
Vous cherchez un outil pour gérer le mapping entre les objets métier et une base de données relationnelle, générer les scripts SQL et produire du code à partir de vos modèles ? Obeo ISD S.1 Ep.5
L’atelier Entity d’Obeo Information System Designer (ISD) va vous permettre de modéliser vos entités métier. Avec l’autre atelier Database, vous pourrez modéliser votre base de données relationnelle, générer des scripts SQL, rétromodéliser des bases existantes, gérer des Modèles Logiques de Données (MLD) et des Modèles Physiques de Données (MPD).
Et grâce aux deux, vous serez assuré de la synchronisation efficiente entre vos objets métier et votre base SQL. ISD a plus d’un tour dans son sac avec ses nombreux frameworks qui vous permettront de générer une partie du code de votre application, à partir de vos modèles de conception et d'analyse.
Vous créez votre modèle d'entités persistantes, puis, à partir de ce modèle, ISD va générer le MLD ;
vous lui indiquez votre moteur SQL, ISD génère le MPD, puis les scripts correspondants
et enfin vous les exécutez directement dans ISD.
Résumé des épisodes précédents
Nos 4 précédents articles détaillent toutes les étapes, depuis l'analyse du besoin
jusqu'à la conception d'une architecture micro-services.
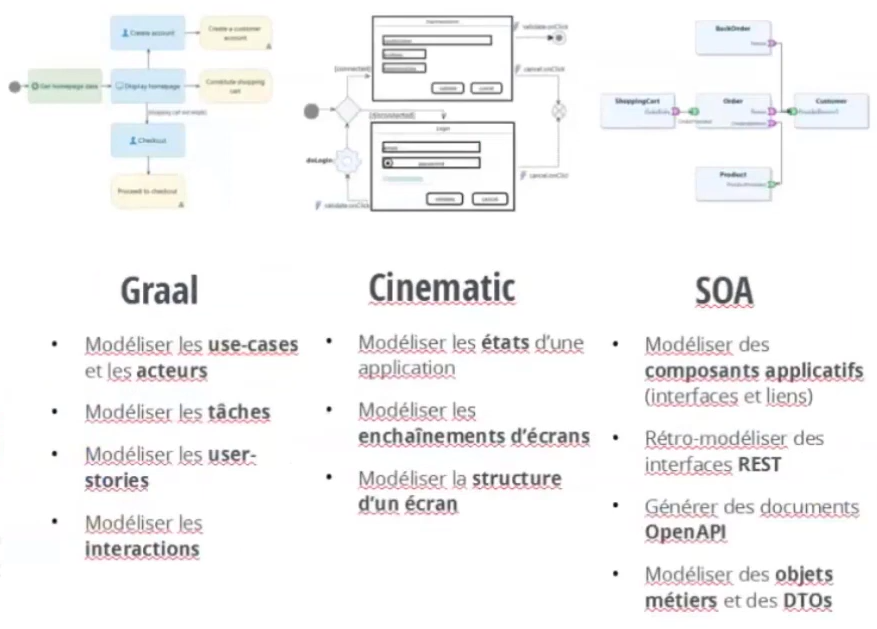
Les différents modeleurs et leurs fonctions
- Épisode 1 : présentation des fonctionnalités et installation d’ISD.
A lire > Alimenter le référentiel d’Architecture d’Entreprise pour la couche Application de TOGAF avec l’outil Information System Designer (ISD) d’Obeo - Modélisation de l’analyse des besoins S.1 Ep.1
- Épisode 2 : l’atelier Graal de modélisation des acteurs, des use cases, des tâches, des enchaînements d’actions, des diagrammes de séquence et de machine à états.
A lire > Méthode Graal, le NoUML d’Obeo, parfaite fusion entre un UML phagocyté et un BPMN édulcoré. S.1 Ep.2
- Épisode 3 : l'atelier Graal de gestion des User Stories, l’atelier Requirement pour gérer le référentiel des exigences et leur traçabilité, l’atelier Cinematic pour la modélisation des maquettes et la cinématique des écrans
A lire > Comment assurer la traçabilité des exigences avec les user stories, les use cases, les processus métier, la cinématique et les maquettes d'écrans ? Une solution dans notre test Obeo ISD S.1 Ep.3
- Épisode 4 : l’atelier SOA pour modéliser des API (REST ou SOAP) avec leurs composants applicatifs micro-services ou Web Services, leurs interfaces de communications, leurs relations, leurs opérations avec les données échangées (DTO), pour générer des documents OpenAPI et pour rétromodéliser des interfaces REST.
A lire > Quelle solution pour concevoir la modélisation d’une architecture micro-services, l’intégrer dans une architecture d’entreprise et permettre une collaboration avec l’ensemble des acteurs projet ? Obeo ISD S.1 Ep.4
Créez des entités persistantes
Jouez la partition
En préambule, quelques mises au point sur la terminologie d’ISD :
- les Domain classes représentent les entités métier définies par les experts métier et modélisées par les business analysts avec la méthode Graal,
- les Entities correspondent aux classes persistantes gérées par un ORM (Object Relational Mapping) offrant la dualité objet/relationnel SQL.
- les DTO, créés à partir des attributs des Entities, représentent les données échangées entre les services dans une SOA.
Un diagramme Entities Namespaces Hierarchy est créé dans le conteneur de l'Entity Model.
Le NoUML de modélisation d’Obeo ISD est en fait un DSL (Domain-Specific Language), dans lequel le package UML est renommé namespace, avec un nombre restreint de relations.
De manière similaire à la vue Domain Classes Namespaces Hierarchy du modèle Graal ou celle DTO Namespaces Hierarchy, il faut créer au préalable au moins un namespace :
- File ou clic droit sur votre Modeling Project > New > Other > IS Designer > Entity Model
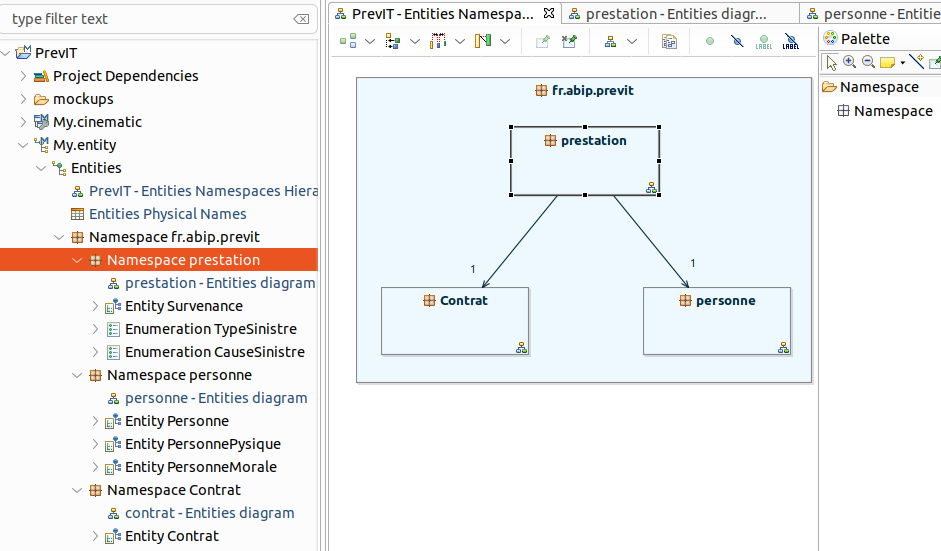
Les pictos en bas à droite des namespaces indiquent qu’en double-cliquant,
on peut accéder au diagramme d’entités.
