
Visual Paradigm : l’eldorado du consultant en quête de présentations dorées, mais est-il un bon outil de modélisation pour l’architecte d’entreprise, voici notre test
Cet outil gratuit, en français, en mode SaaS dans le cloud, accessible à partir de nombreux appareils mobiles (iOS, Android…), offre un panorama hétéroclite de modèles de visuels, dont voici une liste à la Prévert : cartes cadeaux, anniversaire, menus, albums photos, tableaux de bord, graphiques statistiques, bande dessinée… et ce qui nous intéresse tout particulièrement les diagrammes ArchiMate, BPMN, et UML.
Visual Paradigm propose pêle-mêle des cartes cadeaux,
mais aussi des diagrammes d'architecture d'entreprise
Pourquoi Visual Paradigm est le couteau suisse du consultant pressé de rédiger sa présentation PowerPoint
Installation
Un mail valide suffit à créer un compte permettant d’accéder aux outils de dessin et aux innombrables templates.
Tous les formats d’export sont proposés : JPEG, PNG, SVG, PDF et même directement comme image vers Microsoft Office, très pratique par exemple pour les présentations PowerPoint.
ArchiMate
Pour ArchiMate, Visual Paradigm propose 168 templates. Ces exemples couvrent toutes les couches : Stratégie, Métier, Application, Technologique & Physique, Motivation, Implementation & Migration.
Le consultant trouvera certainement une vue similaire à ce qu’il désire modéliser.
Quant aux étudiants, ils trouveront là des illustrations pratiques des concepts théoriques d’ArchiMate en complément de cours plus didactique.
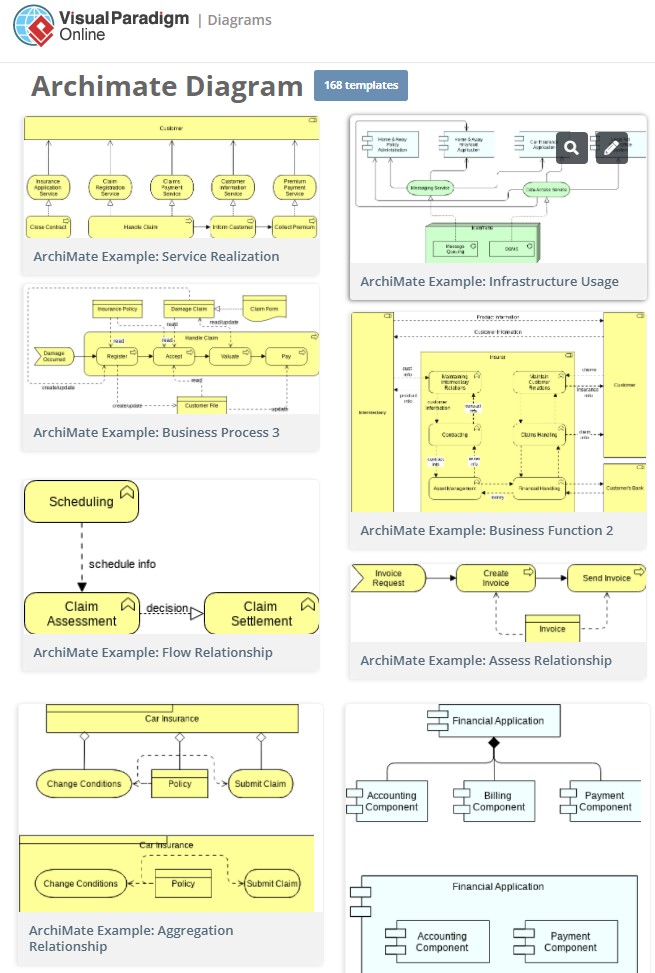
Visual Paradigm propose 168 exemples de diagrammes ArchiMate
BPMN

Visual Paradigm propose 4 exemples de diagrammes BPMN
La prise en main est immédiate, tout est à portée de souris, bravo l’ergonomie.
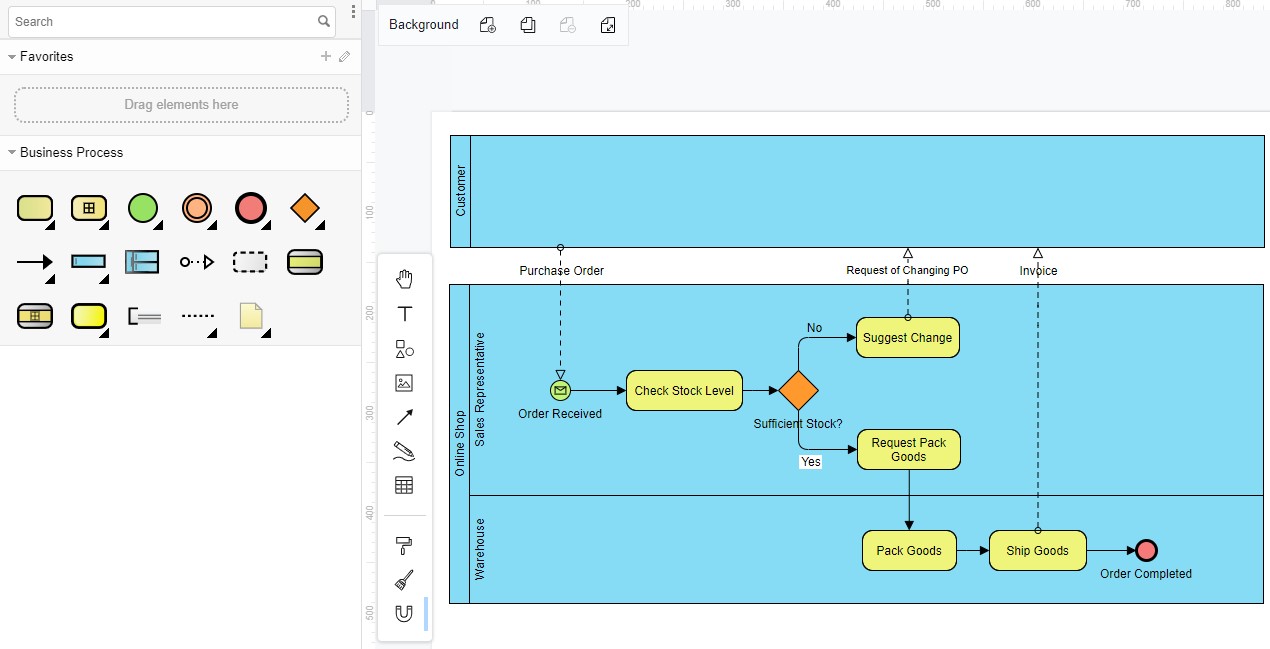
Exemple d'un processus avec Visual Paradigm
UML
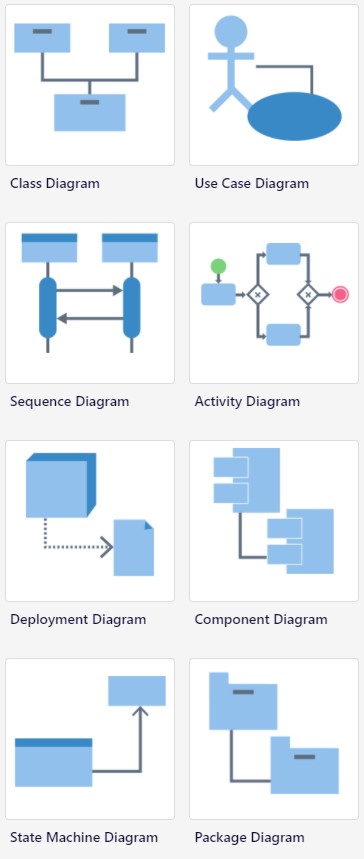
Visual Paradigm propose 8 types de diagrammes UML, il en manque 5 !
Manque 5 diagrammes pour couvrir la norme de l'OMG : object, communication, composite structure, interaction overview et timing, ce qui peut être rédhibitoire dans certains cas comme ne pas pouvoir mettre des contraintes de temps sur des transitions d’états.
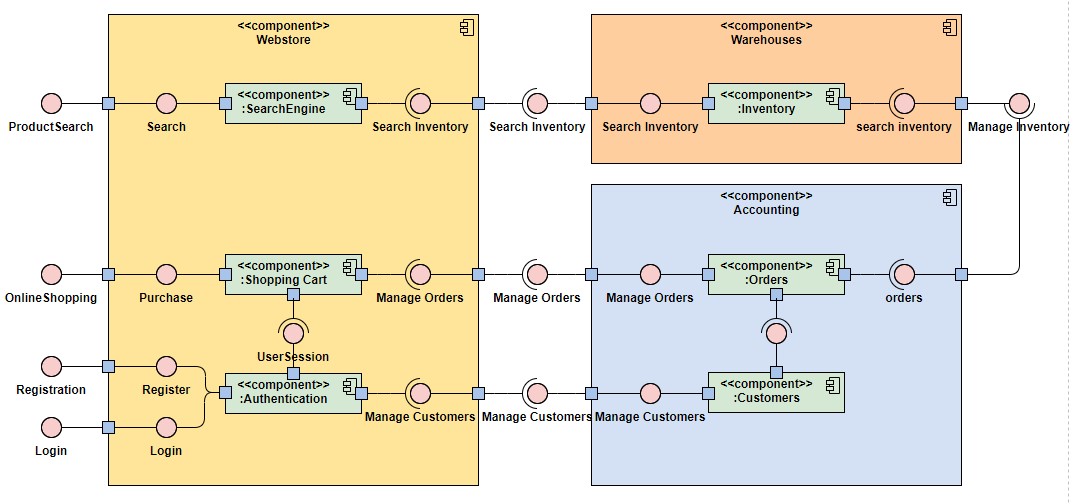
Exemple de diagramme UML de composants avec Visual Paradigm
Le diagramme de composants permettant de modéliser les connexions, grâce aux interfaces requises et fournies est complet et encore une fois l’élaboration se fait de manière très intuitive.
