
Génération d'application
7/11 Projet informatique, passer du moyen âge à l'ère industrielle. N'ayez plus peur du "grand méchant générateur de code"
Où en est-on sur la génération de code ? L'OMG (Object Management Group) a depuis plus de 10 ans spécifié des normes sur la transformation de modèles permettant en théorie de générer un modèle de code (PSM Plateform Specific Model) à partir d'un modèle décrivant des processus et des objets métier (PIM Plateform Independant Model).
Seulement voilà, comme à son habitude, l'OMG laisse le soin à d'autres de réaliser les outils conforment à ses spécifications . Plus facile à dire qu'à faire ! Quelques organisations open source ou commerciales s'y sont essayées en respectant plus ou moins les normes et de tout de manière sans succès, personne ne voulant investir sans avoir une garantie sur le retour sur investissement. Les solutions propriétaires existent depuis encore plus longtemps souvent intégrées dans leur AGL (Atelier de Génie Logiciel) sans plus de succès.
Alors faut il intégrer de la génération de code dans les projets ? Et si oui, à quelle dose ?
En 2004 j'avais participé à l'élaboration de l'urbanisation du SI d'un organisme de santé. L'organisation était très "IBMisée" et avait misé sur les outils Rational (racheté par IBM). La stratégie reposait en partie sur la génération de code à partir de modèles UML. Les problèmes sont arrivés lorsque l'équipe d'une dizaine de développeurs ont voulu modifier le code Java généré. RSA (Rational Software Architecture) était censé gérer le round trip, c'est à dire la mise à jour du code en cas de modification des modèles et réciproquement. Malheureusement lorsque plusieurs développeurs faisaient des changements sur les mêmes parties de code, les modèles étaient modifiés que partiellement. Suite à notre plainte, IBM nous a répondu que le bug était répertorié et qu'un patch nous serait livré dans 6 mois! Les raisons de ne pas utiliser les générateurs viennent essentiellement de la faible fiabilité, de la complexité de la mise œuvre, des contraintes imposées, de l'impossibilité de modifier ou de comprendre le code généré ou bien encore que le développeur passe plus de temps à paramétrer l'outil qu'à se concentrer sur la partie métier. Se lancer dans un générateur de code serait bien la dernière chose à faire. Cela paraît peut être trivial mais certains développeurs se laisseraient bien emporter par leur passion dans un tourbillon infini.
Alors faut il définitivement ranger la génération de code aux oubliettes ? Évidement que non car la bonne question à se poser relève une fois encore de la méthodologie c'est à dire : que dois-je générer et par quels moyens ? Les parties de code répétitives, représentent les patterns de conception, l'implémentation des différentes couches d'architecture, les squelettes du modèle métier, les règles métier et tout ce qui relève de la présentation (écrans, rapports, ...).
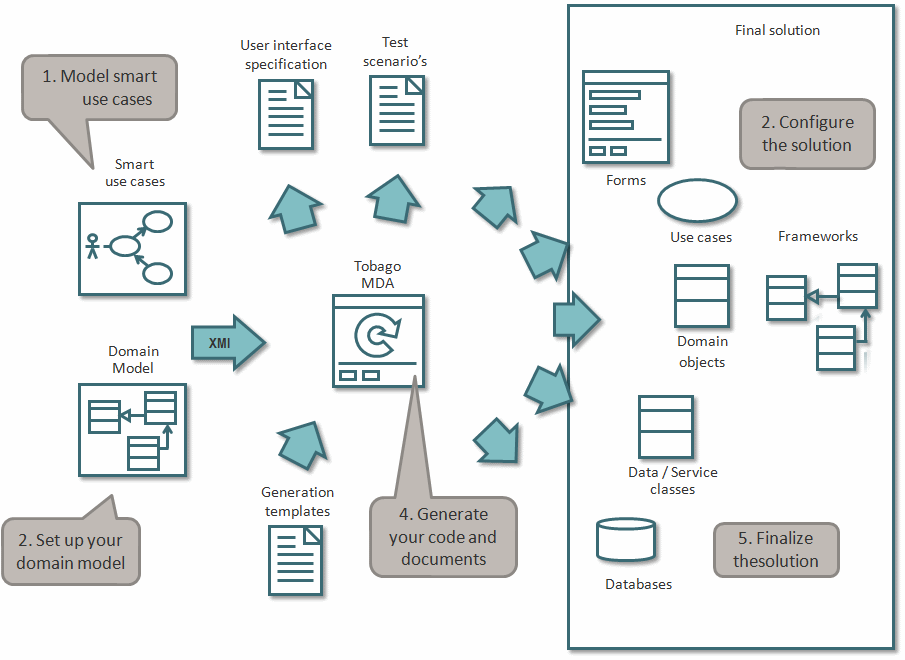
Parmi les dernières tendances de méthode agile comme Accelerated Delivery Platform de Cap Gémini, la génération de codes repose sur des templates et des stéréotypes de Use Case. Dans une application de gestion, on fait toujours la même chose : des recherches, créations, modifications, suppressions, ... d'entités métier. On peut identifier des types de use case comme : <<search>>, <<create>>, ... L'étape suivante est la traditionnelle modélisation du domaine métier avec un diagramme de classe UML. On associe par exemple le use case "rechercher un contrat" de stéréotype <<search>> à la classe "Contrat". Un générateur MDA (Model Driven Architecture) open source comme Tobago MDA permet l'importation du modèle. Le template ( modèle de code) se conçoit à partir d'un bloc de code répétitif dans lequel on remplace les entités à variabiliser par des tags. Le template est positionné dans des structures de boucles ou conditionnelles du générateur et les valeurs à remplacer dans les tags seront récupérées du diagramme de classe UML. Le squelette de code peut être emprunté à la couche présentation ou à toute autre de l'architecture applicative et technique.