Ce diagramme permet de modéliser les classes, qu'elles soient internes ou externes au namespace. S’il existe des relations entre des classes appartenant à des namespaces différents, alors ISD génère automatiquement les relations dans le diagramme des namespaces.
- Une fois le namespace créé, le sélectionner via le menu contextuel > New Representation > Entities Diagram
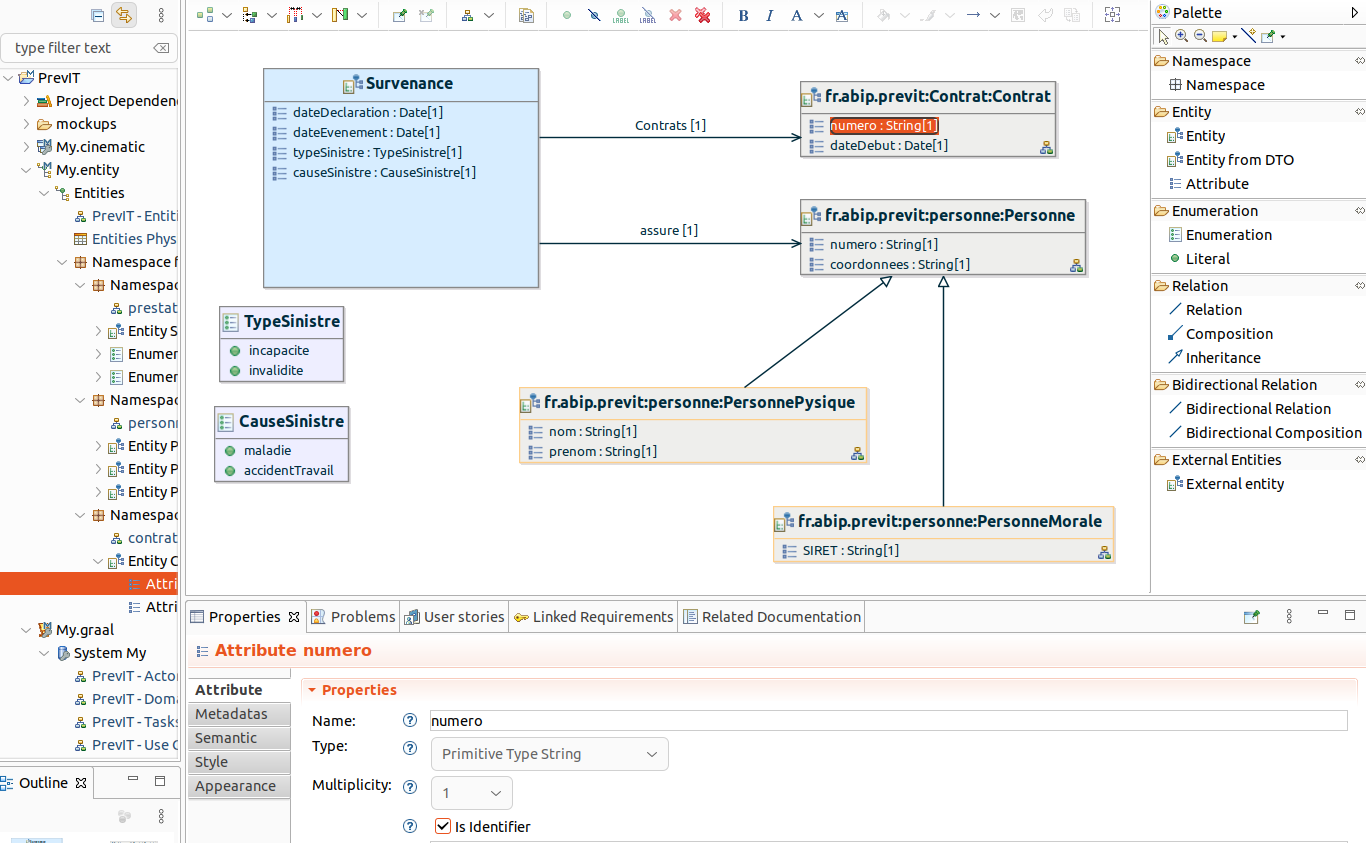
On retrouve exactement le même type de diagramme que les Domain Classes ou les DTO,
sauf que cette fois-ci les classes sont stéréotypées Entity.
ISD supporte les visions entités persistantes vers DTO ou bien l’inverse. Dans le diagramme d’entités, on a Entity from DTO et dans celui des DTO on a DTO from Entity.
Ce choix est judicieux, car il permet une souplesse de conception bidirectionnelle qui se présente souvent dans un contexte agile, où l’on doit ajouter des données, soit dans les entités persistantes et les répercuter dans les DTO, soit l’inverse.
Un bémol à la clé
Par contre, il est impossible de récupérer les classes métier (Domain Classes) modélisées dans le modèle Graal de l’analyse. Dommage, car en pratique la plupart des entités persistantes proviennent des classes participantes ou métier !
Il nous a été impossible de créer une relation entre une entité et une énumération, on a donc créé à la place un attribut du type énumération.
En choisissant de générer toutes les entités à partir de nos DTO, nous avons constaté que :
Les liens d’héritage ne sont pas repris, bien que l’on ait sélectionné toutes les relations à importer, mais les attributs sont dupliqués dans l’entité héritière.
Les énumérations n'apparaissent pas, bien qu’un attribut d’une entité soit de type énumération.
Ajoutez à vos entités persistantes
les informations spécifiques à la base SQL
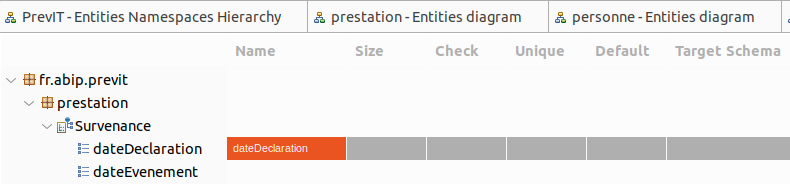
Préparez la correspondance de vos entités persistantes
avec les noms des colonnes, type, taille, unicité, index...
La vue Entities Physical Names est un tableau qui reprend en lignes toutes les entités définies précédemment et permet dans les colonnes d’ajouter les informations spécifiques à la base de données, comme le nom physique d'une colonne, la taille, les contraintes de vérification, les contraintes d’unicité, la valeur par défaut, le choix des schémas pour les tables intermédiaires.
Par exemple, sur un attribut indexé, on peut mettre dans la colonne Unique ASC pour ascendant ou DESC pour descendant.
Pour une contrainte d’unicité portant sur plusieurs champs, on doit adopter un langage spécial (sur l’entité et non plus sur l’attribut, dans la colonne Unique, on doit saisir champ1:ASC,champ2,champ3,etc. avec éventuellement un | pour séparer des index différents).
Il est impossible de saisir dans les colonnes Name, etc. les attributs des entités créées à partir des DTO. Par contre, si nous ajoutons une nouvelle entité avec des attributs, elle se retrouve bien dans le tableau et nous pouvons bien saisir dans les colonnes des attributs.