Bravo pour le partage d’écran
Pour partager son écran, il suffit d’aller dans le menu “Share” puis “Collaboration”, de saisir le mail d’un collègue et les permissions par défaut des membres de l'équipe, à choisir entre : édition, visualisation, ou accès seulement au créateur.
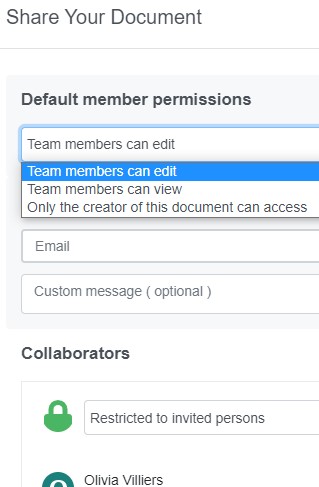
Partage de document et affectation des droits avec Visual Paradigm
Le coéquipier reçoit dans sa boîte mail un lien demandant confirmation. Une fois le mail validé, un autre mail est envoyé avec un lien permettant d’accéder au document qui a été partagé.
Un utilisateur qui vient de créer un diagramme peut partager son écran avec un collègue qui a été dûment référencé.
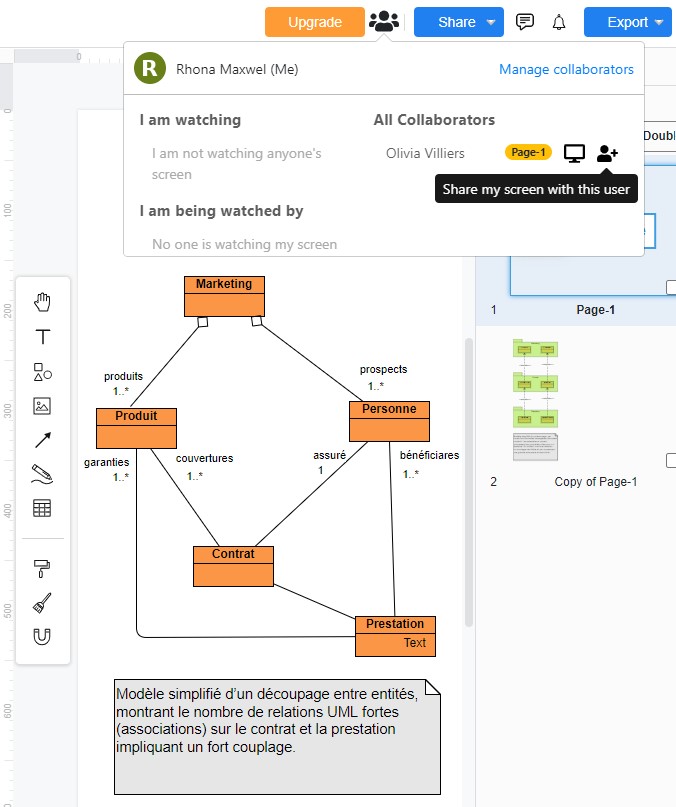
Activation du partage écran avec Visual Paradigm
Un membre d’une équipe peut demander la permission pour voir l’écran d’un autre qui recevra une notification demandant l'autorisation.
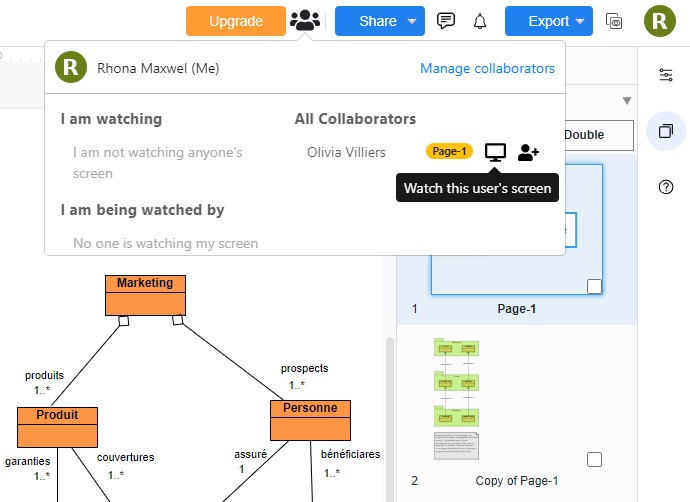
Demande de visualisation d'un écran d'un autre membre de l'équipe
Les actions d’un utilisateur distant sont répercutées en temps réel.

Un autre membre distant à qui l’on a autorisé l'accès au diagramme, est en train de déplacer sa souris indiquée ici en vert avec son nom
Un membre d'une équipe est en train de regarder l'écran distant d'un autre, apparaissant entouré d'un cadre violet avec le nom du membre distant
Pourquoi Visual Paradigm n’est pas un outil destiné
à l'architecte d’entreprise
Un outil d’architecture d’entreprise doit gérer un référentiel d'objets (acteur métier, rôle métier, processus métier…), leur cycle de vie ainsi que les méta-informations pour la gouvernance. Rien de tout cela ici, Visual Paradigm, se contente uniquement de stocker les diagrammes dans un Cloud comme VP Online (celui de Visual Paradigm), Google Drive… ou sur un support local de persistance.
Exemples de fonctionnalités essentielles manquantes et indispensables dans un outil d’architecture d’entreprise :
- Pas de traçabilité pour les mesures d’impact
- Pas d’analyses, de génération de documentation, de rapports, de tableau de bord
- Pas de vérification des diagrammes
- Pas d’audit
- Pas de métamodèle
- Pas de scripts
- Pas de support MDA
- Pas d’interopérabilité avec les autres outils
- Pas de support XMI
Conclusion
Ce logiciel hyper généraliste conviendra aux infographiste, intégrateur web, designer, business analyst, AMOA… sauf à l’architecte d’entreprise pour qui l’absence de référentiel, de système de traçabilité, de navigation entre les artefacts de modélisation, de méta-modèle, de génération de rapports… sera rédhibitoire.
Par contre, sa gratuité, sa facilité d’installation en mode SaaS ne demandant aucune connaissance technique, la possibilité de partager son écran à des coéquipiers et les nombreux exemples ArchiMate, BPMN, UML, prêts à être adaptés, font de Visual Paradigm un excellent outil pédagogique pour mettre en pratique l’art de la modélisation.
Note : 3/5
Nous regrettons :
- Que ce soit uniquement un outil de dessin.
Nous aimons :
- Le mode SaaS
- Le partage d’écran permettant le travail en équipe
- Les innombrables exemples ArchiMate, BPMN et UML
- Son excellente ergonomie
|
|
Rhona Maxwel @rhona_helena |
“Celui qui, par quelque alchimie sait extraire de son cœur, pour les refondre ensemble, compassion, respect, besoin, patience, regret, surprise et pardon crée cet atome qu'on appelle l'amour.”
Khalil Gibran
Compléments de lecture
Outils de Modélisation et comparatifs
- Essai et évaluation de Modelio : est-il un bon outil de modélisation ?
- ADOIT:CE pour la gestion de l’Architecture d’Entreprise
- ADOIT:CE (compléments d’information)
- Le meilleur du meilleur des outils de modélisation de Systèmes d’Information pour 2017 : les « Modsars » de « urbanisation-si.com » récompensent les plus innovants
- Les meilleurs outils de modélisation UML, SysML, BPMN, DMN de l'année 2016 et les gagnants sont ...
Apprendre ArchiMate
- ArchiMate pour les nuls : les fondamentaux - 1
- ArchiMate la synthèse : les éléments de motivation - 2
- ArchiMate en condensé : les éléments de stratégie - 3
- ArchiMate l’essentiel : les éléments de la couche métier - 4
- ArchiMate mémento : les éléments de la couche application - 5
- ArchiMate aide mémoire : les éléments de la couche technologique - 6
- ArchiMate en abrégé : les éléments physiques de modélisation - 7
- ArchiMate mémento : Alignement de la couche métier avec les couches inférieures - 8
- ArchiMate : modélisation de l’alignement des couches d'application et de technologie - 9
- ArchiMate : les éléments d'implémentation et de migration - 10
- ArchiMate : vues et points de vue - 11
- ArchiMate : guide complet des éléments de modélisation - 12
BPMN
- BPMN 2 : les concepts de base des processus métiers
- BPMN pour les nuls : les collaborations
- BPMN pour les nuls : les chorégraphies (Choreographies)
- BPMN pour les nuls : les conversations
- BPMN : norme OMG - synthèse des éléments graphiques
- BPMN : l'antisèche pour rester incollable en modélisation de processus
- BPMN l’exemple type pour tout comprendre sans prendre d’aspirine
- BPMN : la norme, toute la norme rien que la norme. L'exemple à lire en attendant une pizza
- BPMN : mais que dit la norme sur les sous-processus et la gestion des événements d'interruption et de remontée d'incidents ?
