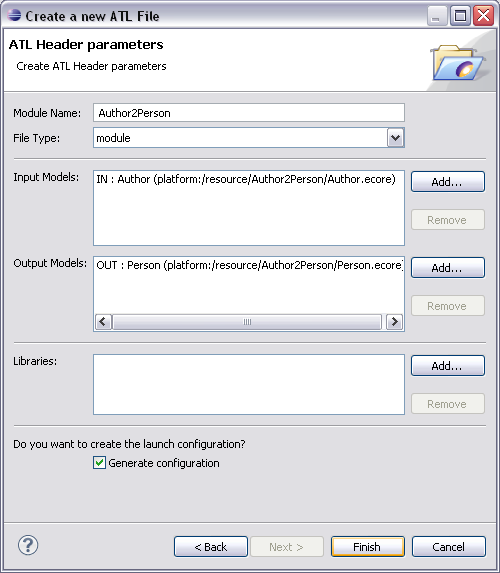
Une bonne pratique de nommage consiste à nommer le projet avec le nom du métamodèle source, puis "2" et pour finir le nom du métamodèle cible (par ex. Author2Person).
Pour avoir la "completion" des éléments de modèle, vous devez préciser en début de fichier ATL :
-
'-- @nsURI' : l'URI d'un métamodèle pour le charger à partir de l'EMF registry,
-
'-- @path' : le chemin d'un métamodèle, si vous voulez le charger dynamiquement à partir d'un fichier ecore.
Seuls les métamodèles EMF sont supportés.
Vous devez spécifier les chemins relatifs des fichiers dans le workspace.
Exemple du début d'une transformation "UML2AnyMM" :
-- @nsURI UML=http://www.eclipse.org/uml2/2.1.0/UML
module Class2Relational;
create OUT : AnyMM from IN : UML;
-- ...transformation helpers and rules
La "completion" est exécutée en appuyant sur Ctrl + espace, ou en tapant un espace si le contexte le permet.
Pour inclure la liste des librairies dans la completion :
'-- @lib' : le chemin relatif par rapport au workspace de la librairie.
Création du fichier ATL
Il existe 2 manière de créer un fichier ATL de transformation :
- l'assistant
- directement en créant le fichier source atl
L'assistant ATL
Il est appelé par New->ATL File dans le menu contextuel, vous pouvez spécifier :
- le nom du module
- le type (module, query ou librairie)
- les noms des variables métamodèles, modéles sources et cibles
- les librairies
- L'entête est généré avec ces informations.
Vous pouvez optionnellement généré les URIs ou chemins aux métamodèles pour activer la completion.
La checkbox "Generate configuration" génère la configuration de lancement en donnant les chemins des modèles.
Sinon vous créez le fichier atl "from scratch".
Compilation du fichier ATL
La compilation génère le fichier ASM.
La configuration de l'exécution
Elle donne toutes les information nécessaire à l'exécution de la transformation : les chemins des fichiers ATL, modèles, métamodèles et librairies).
L'onglet ATL Configuration permet de spécifier les chemins et URIs de la configuration de lancement. Les champs sont pré-remplis à partir du module ATL, mais vous pouvez en ajouter.
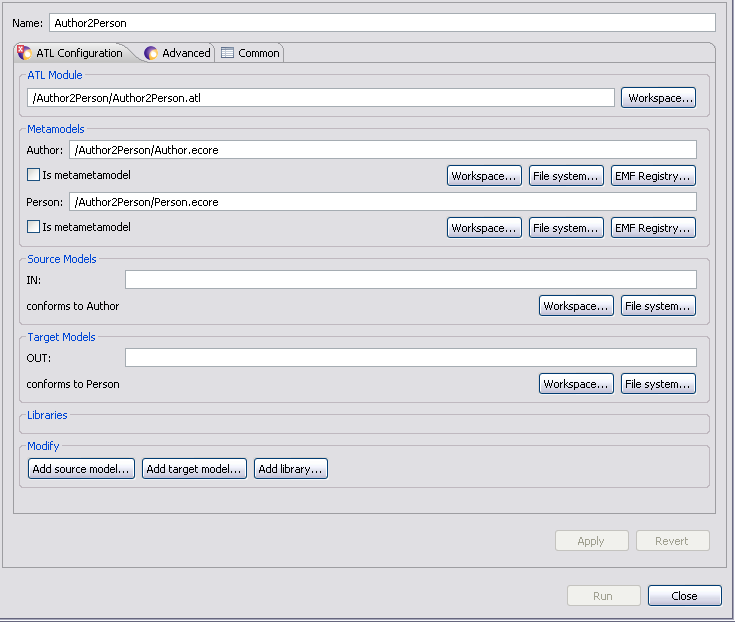
L'onglet Advanced permet de configurer :
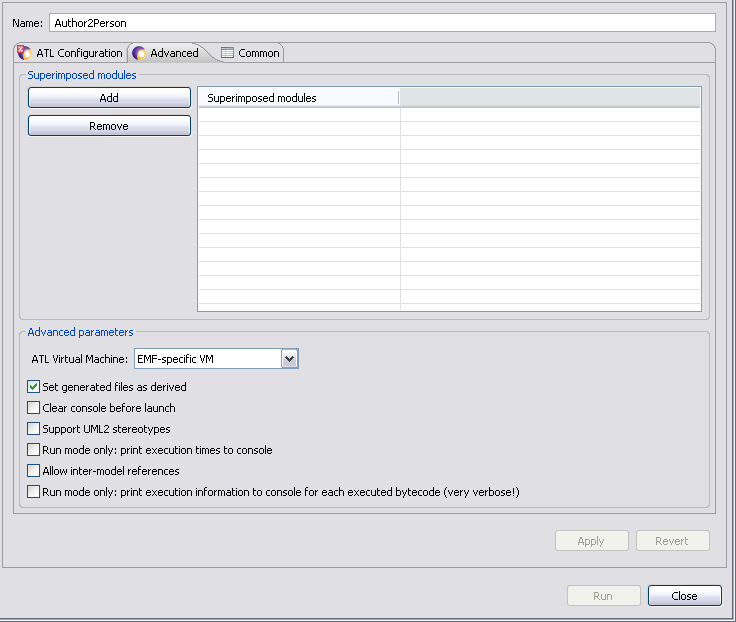
- des modules supplémentaires en surimposition avec les boutons Add/Remove.
- l'ATL Virtual Machine
- les paramètres de lancement
L'onglet Common offre aux développeurs la possibilité de configurer l'environnement d'exécution de la transformation.