Générez automatiquement le modèle logique
de données (MLD) à partir du modèle Entités
Construisez l'échafaudage de votre architecture :
le système de génération Scaffolding d'ISD
- Menu File ou clic droit sur votre Modeling Project > New > Other > IS Designer > Database Model > Laissez toutes les valeurs par défaut (Data Base, Logical Types et UTF-8)
Un diagramme de schéma logique de base de données, encore appelé MLD (Modèle Logique de Données) pour les nostalgiques de la méthode Merise, est créé, dans lequel on peut modéliser des tables, vues, colonnes, clés primaires et étrangères, des séquences, des index…
Le système Scaffolding d’ISD permet de transformer des modèles, suivant les concepts MDA (Model Driven Architecture) de l’OMG.
A lire > nos articles dans la catégorie : Ingénierie Dirigée par les Modèles (IDM)
Après avoir modélisé vos entités persistantes et défini les propriétés physiques (nom de table, taille…) avec l’atelier Entities, vous pouvez générer vos tables dans le diagramme de schéma pour une base de données relationnelle (MLD), pour l’instant vide, grâce au système Scaffolding Entity to Logical database d’ISD.
- Sélectionnez à la fois, en maintenant la touche Ctrl enfoncée, le conteneur (Entities) sous la vue (.entity) et le conteneur Data Base sous la vue (.database) > clic droit > IS Designer > Scaffolding > Entity to Logical database (remarque : on dispose aussi de l’option inverse) > les schémas générés à partir des namespaces du modèle Entities apparaissent :
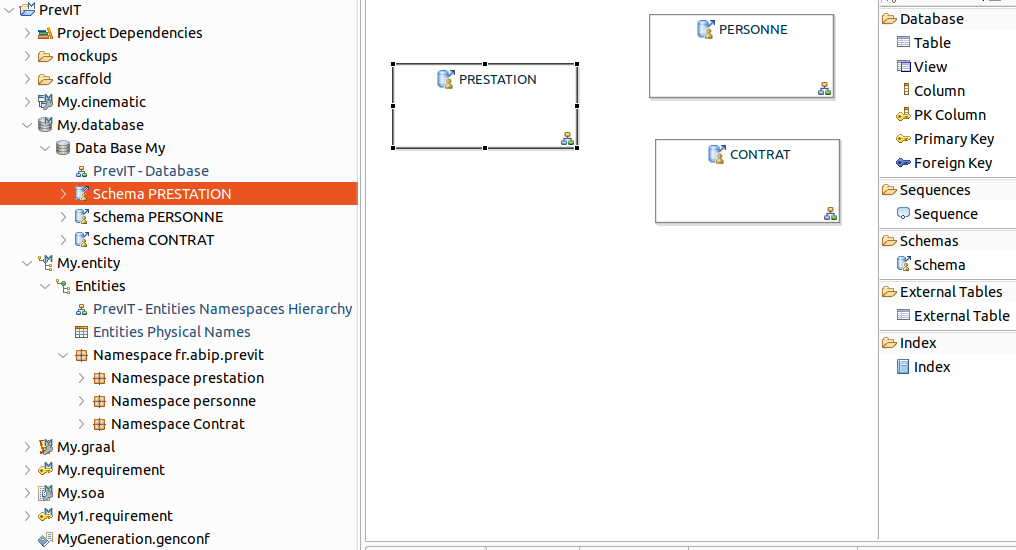
Dans le schéma logique de base PrevIT, 3 sous-namespaces sont créés correspondant
aux 3 contextes métier (Domain Driven Design) Prestation, Personne et Contrat.
Pour avoir le détail, double-cliquez sur un schéma :
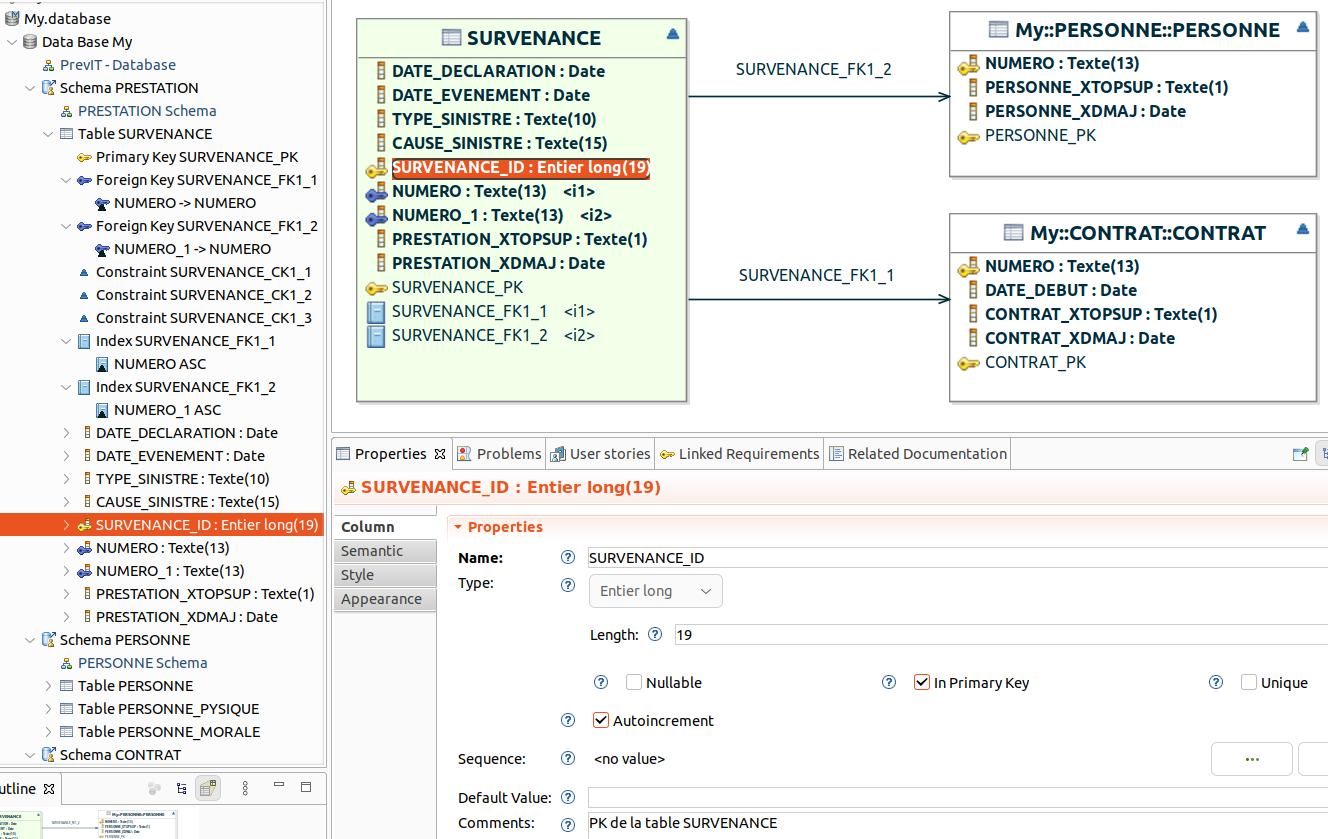
On retrouve les concepts des bases de données relationnelles, avec les clés primaires, étrangères,
les contraintes de check (triangle sur les tables), etc. Vous pouvez réorganiser les colonnes.