- BPMN : processus exécutables, comment s'y prendre ? (1/3)
- BPMN : processus exécutables, comment s'y prendre ? (2/3)
- BPMN : processus exécutables, comment s'y prendre ? (3/3)
- Comment identifier, simuler, améliorer et modéliser les processus métiers ?
- Comment mettre en place un jeu de rôles pour modéliser un processus métier ?
Pour devenir expert en UML
- Modélisation de système : Soyez maniaque, croisez et recroisez vos modèles UML pour être certain qu'ils soient valides (4)
- Modélisation de système : Soyez maniaque, croisez et recroisez vos modèles UML pour être certain qu'ils soient valides (5)
- Modélisation de système : Soyez maniaque, croisez et recroisez vos modèles UML pour être certain qu'ils soient valides (6)
- Modélisation de système : Soyez maniaque, croisez et recroisez vos modèles UML pour être certain qu'ils soient valides (7)
- Modélisation de système : Soyez maniaque, croisez et recroisez vos modèles UML pour être certain qu'ils soient valides (8)
- Modélisation de système : Soyez maniaque, croisez et recroisez vos modèles UML pour être certain qu'ils soient valides (9)
- Modélisation de système : Soyez maniaque, croisez et recroisez vos modèles UML pour être certain qu'ils soient valides (10)
- Modélisation de système : Soyez maniaque, croisez et recroisez vos modèles UML pour être certain qu'ils soient valides (11)
- Modélisation de système : Soyez maniaque, croisez et recroisez vos modèles UML pour être certain qu'ils soient valides (12)
- Modélisation de système : UML n'est rien sans OCL !
- Modélisation de système : OCL ça se complique !
- Modélisation de système : comment utiliser OCL avec Eclipse, c'est bien la question que tout le monde se pose
Le PILI était-il un bon modèle ?
En fin d’année 2021, la RATP a mis en vente aux enchères du mobilier réformé, au profit d’une œuvre caritative (belle initiative). Parmi les 215 lots mis en vente figuraient quatre PILI :
Panneaux Indicateurs Lumineux d’Itinéraires.
Rien à voir avec la sauce piquante à base de piment pour relever le goût de votre pizza, donc.
Lorsque j’étais enfant, j’aimais beaucoup appuyer sur l’un des 300 boutons chromés, un pour chaque station de métro de destination, afin d’allumer l’itinéraire le plus direct pour s’y rendre (à partir de la station où je me trouvais) :

Positionnées sur le plan du métropolitain parisien, plus de 300 ampoules et, derrière ce plan, sans doute plusieurs kilomètres de câble électrique !
Après l'évocation de ce bon souvenir, empreint de nostalgie, la déformation professionnelle a rapidement repris le dessus :
Le PILI était-il un bon modèle ?
Voici une définition concise : un bon modèle doit représenter au mieux une partie du monde réel.
Sur quels critères plus précis peut-on s'appuyer pour déterminer un bon modèle ?
En 2017, j’avais publié une liste de 7 critères établie par Mader et al. 2007 pour qualifier un bon modèle :
- Il a un objet de modélisation clairement spécifié :
Oui, modéliser le réseau du métropolitain parisien.
- Il a un objectif clairement spécifié :
Oui, afficher l'itinéraire le plus rapide pour se rendre d'une station à une autre.
- Il est simple (le critère le plus difficile ?) :
Oui, pas besoin de mode d'emploi. Un seul "clic" sur le bouton de la station de destination suffit.
- Il est véridique :
Oui, la réalité du terrain est bien représentée.
(les ampoules pour représenter les différentes correspondances d'une seule station sont toutefois décalées. Exemple ci-dessus : Châtelet Les Halles)
- Il est traçable :
Oui, mais ce critère n'est pas primordial ici (peu d'évolutions du réseau)
- Il est extensible et réutilisable :
Non, le PILI n'était pas extensible : difficile d'ajouter une nouvelle station, voire une nouvelle ligne.
Par contre, il était réutilisable : près de 200 PILI furent déployés (soit dans 2 stations de métro sur 3)
- Il est conçu pour l’interopérabilité et le partage :
Non pour l'interopérabilité : pas d’actualisation possible pour signaler un incident ou une station fermée
Oui pour le partage : les PILI connurent un grand succès populaire, sans doute grâce à leur simplicité.
Les PILI obtiennent une note de 6/7 avec cette liste de critères ! Belle performance.
Les PILI possédaient d'autres propriétés :
- Maintenance très délicate en cas de panne,
mais malgré cet inconvénient, apparemment gérable :
- Longévité exceptionnelle, de 1937 à 2016 approx.
(sans doute liée à la stabilité du réseau)
Qui d'autre conçoit des modèles compris par les utilisateurs finaux
et utilisés pendant presque 80 ans ?

Panneau métropolitain de style Guimard
Il y a quelques années, la RATP avait repris le principe du panneau interactif sur son site web : le plan complet du réseau s’affichait et il suffisait de poser le pointeur de sa souris sur une ligne pour que leurs autres lignes s’estompent aussitôt.
Aujourd’hui, ce plan complet est complètement statique... Et chaque ligne (avec ses stations et ses correspondances) s’affiche désespérément à l’horizontale, sans rapport avec la réalité du terrain :

La réponse est donc oui, le PILI était un bon modèle
Sans aucun doute meilleur que le modèle actuel publié sur le site web.
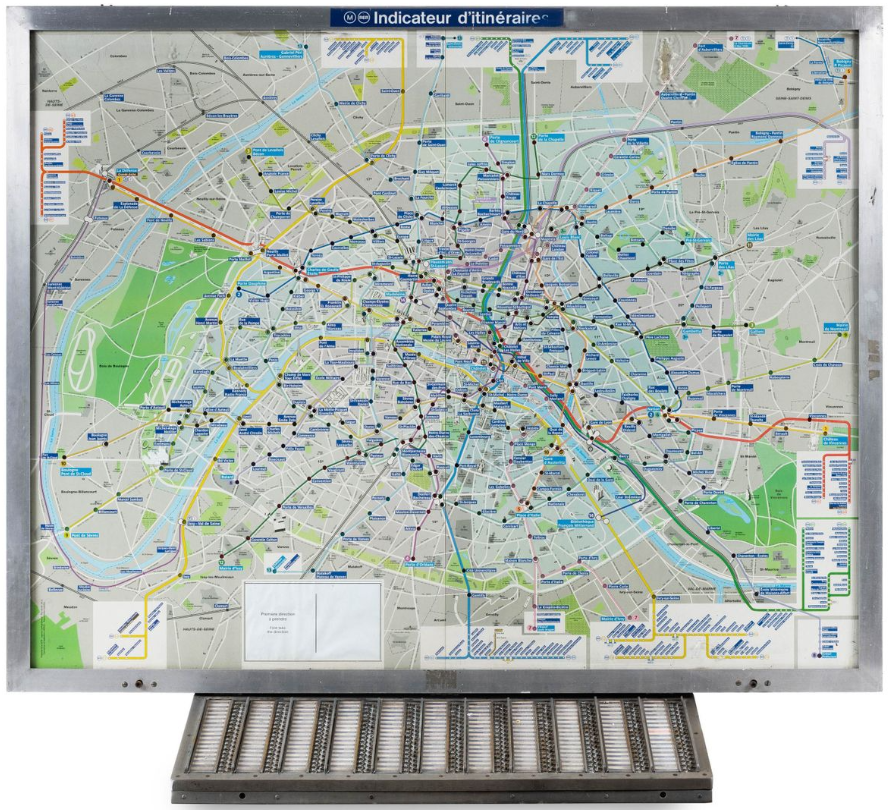
Malgré leurs caractéristiques impressionnantes (hauteur : 160 cm ; largeur 185 cm ; poids : 120 kg) nécessitant un grand salon, ces quatre PILI - sans aucune garantie de bon fonctionnement - ont tous trouvé acquéreurs à des prix compris entre 2.650 et 2.850 € ! Le prix qu’une très grande TV 4K UHD.
L’un des rares inconvénients du PILI, présenté dans le post ci-dessus, était son manque d’interopérabilité : pas d’actualisation possible pour signaler un incident ou une station fermée. Cet inconvénient a disparu grâce aux sites web, aux applications mobiles et aux réseaux sociaux : il est possible désormais d’actualiser rapidement les informations auprès des usagers (info trafic). Mais cette possibilité ne conduirait-elle pas vers certains excès ? Voici un exemple, réel et extrême.