- Le bouton Save as permet se sauvegarder la configuration de lancement dans un fichier par ex. Author2Person.launch.
- Display in favorites : la configuration apparaît dans les menus Run et/ou Debug.
- Console Encoding : le type d'encodage pour la console
- Vous pouvez définir les entrées et les sorties
- La dernière option permet d'exécuter la transformation en tache de fond.
"Se réunir est un début ; rester ensemble est un progrès ; travailler ensemble est la réussite."
Henry Ford
Voir aussi :
http://urbanisation-si.wix.com/blog
http://urbanisme-si.wix.com/blog
http://urbanisation-si.wix.com/urbanisation-si
http://urbanisation-si.over-blog.com/
http://rhonamaxwel.over-blog.com/
http://urbanisation-des-si.blogspot.fr/
Cours complet sur ATL (ATLAS Transformation Language) : pour terminer, une dernière chose à laquelle il faut prendre garde !

Dans l'article précédent :
nous avion abordé les mots clés ATL. Voyons à présent pour terminer, une dernière chose à laquelle il faut prendre garde !
Avec ATL, un élément du modèle d'entrée ne peut pas être mis en correspondance plus d'une fois.
Cette contrainte n'est pas vérifiée à la compilation et peut conduire à des résultats inattendus.
Un cas typique de correspondance multiple se produit lorsque dans le modèle d'entrée, on est en présence d'un héritage avec la super classe qui n'est pas abstraite :