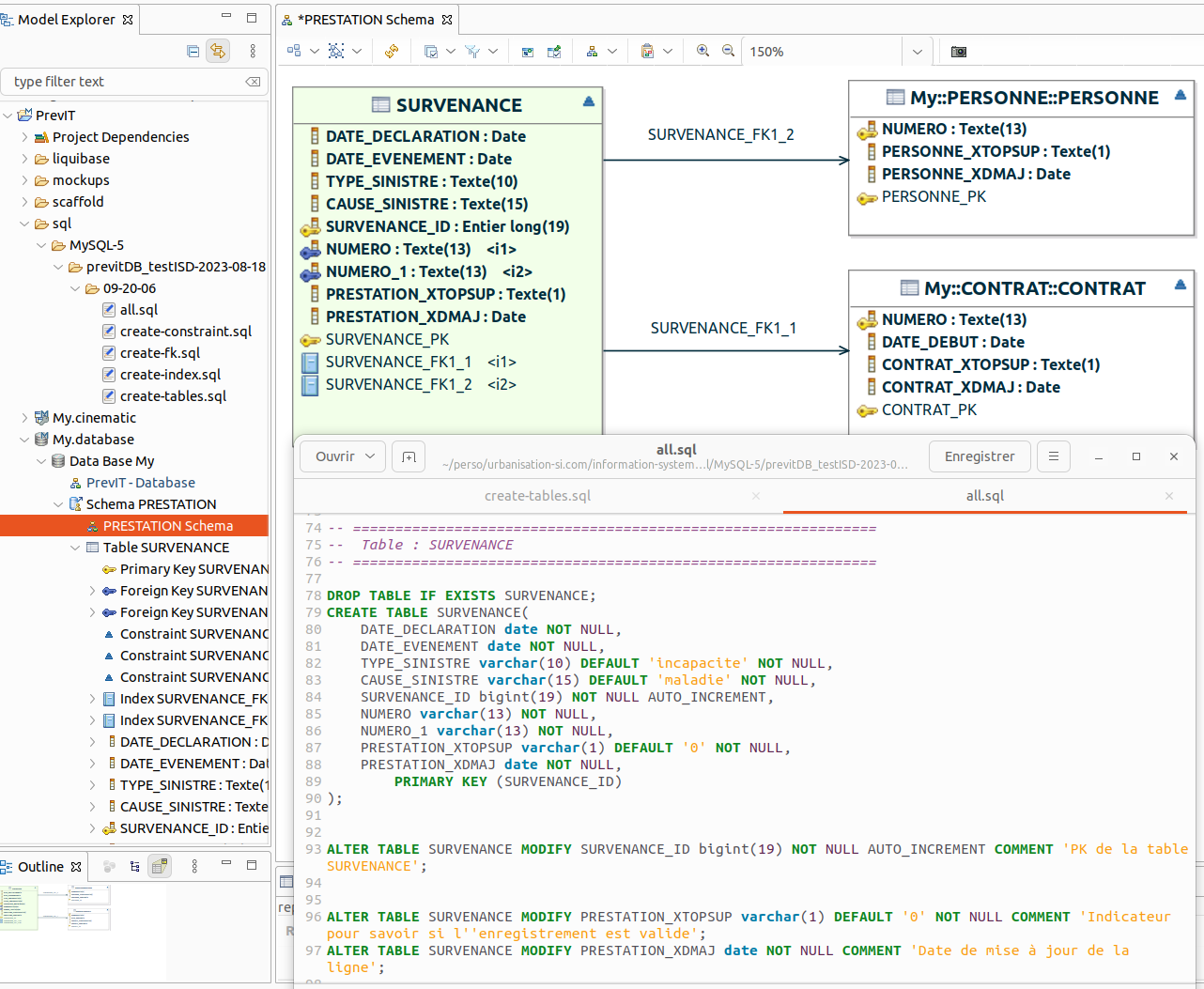
Le MLD est bien créé à partir du modèle entities. Des colonnes de pistes d'audit ont été ajoutées par le générateur d'ISD comme PRESTATION_XTOPSUP (Indicateur pour savoir si l'enregistrement est valide) et PRESTATION_XDMAJ (Date de mise à jour de la ligne). La table SURVENANCE est en relation avec la table PERSONNE dans le schéma PERSONNE et avec la table CONTRAT dans le schéma CONTRAT.
Pour la génération de l'héritage, l'échafaudage est bancal
Les bases de données relationnelles n'ont pas de moyen simple de mapper les hiérarchies de classes sur les tables de base de données. Pour résoudre ce problème, plusieurs stratégies existent :
- MappedSuperclass - les classes parentes ne peuvent pas être des entités,
- Table unique – Les entités de différentes classes ayant un ancêtre commun sont placées dans une seule table,
- Table jointe - Chaque classe a sa table, et interroger une entité de sous-classe nécessite de joindre les tables,
- Table par classe - Toutes les propriétés d'une classe sont dans sa table, donc aucune jointure n'est requise.
La stratégie d’héritage choisie est celle d’une table par classe. Cette stratégie mappe donc chaque entité à sa table, qui contient toutes les propriétés de l'entité, y compris celles héritées.
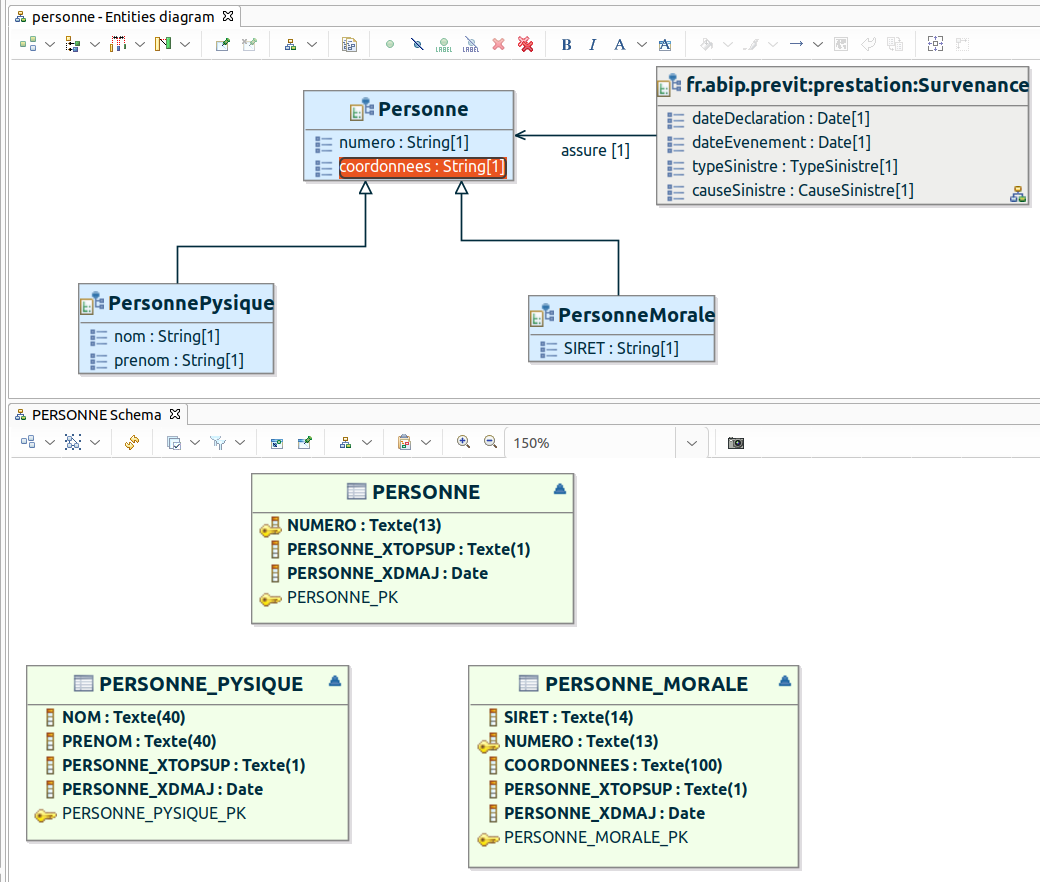
3 tables ont bien été générées. Seule la table PERSONNE_MORALE est correcte compte tenu des relations d'héritage modélisées dans le diagramme Entities. En effet, les colonnes NUMERO et COORDONNES héritées sont bien présentes, en plus du SIRET spécifique à la table.