Cette manière efficiente de générer du code est entièrement intégrée à la méthode agile ADP et utilise les bonnes pratiques et c'est assez rare pour qu'on le cite les norme UML et MDA. Cela démontre bien que les normes peuvent être utilisées et contribuer au retour sur investissement à condition de viser le pragmatisme et d'oser le changement dans la méthodologie de gestion de projet car rien ne vaut le changement pour dynamiser et motiver une équipe.
Voir aussi le site : "Abandonnez le classicisme, relookez votre SI"
Tout le monde en rêve et personne ne l'a jamais fait ...
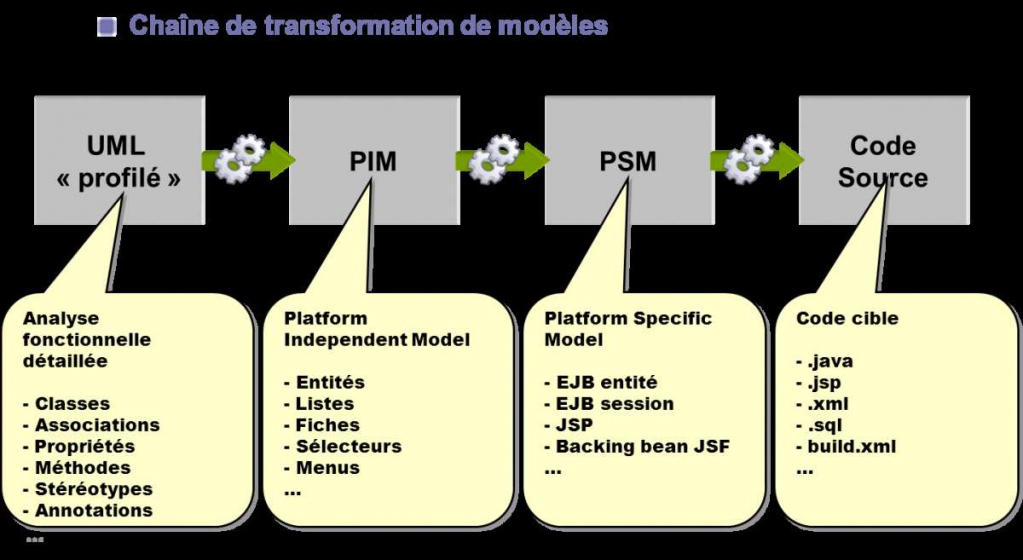
Partir d'un modèle de concepts métier et transformer ce modèle en d'autres modèles s'affinant progressivement pour arriver finalement à un modèle de code source.
En 2014 l'homme devra encore se plier à la machine.
Depuis longtemps on nous promet pour les applications informatiques de gestion de commencer par modéliser les concepts métier : les processus, les entités, les règles et les éléments d'IHM, puis d'indiquer l'architecture cible et laisser la technique générer le code source Java, .NET, Web, ....
Les enjeux sont de taille. Cela permet de se concentrer sur les aspects métier, l'optimisation et la flexibilité des processus par la mise en place de BPM (Business Management Process), de capitaliser les connaissances comme les règles métier avec un BRMS (Business Rules Management System), de pérenniser le modèle de données métier avec une modélisation optimisée avec UML (Unified Modeling Language).
Aujourd'hui de nombreuses applications vieillotes réalisées à l'ancienne sont rajeunies en changeant les techniques d'IHM, en relookant les écrans dans un style tendance à la Facebook, en développant de nouveaux domaines dans les technologies adoptées par l'industrie IT comme Java ou .NET. Et puis dans 10 ans, on changera tout à nouveaux pour les dernières architectures à la mode.
Quelque soit la plateforme cible (Java, .NET, Web, Google, Mainframe, ...), l'architecture est toujours la même avec les couches : présentation, contrôleur, services métier, injection de dépendances, persistances, SGBDR, moniteur transactionnel, ...
Et pourtant dans chaque projet, on recommence par concevoir et valider l'architecture, à mettre en place la pile de framework correspondant aux couches précédentes et on refait toujours la même chose. Les consultants facturent cher un travail qu'ils ont déjà fait car les solutions sont bien connues et pourraient être automatisées. N'importe quel architecte sait qu'il doit mettre en place par exemple dans une architecture Java classique la persistance avec Hibernate, le workflow écran, l'injection de dépendance, les transactions, les batchs avec Spring, les IHM avec HTML/Javascript/JSF/GWT/ ... etc, etc.