Le 21 septembre 2022, des travaux sur la ligne D du RER ont entrainé la fermeture de 8 stations. Une douzaine de bus, voire le RER C, étaient proposés pour se substituer au RER D. Voici le plan avec les itinéraires de substitution qui ont été proposés aux usagers sur le réseau social Twitter :
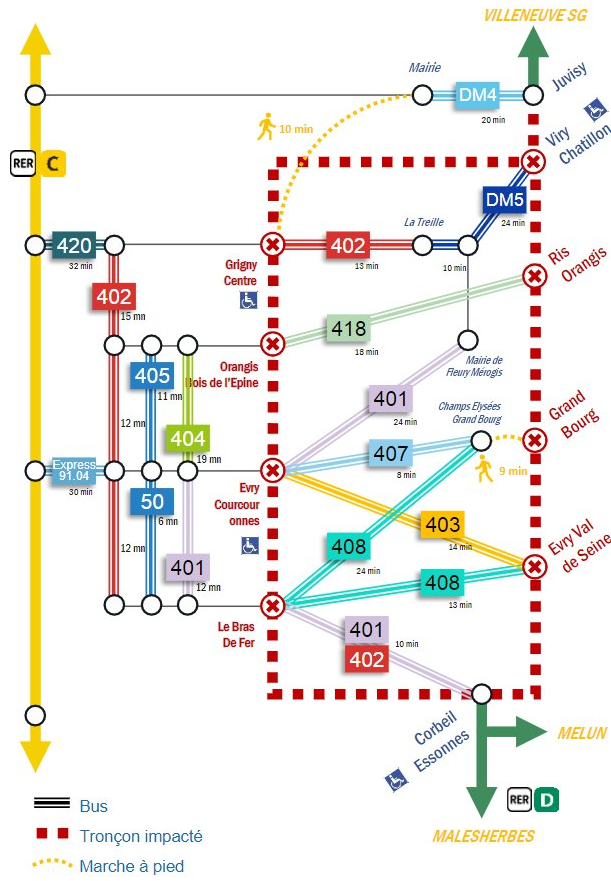
Plusieurs qualificatifs, la plupart flatteurs, peuvent s’appliquer à ce plan : spectaculaire, coloré, exhaustif, détaillé, précis, voire extravagant, limite usine à gaz, non ?
Par contre, euh, comment dirais-je : il valait mieux ne pas avoir à se déplacer en transport en commun à ce moment-là ! Un indice pour tenter de vous y retrouver : la légende est incomplète ; un fin trait noir semble relier une seule et même station de bus. C’est d’ailleurs étonnant que les représentations des lignes de bus 401 et 402 soient scindées en trois tronçons. En fin connaisseur du protocole de communication HTTP, j’aurais personnellement évité la ligne de bus 404, de peur de ne pas arriver à destination 😉
Pour reprendre le refrain à la mode actuellement, il convient (parfois) de privilégier la marche ou le vélo !
|
|
Thierry Biard
|
« L’artiste imprime à son œuvre un sceau de personnalité alors que l’ingénieur est amené à se considérer comme l’artisan d’une œuvre impersonnelle. »
Fulgence Bienvenüe (1852-1936), père du Métropolitain
Agilité logicielle : quelle solution pour diminuer le couplage entre sous-systèmes et obtenir une architecture logicielle agile ?
Des plus petites aux plus grandes entreprises, le concept de bounded context est aujourd’hui au cœur de la conception d’architecture logicielle, mais se pose l’éternelle question de quelle méthode pour parvenir à un découpage produisant le couplage le plus faible, augmentant ainsi l’évolutivité, l'autonomie et l'agilité.

Evolution de l'architecture logicielle
Dans notre article consacré au livre Urbanisation, SOA et BPM, l’auteur Yves Caseau, insiste sur l’urbanisation fractale ou comment appliquer récursivement les mêmes principes à différentes échelles du SI. En effet, les concepts, comme les “General Responsibility Assignment Software Principles" (GRASP) ou encore les design patterns du GoF (Gang of Four), mis en œuvre dans la conception orientée objet à toute petite échelle, se retrouvent dans les strates supérieures au niveau de l’architecture d’entreprise. Ces principes sont les gammes de l’architecte logiciel, qui s’acquièrent au plus bas niveau en programmation orienté objet et qui permettent ensuite d’avoir les bons réflexes au niveau d’un SI global.
D'après Craig Larman, ces patterns sont des “boîtes à outils mentales”, une aide à la conception à petite ou à très grande échelle.
Nous appliquerons donc ces patterns au niveau architecture logicielle, afin d’obtenir un couplage faible et une forte cohésion.
De la démultiplication des critères qualité
Commençons par un problème récurrent de l’architecture logicielle qui est de pouvoir gérer l’évolutivité et la résilience. Une première idée est de multiplier les systèmes que ce soit au niveau du front-end ou du back-end. A partir de ce moment, une série de problèmes va se poser. Par exemple, comment gère-t-on les états, que choisir entre stateless et stateful ? Doit-on stocker l’état dans tous les back-ends ou bien doit-on mettre en place une solution de “sticky session” pour retrouver le système qui a enregistré l'état. Cette solution est complexe, elle utilise un équilibreur de charge (load balancer), une gestion d’identifiants supplémentaires, mais que se passe-t-il s’il tombe en panne, si le back-end contenant l’état devient surchargé ?
Faisons alors du stateless avec un cache partagé qui contiendra l’état. Si le cache tombe, on met un cluster, mais cela implique que l’on doit gérer la réplication et la cohérence des données…
C’est l’escalade presque sans fin des patterns Circuit Breaker (Disjoncteur), Bulkheads (Cloisonnement)… (voir notre article Solutions sur étagère pour la gestion des défaillances des Micro-Services)
Afin d’éviter cette course effrénée aux propriétés de qualité, il faut s’intéresser à la volumétrie de l’entreprise concernée : a-t-on besoin d’une surenchère de tels systèmes pour une entreprise de quelques dizaines d’utilisateurs ? A-t-on besoin de temps réel ? Pour la plupart des TPE ou PME, les enjeux ne justifient pas la mise en œuvre de systèmes redondants et hautement performants pour des coûts exorbitants.
Une pléthore de possibilités de découpages
Découpage par couches
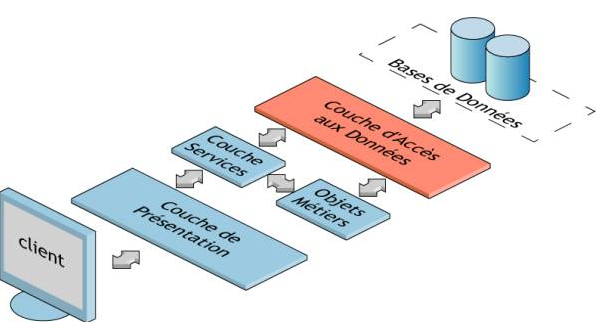
Découpage par couches
Souvent le plus utilisé, le découpage par couche, consiste à séparer l’aspect web (présentation + contrôleur), l’aspect métier (services + règles), DAO (Data Access Object) et enfin la persistance. Le nombre d’appels entre chaque couche est très important et les risques de conflits au moment des commits sont augmentés.
Découpage par technologies
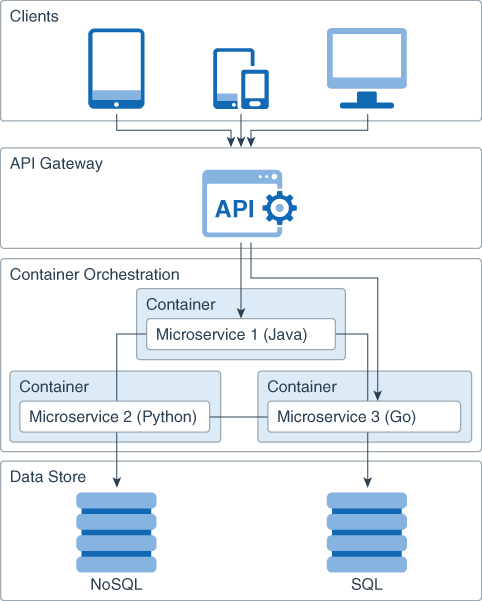
Découpage par technologies
L’exemple typique est d’avoir un existant composé par exemple d’un monolithe Java avec Jakarta EE (anciennement JEE), d’un système plus récent architecturé en micro-services avec Node.js, pour l’IA une architecture Python avec sa cohorte de bibliothèques de Machine ou Deep Learning, les référentiels avec SQL basé sur MySQL ou noSQL basé sur MongoDB… Un couplage fort sera forcément présent, par exemple entre Jakarta EE et MySQL ou Node.js et MongoDB.