Dans le modèle des entités persistantes (partie supérieure de l'illustration), PersonnePhysique et PersonneMorale héritent des attributs numero et coodonnees de Personne. Dans le schéma généré (partie inférieure de l'illustration), on constate que coordonnees n’apparaît pas dans la table PERSONNE, ni dans la table PERSONNE_PHYSIQUE, alors que bizarrement elle est bien présente dans la table PERSONNE_MORALE. Auparavant, nous avons bien pris soin de spécifier la colonne coordonnees dans le tableau Entities Physical Names du modèle Entities, avec une taille de 100.
Autre bizarrerie, la colonne NUMERO de la table PERSONNE et PERSONNE_MORALE apparait bien, conformément à la stratégie d’implémentation de l’héritage, mais pas dans la table PERSONNE_PHYSIQUE !
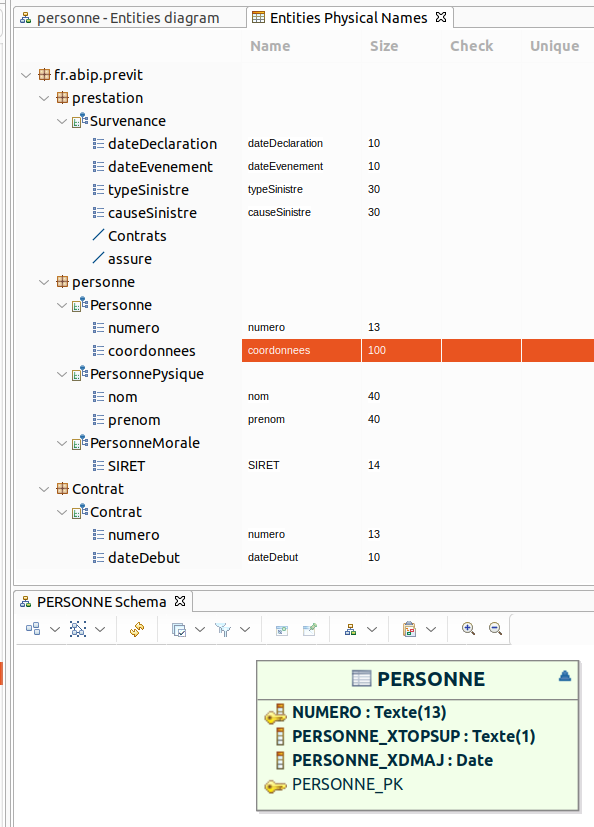
Dans le tableau Entities Physical Names du modèle Entities, permettant de configurer le MLD qui va être généré, à l'attribut coordonnees de la classe Personne, on a fait correspondre la colonne du même nom avec une taille 100, qui pourtant n'apparaît pas dans la table PERSONNE.
Gestion des modifications
Si l’on fait d’autres modifications, et que l’on refait l’opération de scaffolding, ISD propose de créer une nouvelle version ou d’écraser l’ancienne.
- Par exemple, on modifie le nom du schéma, il suffit de sélectionner le conteneur .scaffold sous le répertoire scaffold > IS Designer > Scaffold > Entity to Logical database. Un nouveau schéma EB apparaît, on crée un nouveau diagramme (New representation > nouveau nom Schema) et l’on retrouve un nouveau MLD avec en préfixe le nom du nouveau schéma.
Générez automatiquement
le Modèle Physique de Données (MPD)
Prenons MySQL comme RDBMS de test.
Créez tout d’abord un schéma (database) vide dans MySQL, par exemple previtDB_testISD, puis dans ISD, menu File > Import > Database > Import Database > saisissez les informations de connexion à votre database MySQL :
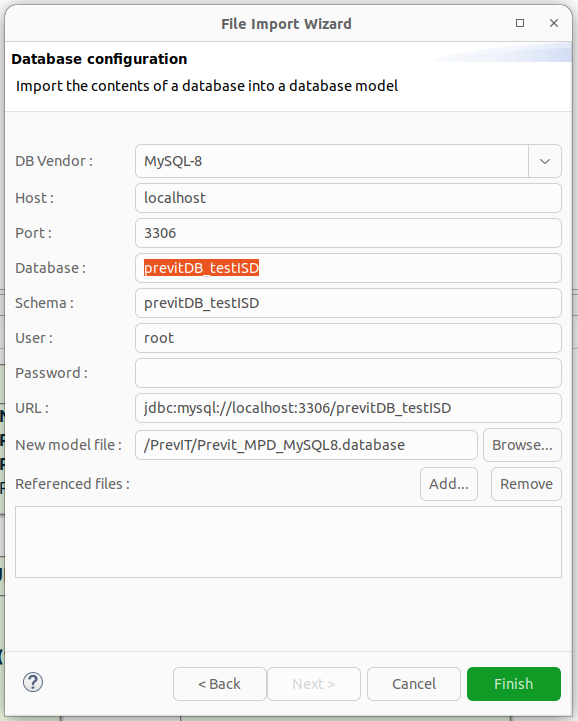
Remarque importante : dans le champ New model file, vous devez saisir
un modèle de database inexistant, par exemple Previt_MPD_MySQL8.database
Générez le MPD avec le système de scaffolding d’ISD, en procédant de la même manière que pour générer le MLD à partir des entités :
- Sélectionnez simultanément votre MLD (Data Base My) et votre MPD vide, que vous venez de créer (Data Base previtDB_testISD)
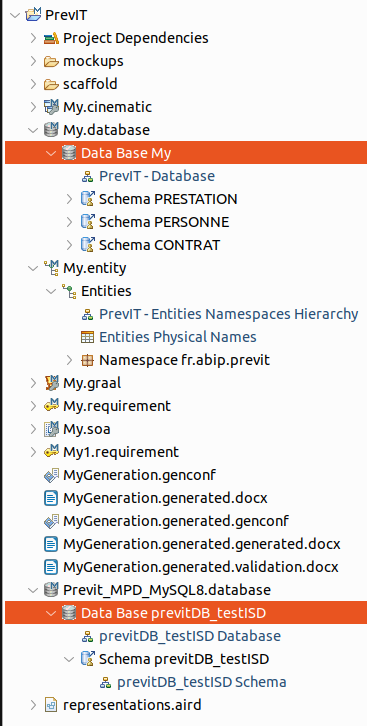
A partir de votre MLD généré précédemment, le système Scaffolding d'ISD va générer
votre MPD nouvellement créé et qui pointe sur votre database vide MySQL.
- Menu contextuel sur le MPD > IS Designer > Scaffolding > Logical database to Physical database (on dispose aussi du reverse engineering Physical database to Logical database).
Le MPD est créé avec les 4 schémas MySQL correspondants aux 4 namespaces : le namespace previtDB_testISD correspondant au namespace de base et PRESTATION, PERSONNE et CONTRAT correspondant aux 3 sous-namespaces.