Pourtant fin des années 90 début 2000, les grands éditeurs comme IBM, Sun (racheté par Oracle), Borland (racheté par Micro Focus), Oracle, ... et les organismes de normalisation comme l'OMG (Object Management Group) ont mis au point des solutions. Une des plus prometteuse est MDA (Model Driven Architecture) constituée d'un nombre impressionnant d'autres normes comme UML (Unified Modeling Language), OCL (Object Constraint Language), MOF (Meta Object Facility), XMI (XML Metadata Interchange), QVT (Query View Transformation), ASL (Action Semantics Language), etc, etc.
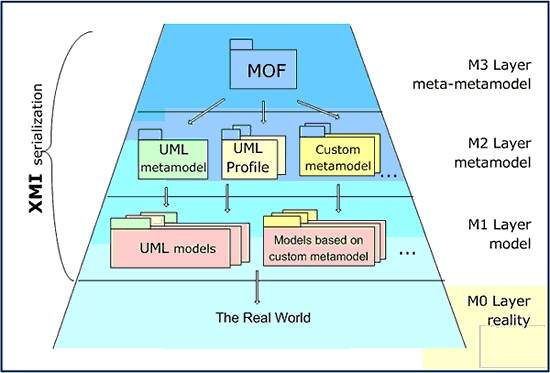
On part de la vraie vie c'est à dire les objets (par exemple la facture du 26/01 du client Martin), puis on remonte d'un niveau d'abstraction, au niveau modèle (la classe Facture et Client) puis encore plus abstrait avec le méta modèle (on modélise le modèle : Classe, Attribut, Association, ...) puis enfin ça se termine avec le méta méta modèle (tout est objet : Classe).
Depuis des décennies les grands acteurs IT parlent d'outils, de normes et de framework dans le but de générer un maximum de codes.
L'idée la plus alléchante étant à partir d'un modèle métier et indépendant de la technique (CIM Computation Independent Model), de génèrer un autre modèle indépendant d'une plateforme de développement (PIM Plateform Indépendent Model), puis génére un modèle spécifique à une plateforme (PSM Plateform Specific Model) comme Java, .NET, SQL, ... Puis enfin génèrer un modèle de code qui pourra être traduit directement dans un langage informatique standard.
Pour pouvoir transformer des modèles, il faut pouvoir manipuler le méta modèle (MOF) avec un langage (QVT).
Dans l'architecture MDA tout est piloté par les modèles, on trouve aussi la réciproque ADM (Architecture Driven Model) permettant de faire du reverse engineering c'est à dire que les modifications métier (ajout d'un attribut métier par exemple) vont se retrouver dans les modèles PSM, PIM et CIM. On parle alors de round trip (autoriser les transformations inverses).
Tout ceci est très joli sur la papier. L'OMG ne fait que des normes et ne s'occupe pas des implémentations. Elle recherche du reste souvent des partenaires et sponsors pour réaliser ses normes.
Dans la communauté IT pour se démarquer de l'OMG, on utilise souvent l'acronyme MDE (Model Driven Engineering), c'est le seul qui n'a pas été déposé comme marque par l'organisme de normalisation !
Pour que ça marche réellement et que ce ne soit pas juste de la simple génération de code, il faut avoir le méta modèle du PIM avec les classes métier, les services, les éléments d'IHM (liste déroulante, ...), ..., le méta modèle du PSM facilement réalisable par les architectes techniques car il suffit de modéliser les nombreuses instances d'architectures existantes et enfin un transformateur de PIM en PSM.

MDA ne fournit pas d'implémentation qui est complexe, coûteuse et risquée à réaliser. Il faut les méta modèles du PIM et PSM et un transformateur de ces modèles.
Alors serait ce le Saint Graal ?
Apparement non car les gros projets ne l'utilisent pas du tout. Les raisons sont multiples. D'abord le coût d'appropriation des concepts et donc le retour sur investissement. La conjoncture actuelle ne se prête pas à de la recherche et développement. Les solutions proposées par les éditeurs ou par les open sources sont trop variées sans réelles pérennités. Les projets sont contraints par les délais et le budget de plus en plus serré. On a tendance à utiliser les bonnes vieilles méthodes. Le source est déporté sur le PIM qui doit être correctement modélisé et c'est là qu'il y a le principal risque. Comment gérer les itérations lorsqu'on modifie les sources ? Faut il faire des transformations inverses ? Faut il régénérer à partir du PIM ? Quelles sont les réels retours d'expérience avec leur ROI et non pas de la simple génération de codes ou de mise en place de template de codes.
Encore une fois la boucle est bouclée. Les normes sont intéressantes sur la papier, les éditeurs commencent des implémentations prometteuses mais incomplètes et attendent que les grands comptes s'y mettent mais comme il n'y a rien de consistant, sans retours d'expérience et en ces temps économiques non propices aux investissements personne ne veut payer pour les autres. La génération automatique d'applications informatiques à partir de modèles applicatifs n'est pas pour demain, les architectes techniques et les développeurs ont encore de beaux jours devant eux.
Voir aussi le site :