Découpage entre entités
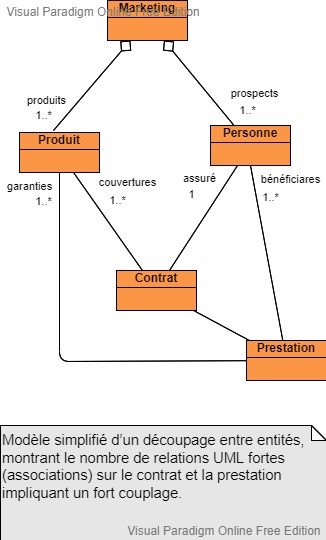
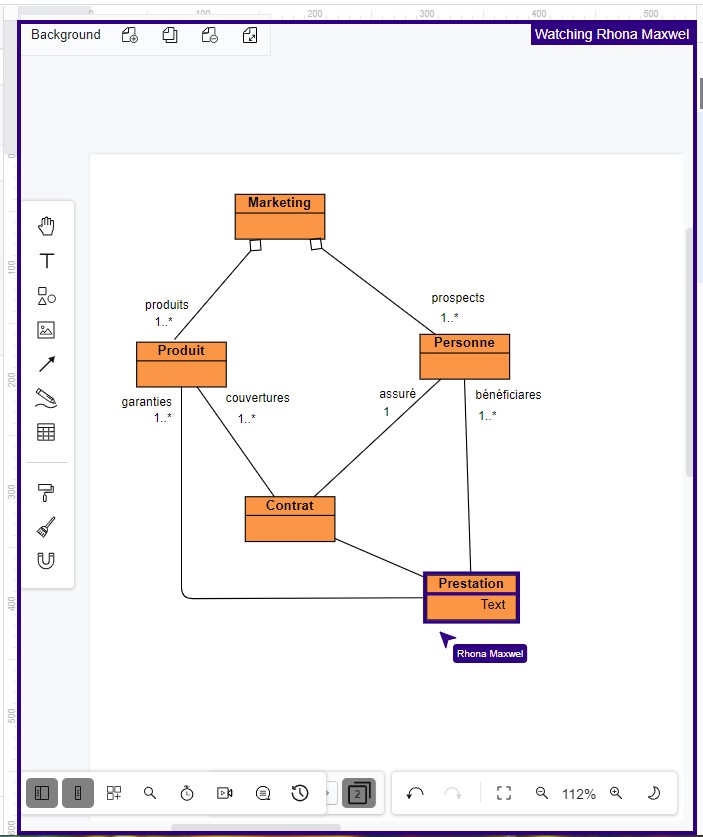
Diagramme UML de classe réalisé avec l'outil gratuit Visual Paradigm
L’architecture micro-services est souvent basée sur ce type de décomposition. A titre d’exemple volontairement simplifié, pris dans le monde assurantiel, on va trouver les micro-services Produit, Personne, Contrat, Prestation…
L’accès aux informations d’un contrat va entraîner de nombreux échanges nécessitant un fort couplage.
Pour calculer une prestation, on a besoin du contrat, de la personne…
Les entités Contrat et Prestation auront besoin de nombreuses données en provenance des entités Produit et Personne, d’où des relations fortes sous forme d’associations UML, ce qui introduit un couplage fort, une augmentation de la bande passante réseau, de CPU, sans oublier les nombreux conflits sur le SCM (Source Control Management).
Mais alors quel découpage préconisé ?
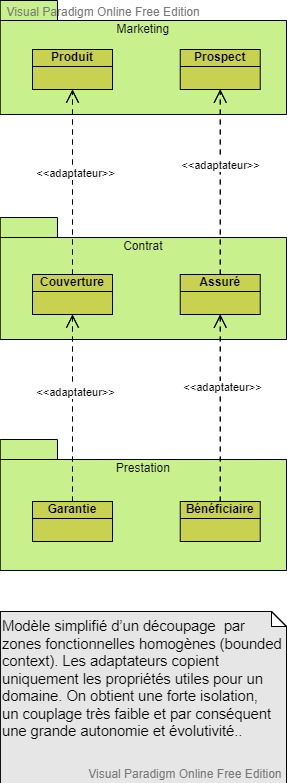
Diagramme UML de classe réalisé avec l'outil gratuit Visual Paradigm
Les décompositions précédentes présentent donc des problèmes de performances, de conflits entre les développements et un fort couplage semblable à une architecture spaghetti.
La bonne solution : le découpage par zones fonctionnelles homogènes (bounded context), regroupant des entités appartenant à un même domaine.
Reprenons notre exemple, on peut constituer 3 domaines fonctionnels homogènes : Marketing (Produit, Prospect), Contrat (Couverture, Assuré) et Prestation (Garantie, Bénéficiaire).
Dans le domaine Marketing, les entités Produit et Prospect deviennent respectivement dans le domaine Contrat, Couverture et Assuré, qui eux-mêmes deviennent Garantie et Bénéficiaire dans le domaine Prestation.
La même personne en chair en os avec la même identité est vue comme prospect dans le marketing, assuré dans le contrat et bénéficiaire dans la prestation.
De même pour un produit dans le marketing, le domaine contrat va utiliser les données de couverture et la prestation les données concernant les garanties.
Cette méthode de regroupement permet d’avoir des zones autonomes. Les liens s’implémentent par des adaptateurs chargés de recopier uniquement les données utiles d’une entité dans une autre.
Mais alors, on viole le principe de non-duplication de données ?
Les adaptateurs copient uniquement les propriétés utiles pour un domaine, c’est le prix à payer pour avoir une forte isolation, un couplage très faible et par conséquent une grande autonomie et évolutivité.
Cette duplication des données se retrouve partout dans la vraie vie, par exemple dans les réseaux sociaux : on a un ami sur Facebook, un candidat sur LinkedIn, un commiter sur Github, un collaborateur sur Slack… Ces différentes plateformes gèrent avec leur propre sémantique la même personne, mais adaptée à leurs objectifs et peuvent partager le même identifiant permettant de se connecter avec un ID Google ou Facebook par exemple.
Le pouvoir de choisir la technologie la plus adaptée
Autre avantage d’une bonne découpe, c’est de pouvoir choisir la technologie la plus adaptée
Prenons l’exemple de la persistance :
- Domaine Marketing regroupant les produits et les prospects : NoSQL favorisant les recherches rapides sur de gros volumes en lecture.
- Domaine Contrat : RDBMS (Relational Database Management System) SQL, pour les aspects transactionnels.
- Domaine Prestation : RDBMS SQL ou Cassandra NoSQL conçu pour gérer des quantités massives de données sur un grand nombre de serveurs, assurant une haute disponibilité en éliminant les points de défaillance unique.
Conclusion
Ce concept de bounded context est de plus en plus considéré et mis en œuvre dans les entreprises et fait partie du DDD Domain Driven Design (voir nos articles Les couches de l'Architecture Microservices et la méthode de conception DDD (Domain Driven Design) et Architecture Hexagonale, exemple de mise en pratique de la méthode DDD Domain Driven Design).
La difficulté consiste à bien délimiter les contours. Pour les identifier, il faudra alors faire appel à l’expérience et à des heuristiques propres.
|
|
Rhona Maxwel @rhona_helena |
“Apprendre à penser, à réfléchir, à être précis (…), à écouter l’autre, c’est être capable de dialoguer, c’est le seul moyen d’endiguer la violence effrayante qui monte autour de nous. La parole est le rempart contre la bestialité.”
Jacqueline de Romilly
Compléments de lecture
- L’Architecture Micro-Services expliquée à ma fille
- Inconvénients de l'Architecture Micro-Services
- Orchestration des micro-services avec BPMN
- Conseils pour réussir vos micro-services et éviter qu’ils ne se transforment en véritable pensum
- Estimation de la complexité d’une Architecture Micro-Services
- Solutions sur étagère pour la gestion des défaillances des Micro-Services
- Comment éviter la loi de Conway et faciliter ainsi l’agilité avec l’approche Micro-Services ?
- Les couches de l'Architecture Microservices et la méthode de conception DDD (Domain Driven Design)
- Architecture Hexagonale, exemple de mise en pratique de la méthode DDD Domain Driven Design
- Urbanisation, SOA et BPM d’Yves Caseau
Urbanisation, SOA et BPM d’Yves Caseau
Les retours d’expérience d’un Directeur des Systèmes d'Information de grands comptes sont précieux et ne sont pas légions. Le parcours original de l’auteur lui permet d’exposer de manière pédagogique des point de vue de chercheur en architecture distribuée, d’ingénieur d’étude, de consultant en architecture de SI et enfin de DSI pour les aspects opérationnels. Fait assez rare pour ne pas être souligné, on trouve dans cet ouvrage de nombreux exemples concrets tirés de l’expérience à Bouygues Telecom.

Parution : août 2011 - 4ème édition
L'auteur
Yves Caseau possède un CV hors norme, Docteur en informatique (Université Paris-Sud, 1987), Docteur en Philosophie (Ecole normale supérieure, 1987).
Il débute dans la recherche chez Alcatel-Alsthom (1984-1988) puis chez Bellcore (1988-1994).
Il rejoint le groupe Bouygues en 1994 comme directeur du e-Lab.
En 2001, il est nommé CIO (Chief Information Officer) de Bouygues Telecom où il évolue comme vice-président exécutif en 2007.
Auteur et contributeur de nombreux ouvrages, il est, depuis 2012, académicien et président du Collège TIC de l'Académie des Technologies.
En 2014, il est recruté par le groupe Axa pour prendre la responsabilité du pôle digital.
Il entre en 2017 chez Michelin comme CIO du groupe.
Début 2021, toujours CIO de Michelin, il récupère la fonction du digital avec la fonction de CDIO (Chief Digital Officer).
Présentation
Ne vous fiez donc pas à la date de parution qui peut sembler ancienne pour un ouvrage traitant de tels sujets. D’abord parce qu’aucune solution technologique d’intégration n’est évoquée et ensuite parce que l’auteur à eu l’intelligence de prendre de la hauteur sur les questions et les éléments de réponses qui resteront encore pertinents pour longtemps.
A nouveau un livre qui a pour vocation de former à la démarche d’urbanisation. La progression se fait sous forme d'un triptyque : I - Les principes de l’urbanisation ; II - Les défis de l’urbanisation ; III - Perspectives.
I - Les principes de l’urbanisation
La première partie s’adresse aux néophytes, on y trouve les fondements de l’urbanisation du SI. La démarche est présentée comme une transformation progressive du SI intégrant l’existant, s'appuyant sur les processus métier et leur adéquation avec le SI afin d’atteindre flexibilité et évolutivité. Le moyen pour y parvenir est la mise en œuvre d’une architecture distribuée. Le SI urbanisé est basé sur les processus métier de l’entreprise, une structure hiérarchique en sous-systèmes ou les échanges sont standardisés suivant le modèle métier encore appelé langage pivot et enfin sur une architecture ouverte pour l’évolutivité.