Générez les scripts SQL
Sur le conteneur Previt_MPD_MySQL8.database, on peut générer les scripts SQL :
- Menu contextuel > IS designer > Generate SQL Scripts, un répertoire sql est créé, comportant 4 scripts pour les créations de contraintes, de clés étrangères, d'index et de tables et un script complet rassemblant les 4 précédents.
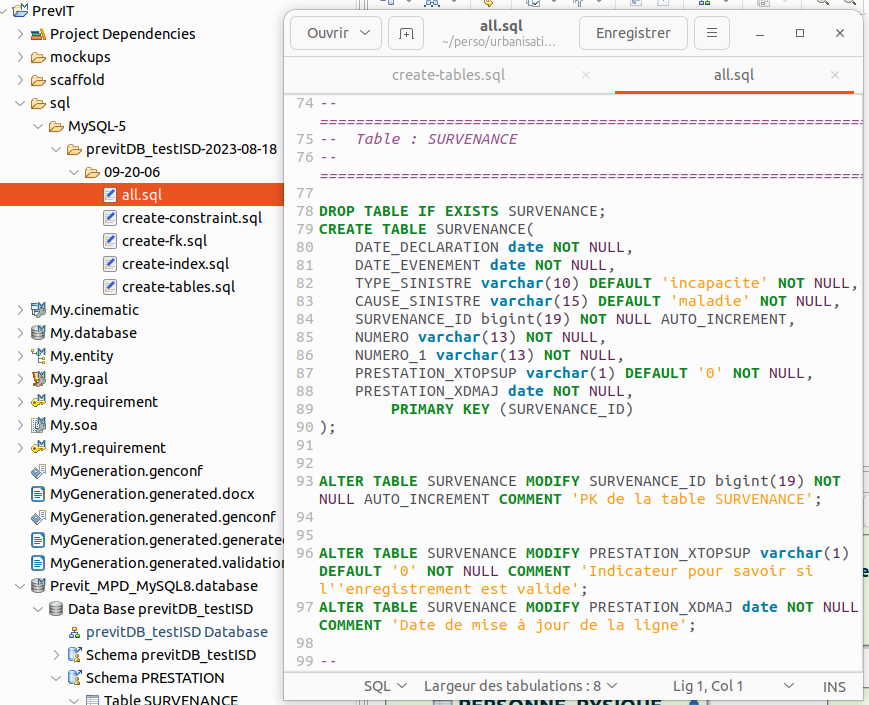
On trouve les scripts SQL correspondant au MPD. Ces scripts SQL devront être exécutés manuellement.
Exécutez les scripts SQL directement dans la base
Le générateur Liquibase permet d’exécuter directement des scripts dans la base.
- Sur le conteneur MySQLtest2.database, on peut générer les scripts SQL :
Menu contextuel > IS designer > Generate Liquibase changelog
Un répertoire liquibase est créé, contenant un fichier de propriété, permettant de configurer les accès à la base de données, et un fichier XML contenant les propriétés sous forme de balises avec les instructions SQL qui seront envoyées à la base par liquibase.
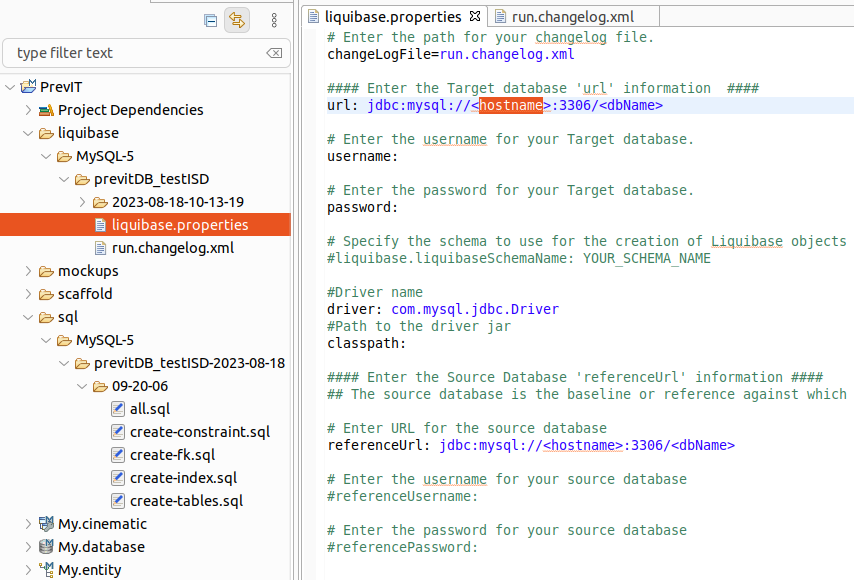
Vous devez valoriser les variables du fichier liquidbase.properties (<hostname>…).
Au lieu de configurer le fichier de propriétés liquibase, il existe une manière plus facile en utilisant le fichier run.changelog.xml :
- menu contextuel sur le fichier run.changelog.xml > Liquibase > Apply changing > saisir l’URL (jdbc:mysql://localhost:3306/previtDB_testISD), le user et le password
A ce moment, liquibase va se connecter directement et exécuter le fichier XML.
Nous avons rencontré 2 types d’exceptions :
- la 1re concernait l’impossibilité dans le fichier run.changelog.xml, de prendre en charge la propriété : column autoIncrement="true". Nous avons remplacé partout true par false,
- la 2e disait que les schémas (database) CONTRAT, PERSONNE et PRESTATION n’existaient pas. Effectivement, comme nous avions créé 3 sous-namespaces dans le namespace de base, 3 schémas ont été créés dans ISD, il faut donc naturellement les créer dans MySQL (dans notre cas MariaDB, compatible MySQL).
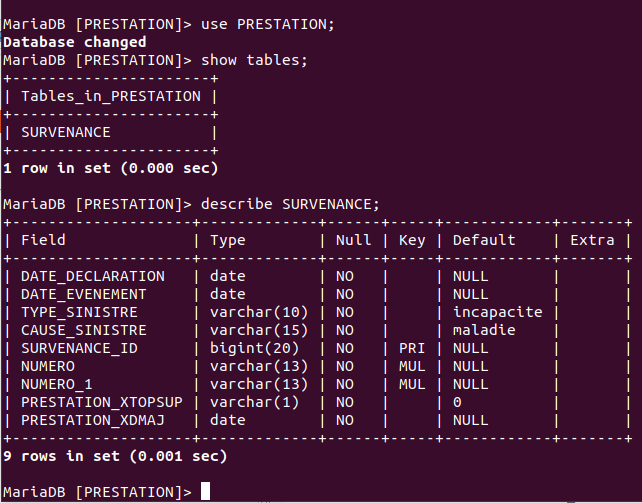
Extrait de la vérification de l'exécution des scripts SQL dans la console de la base de données.