La correspondance multiple apparaît ici en essayant respectivement de faire correspondre A et B dans les règles ( ruleA et ruleB).
Avec la pattern source : MM!A, la règle ruleA correspondra avec l'élément A ainsi qu'un élément B.
Comme ce dernier aura une correspondance dans ruleB, on aura le problème de la correspondance multiple.
Pour résoudre ce problème, on doit s'assurer que ruleA fait les correspondances avec seulement les éléments strictement A (et pas hérités).
Pour cela il faut filtrer dans le pattern source de la règle ruleA, le type d'élément mis en correspondance par la règle :
from
a : MM!A (
a.oclIsTypeOf(MM!A)
)
...
La fonction OCL oclIsTypeOf teste si dans le modèle d'entrée, les éléments sont des instances du métamodèle passé en paramètre.
Et voilà qui termine ce cours sur le langage ATL, nous passerons bientôt à une application dans le domaine du processus d'urbanisation du système d'information pour les projections (transformations) des cartographies.
"Je veux être fort, non pour dominer mon frère, mais pour vaincre mon plus grand ennemi - moi-même."
Chef Iakota Yellow Lark
Voir aussi :
http://urbanisation-si.wix.com/blog
http://urbanisme-si.wix.com/blog
http://urbanisation-si.wix.com/urbanisation-si
http://urbanisation-si.over-blog.com/
http://rhonamaxwel.over-blog.com/
http://urbanisation-des-si.blogspot.fr/
Cours complet sur ATL (ATLAS Transformation Language) : les mots clés ATL

Dans l'article précédent :
https://www.urbanisation-si.com/cours-complet-sur-atl-atlas-transformation-language-les-requetes-atl
nous avion abordé les requêtes ATL. Voyons à présent les mots clés ATL.
Voici la liste des mots réservés, ils se divisent en 3 catégories :
- les constantes : true, false;
- les types : Bag, Set, OrderedSet, Sequence, Tuple, Integer, Real, Boolean, String, TupleType, Map;
- le langage : not, and, or, xor, implies, module, create, from, uses, helper, def, context, rule, using, derived, to, mapsTo, distinct, foreach, in, do, if, then, else, endif, let, library, query, for, div, refining, entrypoint.
Attention la chaîne "main" ne peut pas être utilisée comme nom de variable, de règle ni d'attribut défini dans le contexte du module ATTL.
"Jour de vent, jour de pluie, il fait gris, mais dans ton cœur, il y a la vie, ce soleil qui jaillit, offre-le d'un sourire à autrui."
Jo Coeijmans
Voir aussi :
http://urbanisation-si.wix.com/blog
http://urbanisme-si.wix.com/blog
http://urbanisation-si.wix.com/urbanisation-si
http://urbanisation-si.over-blog.com/
http://rhonamaxwel.over-blog.com/
http://urbanisation-des-si.blogspot.fr/
Cours complet sur ATL (ATLAS Transformation Language) : les requêtes ATL

Dans l'article précédent :
https://www.urbanisation-si.com/cours-complet-sur-atl-atlas-transformation-language-le-mode-affine-atl
nous avion abordé le mode “affiné” ATL. Voyons à présent les requêtes ATL.
Parallèlement aux “modules units”, ATL permet de définir des requêtes sur le modèle.
Une requête accepte plusieurs modèles sources et produit une unique valeur de retour de n’importe quell type primitive.
Elle est composée d’un élément de requête unique avec plusieurs helpers et attributs définis dans le context soit du module ATL soit dans n’importe quell élément de module défini dans la requête du modèle source.
Syntaxe :
Pas de contrainte sur le nom, il est toutefois conseillé de prendre le même nom que celui du fichier dans lequel la requête est définie.
Le corps de la requête est une expression OCL de n’importe quels types primitifs : string, boolean, integer or real.
Les helpers et les attributs definis dans le fichier de la requête (de manière similaire que ceux definis dans les librairies ATL importées) peuvent être appelés dans la portée du corps de l’élément de requête.
Dans un IDE (Integrated Development Environment), il peut être intéressant d’écrire les résultats de l’exécution d’une requête dans un fichier.
Exemple :
MMPerson!Person.allInstances()->size().toString().writeTo('result.txt');
Cette requête est executée sur le modèle MMPerson contenant plusieurs objets Person.
La requête commence par récupérer l’ensemble des objets de type Person ainsi que la taille de la collection.
Puis on écrit cette valeur dans un fichier (l’integer est casté en string, operation toString(), avant d’écrire dans le fichier "result.txt") .
A noter que la requête renvoie aussi la string.
"Le vrai bonheur est dans le calme de l'esprit et du coeur."
Charles Nodier
Voir aussi :
http://urbanisation-si.wix.com/blog
http://urbanisme-si.wix.com/blog
http://urbanisation-si.wix.com/urbanisation-si
http://urbanisation-si.over-blog.com/
http://rhonamaxwel.over-blog.com/
http://urbanisation-des-si.blogspot.fr/