L’auteur insiste sur la manière de concevoir la cartographie fonctionnelle où il faut éviter le dogmatisme et la théorisation. L’intermédiation encore appelé proxy permet de découpler les composants grâce aux adapteurs et contribue à la mise en œuvre d’une architecture agile.
Le théoricien s’exprime sur les techniques de modélisation comme sur la réification d’un lien consistant à le représenter par une classe avec des méta attributs comme le degré de fiabilité, la durée de validité, des éléments de preuves, … L’avantage est de pouvoir utiliser l’héritage pour faire évoluer la sémantique du lien au cours des évolutions du modèle.
Le modèle de processus est un espace à 2 dimensions. La dimension horizontale représente les processus transverses et aux domaines fonctionnels de l’entreprise. La dimension verticale identifie des sous-processus masquant par abstraction des niveaux de détails qui ne sont pas nécessaires lorsqu’on étudie les processus dans leur globalité.
Par acquis d’expérience, le postulat principal de l’urbanisation est que l’analyse des processus métier fournit les bonnes interfaces de services. Les processus métier sont des enchaînements de services métiers qui évoluent par recomposition ou re-paramétrage des services mais sans modification des interfaces.
Un des fondamentaux de l’architecture est la diminution du couplage, qui passe, nous rappelle l’auteur par une communication asynchrone entre émetteur et récepteur et par la gestion d’un évènement qui n’est que la réification de l’échange.
II - Les défis de l’urbanisation
La deuxième partie montre l’importance de la conception dans la réalisation d’un SI agile et modulaire. Une modélisation du cycle de vie du SI, met en perspective les avantages et les inconvénients d’un projet d’urbanisation afin d’obtenir le retour sur investissement.
L’auteur nous livre les résultats du ROI d’une étude de Bouygues Telecom ainsi que d'entreprises similaires. A cause de la simplification du calcul des impacts, la phase de spécification/conception peut atteindre un gain de 30 %. Le fait que la logique d’enchaînement ne fasse plus partie du composant logiciel, permet une réduction du développement de 20 %. L’intégration ne dépendant que d’un adaptateur, on économise toutes les connexions du composant avec les autres et ainsi on arrive à diviser le travail par un facteur 3. En ce qui concerne les tests, et plus particulièrement les tests fonctionnels transverses et de non-régression, on peut compter sur un gain de l’ordre de 30 %. Quant à la réutilisation des services, il faut atteindre un niveau maturité correspondant à la réalisation d’un catalogue opérationnel pour avoir un gain substantiel pouvant aller jusqu’à 25 %.
Si cette analyse théorique reste pertinente, elle doit être modulée. En effet la phase de spécification/conception est impactée par le changement de paradigme qu’il faut assimiler, le développement des adaptateurs dépasse les estimations, l’infrastructure d’intégration est un investissement coûteux surtout lors de l'acquisition, du déploiement et de la mise au point.
L’auteur rassure en montrant que la situation est nettement plus positive sur le moyen ou le long terme.
Un des concepts clé de l’ouvrage est l’urbanisation fractale ou comment appliquer les mêmes principes à différentes échelles du SI.
La formalisation de cette récursivité peut s’exprimer de la manière suivante :
- SIU (Système Informatique Urbanisé) = un bus + un moteur de processus + des SIU branchés sur le bus qui rendent des services implémentant les activités des processus
- deux SIU + une passerelle qui joue le rôle de double proxy.
Dans une DSI moderne, l’exploitation est conçue comme un ensemble de services et la DSI signe avec ses clients des contrats de services avec les SLA (Service Level Agreement) servant de base à l'établissement de la tarification.
L’auteur va détailler les solutions de BAM (Business Activity Monitoring), l’exploitation des processus, la gestion des erreurs et donne des solutions aux transactions longues avec le modèle LRA (Long Running Action model).
Enfin différentes approches sont proposées pour la synchronisation de copies d’objets métier distribués.
III - Perspectives
La troisième partie est celle que je préfère. L’auteur donne sa vision de la gouvernance de la SOA, définie par des artefacts de partage d’information, des processus de validation et de mise à jour ainsi que des règles à respecter avec comme artefact principal, le catalogue de services.
Le BPM peut-il tenir ses promesses ? L’échelle de maturité du BPM est discutée en faisant référence à TOGAF et au Club Urba-EA.
Des solutions pour un modèle métier agile comme intégrer l’orienté objet, la méta-modélisation et la généricité.
Avec l’orienté objet on se concentre sur le “quoi” avant le “comment” en décrivant une ontologie des entités métier avant de penser à leur description et sur la réification des rôles dans le SI. Un méta-modèle décrit les entités utilisées pour construire les différents modèles de données, facilitant ainsi la compréhension de la terminologie métier, la comparaison de modèles différents et le transfert comme la migration d’un modèle vers un autre.
La généricité consiste ici à s’abstraire du positionnement de l’entreprise au sein de son industrie et s’imaginer que le modèle de données peut être partagé par d’autres membres de ce même domaine métier.
Les concepts de l’approche SOA sont exposés sans jamais spécifier de technologies comme les Web Services ou plus récemment les Microservices. L’auteur insiste surtout sur les dangers en soulignant que si l’urbanisation contribue à supprimer l’architecture spaghetti, il est par contre très facile de se retrouver avec un réseau de dépendances comme une infrastructure d’intégration mutualisée rendant le système plus rigide.
Toujours sur l’agilité, l’auteur insiste sur le paramétrage permettant des modifications rapides reposant sur des objets métiers et non plus sur des tables et effectuées directement par les domaines métiers. Lors de la refonte du back-office de Bouygues Telecom, l’augmentation du périmètre fonctionnel a augmenté la quantité de paramétrage. Pour éviter cela, il a fallu travailler sur les modèles de données pour augmenter le pouvoir d’abstraction des objets métiers de telle sorte qu’on puisse exprimer plus de choses avec moins de paramètres, ce qui revient presque à urbaniser le paramétrage.
La meilleure agilité consiste à rendre ses utilisateurs autonomes. L’expérience montre que la gestion des données est le plus grand obstacle à l’agilité. En effet lorsque les données n’existent pas, il est impossible de combler un besoin fonctionnel par un développement agile.
L’auteur cite le cas d’un projet qui a coûté 500 K€ pour simplement changer la logique de présentation d’une liste d’options. à cause d’un modèle de données trop pauvre, ce qui est classique et normal, et difficile à enrichir, ce qui est regrettable et évitable.
A l’éternelle question comment augmenter la productivité et diminuer les coûts, l’auteur répond en explorant des évolutions possibles de l’urbanisation.
La première c’est l’automatic computing autrement dit la capacité pour le SI à s’auto-administrer, s’auto-optimiser et à s’auto-gérer.
Ensuite le MDA (Model Driven Architecture) est discuté et si l’auteur le considère comme une source inspirante, il le déconseille car les processus métier sont de plus en plus complexes à réaliser et nécessite une analyse, une conception et des algorithmes tellement spécifiques que leurs générations à partir de modèles de haut niveau ne seraient absolument pas rentables.
Et pour finir, l’OAI (Optimization of Application Integration) consiste à agir en termes de débit, de temps de latence et de disponibilité sur les composants et l’infrastructure. L’objectif est de satisfaire les SLA exprimés sur des processus qui parcourent les composants, en utilisant les mêmes notions de débit, de latence et de disponibilité. A chaque processus est associé une priorité métier propre ainsi qu’une valeur métier puisque le processus est un fil de la chaîne de valeur. Deux problèmes doivent être résolus, le problème statique de satisfaire tous les SLA et le problème dynamique de minimiser la dégradation d’un point de vue métier lorsqu’une situation exceptionnelle se produit. L’OAI repose sur le middleware adaptatif et l’autonomic computing permettant d’obtenir des propriétés de self-configuration, self-optimizing et de self-healing pour la gestion des incidents.
Conclusion
Si comme on l’a dit au début, ce livre reste toujours d’actualité, on arrive à la limite de fraîcheur en ce sens que le Cloud Computing élément incontournable de l’agilité du SI est peu évoqué.
S’il est irréaliste d’imposer un modèle d’urbanisation unique, il n’en demeure pas moins primordial de partager un modèle métier commun, un ensemble de processus transverses, une stratégie d’assemblage, un catalogue de services et une urbanisation fractale.
L'auteur porte un regard global sur l’architecture d’entreprise qui va de la théorie (le pourquoi) à la pratique (le comment) tout en distillant quelques pensées philosophiques au milieu de concepts techniques, on ne s'en plaindra pas.