Vous pouvez analyser les changements apportés grâce à l’historique :
- Menu contextuel sur le conteneur MLD .database > Compare With > Local History
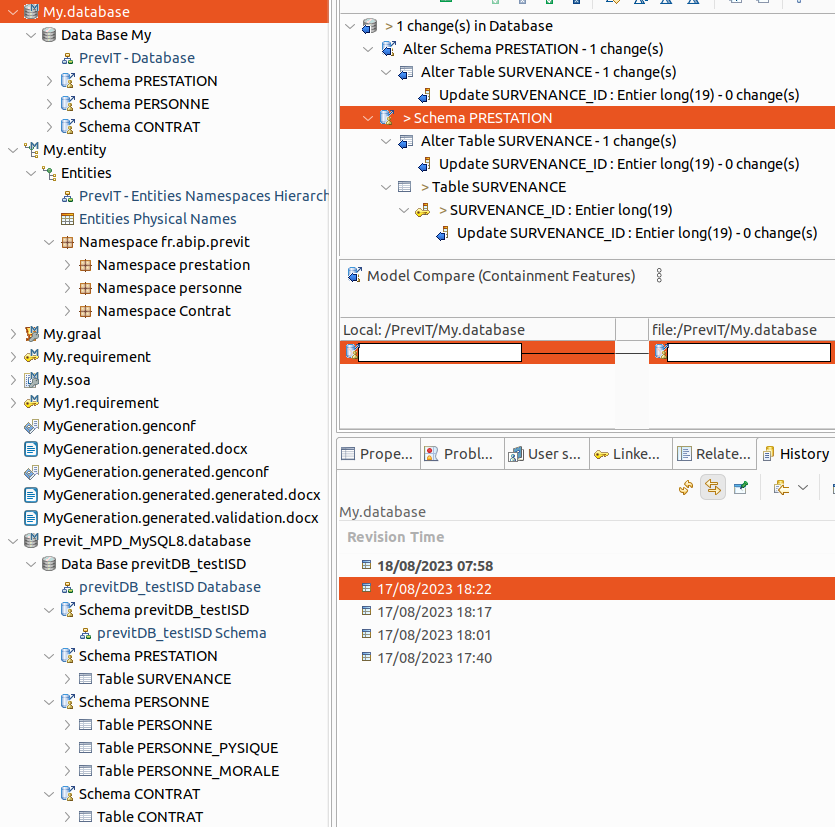
Exemple d'utilisation de l'historique.
Rétromodélisation et intégration de l’existant

Capacité à se connecter au format OpenAPI, en import, mais aussi en export.
Liquibase permet de piloter les schémas d’une base de données
à partir d’un diagramme de classes de conception.
On peut exporter et générer des previews avec SwaggerUI. Voir les copies d’écran dans la documentation github.
Génération documentaire
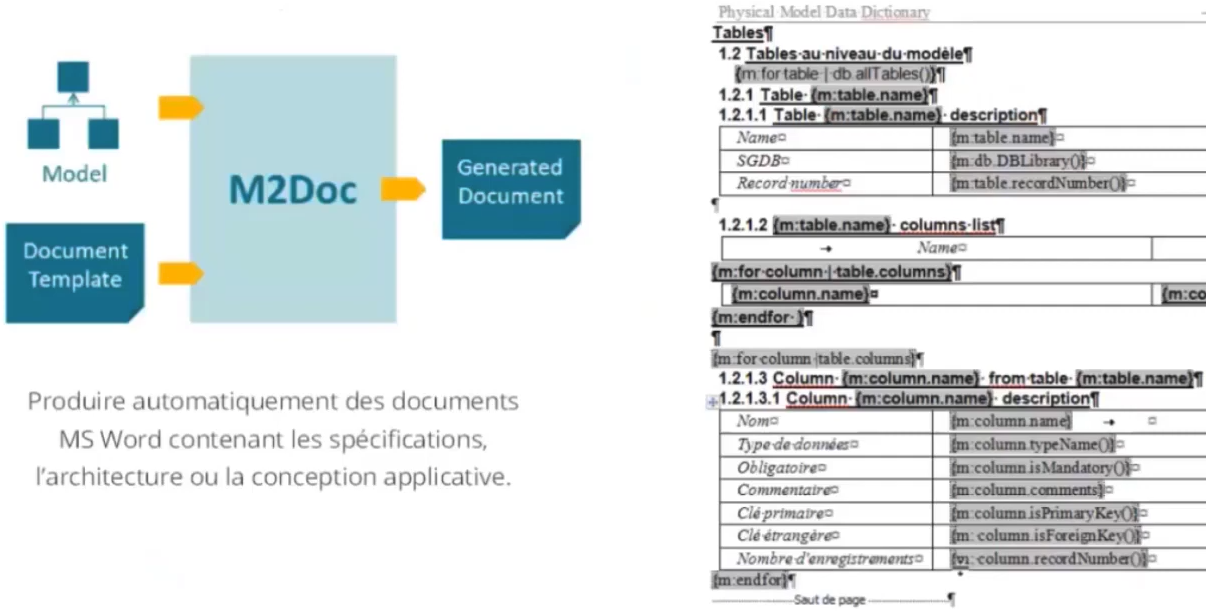
M2Doc généré à partir d’un template variabilisé.
La valorisation se fait à partir des modèles créés dans ISD.
Le Graal de l’agilité : générer une application directement à partir des modèles et de manière bidirectionnelle

La génération de code est basée sur des templates. Voir un exemple de template Acceleo en annexe 1.
Avec ISD, le processus est simple : vous modélisez la conception, puis vous générez le code. Vous pouvez modifier le code que vous avez généré. Si vous modifiez la conception, votre code est conservé. Le concept de génération se fait en round-trip, c’est-à-dire que l’on peut intégrer les parties de codes réalisées par les concepteurs/développeurs.
Plus on remonte dans les couches de l'architecture, moins on pourra générer de code.
Ainsi, 80 % du code backend peuvent être générés. Par exemple, 100 % des entités seront générés et plus de 50 % pour le métier. La couche de persistance est entièrement créée par le générateur d’ISD, auquel Obeo a ajouté les tests unitaires, ce qui n’est pas le cas des ORM classiques.
Les 20 % restants concernent les écrans laissés aux spécialistes frontend et certaines parties métier, comme des règles métier ou les machines à états, car les développeurs séniors produiront un code plus efficient.
Toute la partie architecture est sécurisée, car elle est mise en place par le générateur.
ISD utilise plusieurs générateurs de code open source, comme Acceleo de la fondation Eclipse et PACMAN du Ministère des Armées de la France.
A lire > Les générateurs de codes Acceleo et PACMAN
La mise en œuvre de ces outils passera souvent par les services payants d'Obeo.