Le point de vue du DSI
Yves Caseau
Parution : août 2011 - 4ème édition
Collection : InfoPro
Editeur : Dunod
|
|
Rhona Maxwel @rhona_helena |
“On devrait inventer l'alcootest politique, on devrait faire souffler les hommes politiques dans un ballon pour savoir s'ils ont le droit de conduire le pays au désastre”
Coluche
Compléments de lecture
- Le projet d'urbanisation du SI de Christophe Longépé
- Les étapes d'un schéma directeur
- Positionnement des processus et règles métiers dans la norme BMM Business Motivation Model de l’OMG et autres artefacts génériques
- Tutoriel – didacticiel – exemple complet sur la norme de modélisation des règles métiers DMN ( Decision Model Notation ) : Exemple d'exécution du modèle de décisions
- BPMN : processus exécutables, comment s'y prendre ? (3/3)
- CMMN (Case Management Model and Notation) : vie et mort d’une norme de l’OMG (Object Management Group)
- Les fondamentaux de la modélisation d'un Système d'Information : le bon usage des modèles
- SysML pour les nuls : de la modélisation des exigences à la réalisation du système
- Quels sont les meilleurs langages et notations de modélisation pour TOGAF ?
- Les concepts du métamodèle de l’architecture d’entreprise TOGAF (The Open Group Architecture Framework)
- Le processus des itérations ADM (Architecture Development Method), le moteur de la transformation d’entreprise TOGAF (The Open Group Architecture Framework)
Un problème cornélien de l’EDA, Event Driven Architecture, est de s’assurer de l’exactitude sémantique de livraison d’un message, Kafka l’aurait-il résolu ?
Comment gérer l’idempotence de l’envoi d’un même message ?
La non réception d’un accusé signifie que le broker (serveur de messages asynchrones) n’a pas pu écrire le message et dans ce cas il faut que le producteur l’envoie à nouveau ce qui correspond au mode de livraison “au moins un”.
Ou bien le broker l’a bien écrit mais un dysfonctionnement est survenu juste après l'empêchant d’envoyer l’accusé auquel cas le producteur le renverra en double, correspondant au mode de livraison “au plus un”.
Tel est le dilemme cornélien auquel l’EDA est confrontée. Disruptif, l’open source Kafka tente d’apporter des solutions, y parvient-il réellement ?
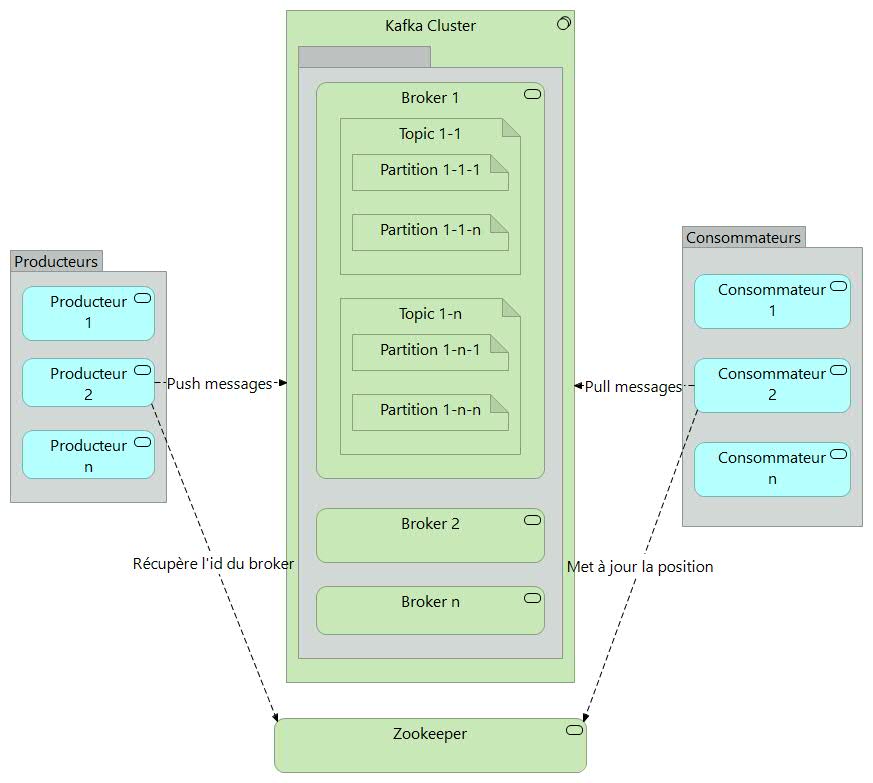
Architecture Apache Kafka
Scénario nominal
Soit une application (producteur) implémentant le processus d’ouverture de dossier de prestation d’assurance qui envoie un message de création d’un nouveau dossier sinistre à un topic (entité Kafka, similaire à un dossier dans un système de fichiers où les événements sont les fichiers de ce dossier).
Supposons maintenant qu’une autre application (consommateur) extrait les données et crée une action dans la corbeille applicative du gestionnaire chargé de créer les nouveaux dossiers sinistres.
Dans une journée idéale, sans dysfonctionnement, le message est écrit exactement une seule fois sur la partition du topic. L’application consommatrice extrait le message, le traite et indique que l’action est terminée. Même si cette application se bloque et redémarre, elle ne recevra pas à nouveau le message.
La probabilité de défaillances des systèmes augmente à forte volumétrie.
Un broker (serveur) peut tomber en panne. Kafka est un système hautement disponible, persistant et durable où chaque message écrit sur une partition est persistant et répliqué..
Mais que se passe-t-il en cas de panne totale ?
La question critique pour un système de traitement de flux est la suivante : "Est-ce que mon application de traitement de flux obtient la bonne réponse, même si l'une des instances tombe en panne au milieu du traitement ? " La clé, lors de la récupération d'une instance défaillante, est de reprendre le traitement exactement dans le même état qu'avant le crash.
Maintenant, le traitement de flux n'est rien d'autre qu'une opération de lecture-traitement-écriture sur un topic Kafka ; un consommateur lit les messages d'un topic Kafka, une logique de traitement transforme ces messages ou modifie l'état maintenu par le processeur, et un producteur écrit les messages résultants dans un autre topic Kafka.
Une opération de lecture-traitement-écriture doit être exécutée exactement une fois.
Dans ce cas, obtenir la bonne réponse signifie ne manquer aucun message d'entrée ou produire une sortie en double. Le comportement qu’attendent les utilisateurs correspond au mode “exactement un” qui garantit qu’un message soit bien délivré, et ce une seule fois.
L'arme fatale : des topics transactionnels
Le journal des transactions est un topic Kafka et fournit les garanties ACID (Atomicité, Cohérence, Isolation et Durabilité).
Le moniteur transactionnel, qui gère l'état de la transaction par producteur, s'exécute au sein du broker et en cas de panne, s'appuie naturellement sur l'algorithme d'élection du système maître de Kafka qui gère les réplications.
Pour les applications de traitements de flux créées à l'aide de l'API Streams, Kafka tire parti du fait que le référentiel d'états et des positions dans le journal sont des topics Kafka.
Ces données sont embarquées de manière transparente dans des transactions qui écrivent de manière atomique sur plusieurs partitions, et qui fournissent la garantie de les traiter exactement une fois pour les flux, à travers les opérations de lecture-traitement-écriture.
Des tests de chaos distribués ont été réalisés dans un cluster Kafka complet avec plusieurs clients transactionnels. Des messages ont été produits de manière transactionnelle, puis lus simultanément, tandis que les les clients et les serveurs étaient arrêtés pendant le processus afin de s’assurer que les données n’étaient ni perdues ni dupliquées.
Les différentes garanties de livraison de message
- Au plus une fois : les messages peuvent être perdus mais ne sont jamais redistribués.
- Au moins une fois : les messages ne sont jamais perdus mais peuvent être renvoyés.
- Exactement une fois : c'est ce que l’on veut réellement, chaque message est délivré une fois et une seule.
A noter que cela se décompose en deux problèmes : les garanties de pérennité pour la publication d'un message et les garanties lors de la consommation d'un message.
La plupart des systèmes fournissent une sémantique de livraison "exactement une fois",
mais ne gèrent pas le cas où les consommateurs ou les producteurs peuvent tomber en panne, les cas où il y a plusieurs processus consommateurs ou encore les cas où les données écrites sur disque peuvent être perdues.
Stratégies mise en œuvre côté producteur
Lors de la publication d'un message, une information est commitée dans le journal. Une fois qu'un message publié est validé, il ne sera pas perdu tant qu'un broker qui réplique la partition sur laquelle ce message a été écrit reste actif.
Si un producteur tente de publier un message et rencontre une erreur réseau, il ne peut pas être sûr si cette erreur s'est produite avant ou après la validation du message.
Pour de nombreux systèmes, si un producteur ne reçoit pas de réponse indiquant qu'un message est validé, il n'a d'autre choix que de renvoyer le message. Cela fournit une sémantique de livraison “au moins une fois” puisque le message peut être réécrit dans le journal lors du renvoi si la demande d'origine a en fait réussi.
Avec Kafka, le producteur prend en charge une option de livraison idempotente qui garantit que le renvoi n'entraînera pas d'entrées en double dans le journal. Pour ce faire, le broker attribue à chaque producteur un identifiant et déduplique les messages à l'aide d'un numéro de séquence envoyé par le producteur avec chaque message.
Le producteur prend également en charge la possibilité d'envoyer des messages à plusieurs partitions de topic en utilisant un système de transaction : c'est-à-dire, soit tous les messages sont écrits avec succès ou soit aucun d'entre eux ne l'est. Le principal cas d'utilisation pour cela est la sémantique de traitement “exactement une fois” entre les topics Kafka.