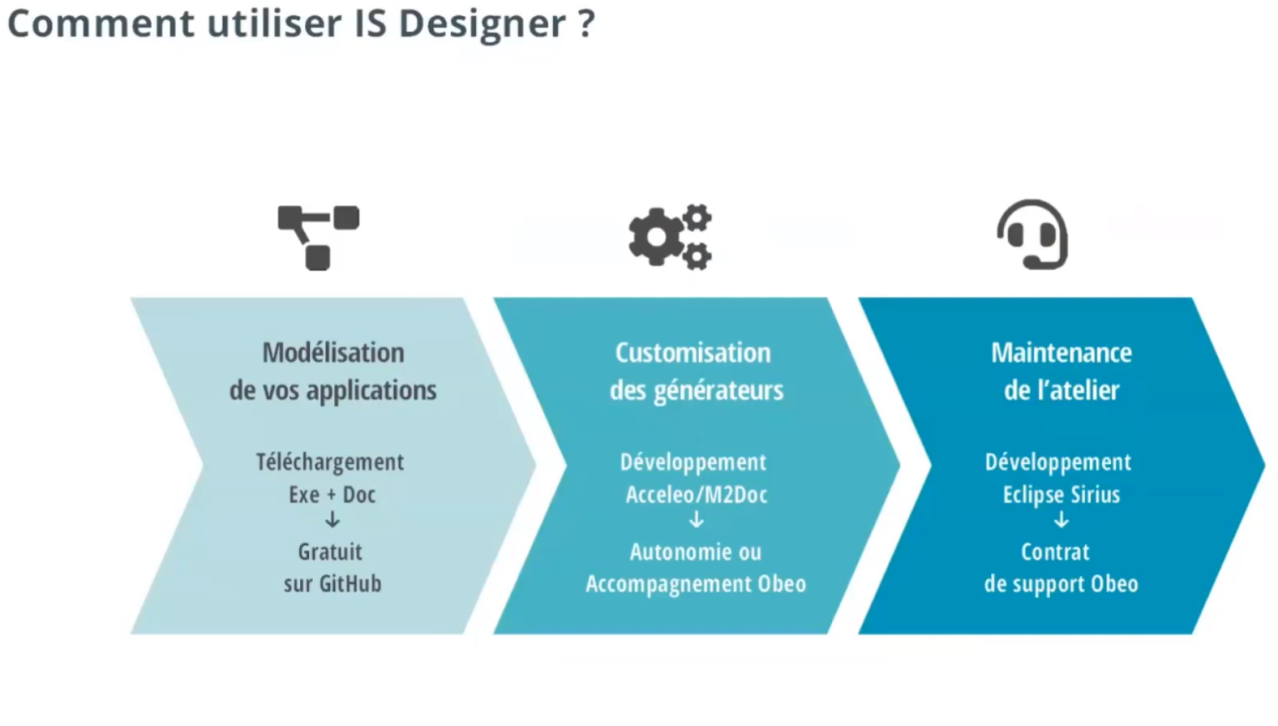
Ne vous enthousiasmez pas trop vite, à moins d'avoir une connaissance approfondie des techniques de génération de code, l'utilisation efficiente de ces générateurs demandera l'aide d'experts.
Obeo vous propose toute une série de modeleurs gratuits pour la partie analyse et modélisation de votre application. Si la fourniture des générateurs de code l’est aussi, leur utilisation reste extrêmement complexe. Obeo peut alors vous proposer, moyennant finance, un accompagnement. Il en va de même pour la maintenance et le support d’ISD.
Travail collaboratif avec l’extension payante
Obeo Designer Team
Pour le travail collaboratif, là encore il faudra mettre la main au porte-monnaie. En effet Obeo Designer Team est une extension commerciale, non-open source, permettant de partager des modèles, à la manière Google Doc.
Conclusion

Le couple de frameworks Sirius & Acceleo permet à ISD de produire
le code correspondant aux modèles de conception.
Les éloges
ISD d’Obeo est indubitablement un outil basé sur la collaboration de toutes les parties prenantes d’un projet de réalisation d’une application.
Avec ses différents ateliers, ISD vous aidera dans l’élaboration de la phase d’analyse (atelier Graal). Le cadre apporté par la méthode Graal vous facilitera la formalisation des use cases, avec les enchaînements d’actions, l’intégration des user stories, le modèle métier de vos données et la mise en place du référentiel d’exigences. L’atelier Cinematic vous permettra de concrétiser les scénarios des use cases, en maquettant les écrans et en planifiant la navigation. L’atelier SOA vous permettra d’élaborer votre architecture distribuée à base de micro-services ou de services web. Avec l’atelier Entity, vous définirez, parmi vos classes métier et DTO, lesquels doivent être persistants.
Les déceptions
Après avoir fait du NoUML, il est étrange qu’ISD ne supporte pas le NoSQL, comme (MongoDB, Cassandra…).
Nous regrettons aussi que le modeleur SOA Designer ne couvre que le type d’exposition REST. SOAP n’est disponible dans le studio qu’à titre indicatif, aucun outillage spécifique n’ayant été développé pour l’exploiter. Que vous utilisiez l'approche top-down, concevoir le contrat WSDL (Web Services Description Language), puis, à partir de celui-ci, faire générer le code ou l'approche inverse bottom-up, il vous faudra vous tourner vers les frameworks open source conventionnels du marché en fonction de votre langage de programmation. Autre solution, demander à Obeo, d'implémenter cette fonctionnalité, qui sera alors payante.
Open source oui, closed pour le reste.
A notre avis, l’atelier Database, qui génère les schémas logiques de base SQL, les scripts SQL et qui les exécute, ne présente que peu d'intérêt, car la plupart des technologies, Java, Python… possédant déjà des frameworks de synchronisation bidirectionnels entre les objets et le moyen de persistance, quelque soit son paradigme : SQL, NoSQL, voire XML.
Y a-t-il encore un intérêt pour les outils de génération de code
face à l'IA générative comme ChatGPT ?
La génération de code utilise des paradigmes comme MDA et des frameworks comme Acceleo, qui sont déjà anciens et qui semblent quelque peu désuets face à la puissance, la facilité et l’expansion phénoménale des nouvelles IA génératives (OpenAI ChatGPT, Microsoft Bing Chat, Google Bard ou encore Meta Llama, Anthropic Claude pour les plus connues).
Quelles sont leurs places dans le domaine de l’Architecture d’Entreprise, de l’Architecture Logicielle et la modélisation de système ? C’est l’étude que nous allons effectuer et que nous vous livrerons dans nos articles à venir.
Merci pour vos commentaires et peut-être serez-vous désireux de faire partager vos retours d’expérience ou vos idées sur l’architecture d’entreprise et l’art de la modélisation de système.
Alors, écrivez-nous et nous serons heureux de publier vos articles.
|
|
Rhona Maxwel @rhona_helena |
« Je me suis un peu amusée à tester ces nouveaux outils et ce que je trouve très intéressant, c’est que pour utiliser l’IA dans la phase de recherche et de documentation, il faut entrer des mots. Ça nous force quelque part à mettre des mots dès le départ sur une intention créative. C’est très utile pour formaliser et conceptualiser des idées. »
Adèle Hennion
Compléments de lecture
- Alimenter le référentiel d’Architecture d’Entreprise pour la couche Application de TOGAF avec l’outil Information System Designer (ISD) d’Obeo - Modélisation de l’analyse des besoins S.1 Ep.1
- Méthode Graal, le NoUML d’Obeo, parfaite fusion entre un UML phagocyté et un BPMN édulcoré. S.1 Ep.2
- Comment assurer la traçabilité des exigences avec les user stories, les use cases, les processus métier, la cinématique et les maquettes d'écrans ? Une solution dans notre test Obeo ISD S.1 Ep.3
- Quelle solution pour concevoir la modélisation d’une architecture micro-services, l’intégrer dans une architecture d’entreprise et permettre une collaboration avec l’ensemble des acteurs projet ? Obeo ISD S.1 Ep.4
- Ingénierie Dirigée par les Modèles (IDM) : tutoriel ATL (ATLAS Transformation Language)
- Query View Transform (QVT) Operational : tutoriel
- Démarche d’urbanisation du SI : les questions techniques, organisationnelles, voire existentielles
- Top 5 2023 des outils gratuits ou open source pour l’Architecture d'Entreprise et la modélisation du Système d’Information
A découvrir aussi
- Ingénierie Dirigée par les Modèles (IDM) : le tour de passe-passe des transformations de modèles
- Ingénierie Dirigée par les Modèles (IDM) : cours complet sur ATL (ATLAS Transformation Language)
- Le meilleur outil pour transformer, dériver, parcourir, requêter sur des modèles afin de mettre en œuvre MDA (Model Driven Architecture)
Inscrivez-vous au site
Soyez prévenu par email des prochaines mises à jour
Rejoignez les 837 autres membres