Des options permettent au producteur de spécifier le niveau de durabilité qu'il souhaite. Cependant, le producteur peut également spécifier qu'il souhaite effectuer l'envoi de manière complètement asynchrone ou qu'il souhaite attendre uniquement que le système primaire (maître) ait le message, mais pas nécessairement les systèmes secondaires.
Stratégies mise en œuvre côté consommateur
Toutes les répliques ont exactement le même journal avec les mêmes positions. Le consommateur contrôle sa position dans ce journal. Si le consommateur n’a jamais subi de pannes, il pourrait simplement stocker cette position en mémoire, mais si le consommateur échoue et que cette partition de topic doit être prise en charge par un autre processus, celui-ci devra choisir une position appropriée à partir de laquelle commencer le traitement.
Si par exemple, le consommateur lit certains messages, il dispose de plusieurs options pour traiter les messages et mettre à jour sa position.
Il peut lire les messages, puis enregistrer sa position dans le journal, et enfin traiter les messages. Dans ce cas, il est possible que le processus consommateur se bloque après avoir enregistré sa position mais avant d'avoir enregistré la sortie de son traitement de message. Dans ce cas, le processus qui a repris le traitement commencera à la position enregistrée même si quelques messages antérieurs à cette position n'avaient pas été traités. Cela correspond à la sémantique "au plus une fois" car dans le cas d'une panne du consommateur, les messages peuvent ne pas être traités.
Il peut lire les messages, traiter les messages et enfin enregistrer sa position. Dans ce cas, il est possible que le processus consommateur se bloque après avoir traité les messages mais avant d'avoir enregistré sa position. Dans ce cas, lorsque le nouveau processus prendra le relais, les premiers messages qu'il recevra auront déjà été traités. Cela correspond à la sémantique "au moins une fois" en cas de défaillance du consommateur. Dans de nombreux cas, les messages ont une clé primaire et les mises à jour sont donc idempotentes ce qui signifie que deux réceptions du même message, écrase simplement un enregistrement avec une autre copie de lui-même..
Le mode "exactement un"
Lors de la consommation à partir d'un topic Kafka et de la production vers un autre topic (comme dans une application Kafka Streams), les nouvelles fonctionnalités de producteur transactionnel entrent en action.
La position du consommateur est stockée sous forme de message dans un topic, on peut donc écrire la position dans Kafka dans la même transaction que les topics de sortie recevant les données traitées. Si la transaction est abandonnée, la position du consommateur reviendra à son ancienne valeur et les données produites sur les topics de sortie ne seront pas visibles pour les autres consommateurs qu'en fonction de leur "niveau d'isolement".
Dans le niveau d'isolement par défaut "read_uncommitted", tous les messages sont visibles pour les consommateurs même s'ils faisaient partie d'une transaction abandonnée, mais dans "read_committed", le consommateur ne renverra que les messages des transactions qui ont été validées et tous les messages qui ne faisaient pas partie d'une transaction.
Commit à 2 phases pour les systèmes externes
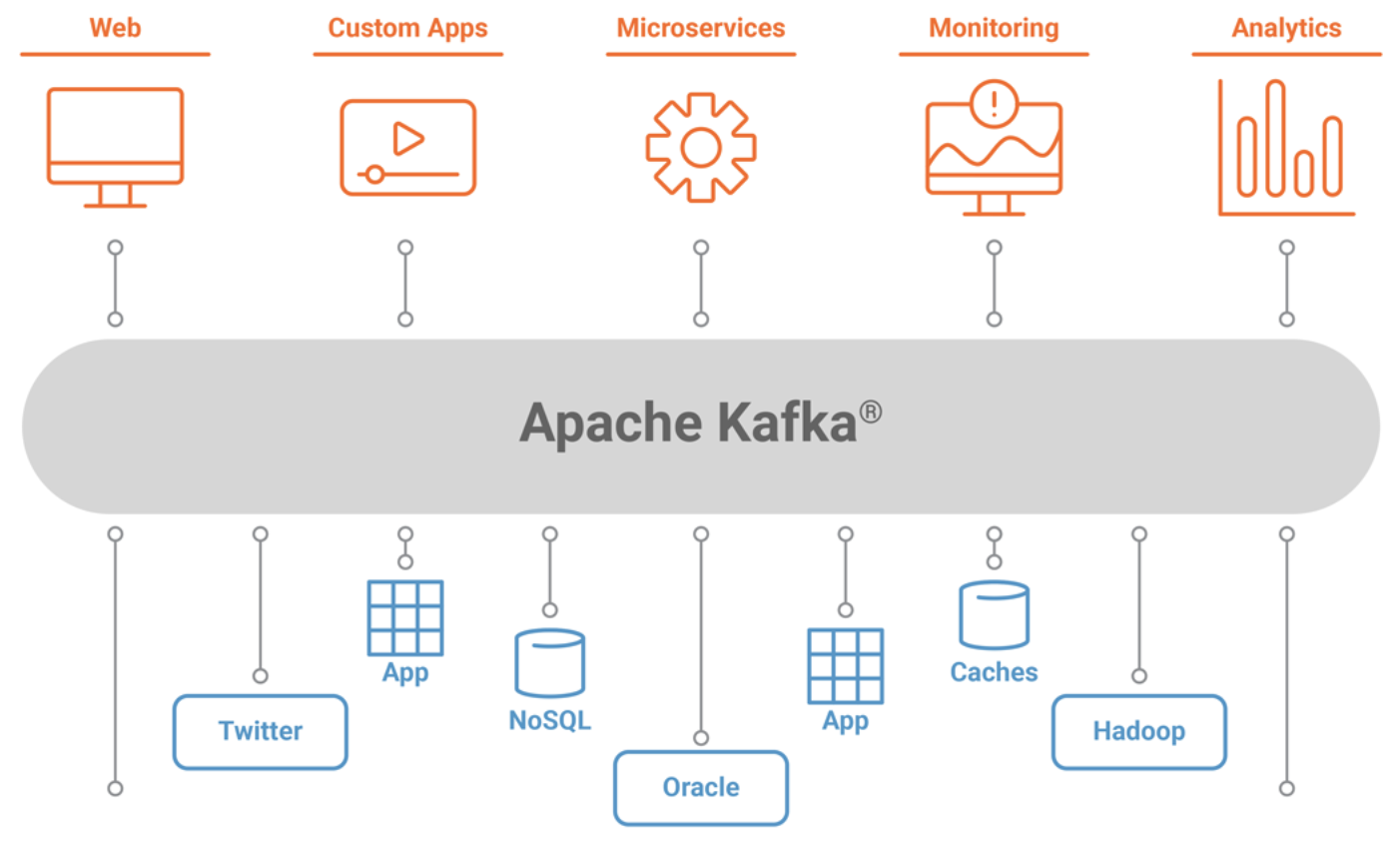
Exemples de connecteurs Kafka Connect
Lors de l'écriture sur un système externe, la limitation réside dans la nécessité de coordonner la position du consommateur avec ce qui est réellement stocké en tant que sortie. La manière classique d'y parvenir serait d'introduire un commit à deux phases entre le stockage de la position du consommateur et le stockage de la sortie du consommateur.
Mais comme de nombreux systèmes de sortie sur lesquels un consommateur peut vouloir écrire ne prennent pas en charge un commit à deux phases, il est préférable de laisser le consommateur stocker sa position au même endroit que sa production.
Par exemple, un connecteur Kafka Connect qui remplit les données dans HDFS (Hadoop Distributed File System, est un système de stockage faisant partie de Apache Hadoop, le framework open source standard utilisé dans le Big Data), avec les positions des données qu'il lit afin de garantir que les données et les positions sont tous les deux mis à jour ou qu'aucun ne l'est.
Conclusion
Le support complet des transactions par le producteur et le consommateur lors du transfert et du traitement des données entre les topics Kafka, permet d’assurer la livraison en mode “exactement un” qui garantit qu’un message soit bien délivré, et ce une seule fois, le dilemme cornélien exposé en début de cet article est donc résolu.
A part la spécificité fondamentale précédente, voici les autres critères discriminants par rapport aux produits classiques de l’EDA comme ActiveMQ et RabbitMQ :
- supporte des débits très importants
- système de messagerie en mode “pull”, le consommateur extrait les messages du broker
- conserve les messages sur une durée paramétrable
- un consommateur peut rembobiner vers une ancienne position et re-consommer les données
- fonctionnalité de compactage
- Kafka Streams apporte la possibilité d’effectuer des traitements parallélisés sur des messages en flux continus
- de nombreux connecteurs, basés sur Kafka Connect, permettent de transférer facilement de gros volumes de données en provenance ou vers de multiples systèmes
- possibilité de capturer tous les événements impliquant un changement d’état d’un composant du SI
Ces innovations par rapport à l’existant montre bien que Kafka a le potentiel d’une technologie de rupture. Et en tant que tel, il pourrait bien contribuer au développement de l’EDA comme l’indique Forrester dans ses prévisions pour 2022.
|
|
Rhona Maxwel @rhona_helena |
“La jeunesse est heureuse parce qu'elle a la capacité de voir la beauté. Quiconque conserve la capacité de voir la beauté ne vieillit jamais.”
Franz Kafka
Compléments de lecture
- Les couches de l'Architecture Microservices et la méthode de conception DDD (Domain Driven Design)
- Architecture Hexagonale, exemple de mise en pratique de la méthode DDD Domain Driven Design
- L’Architecture Micro-Services expliquée à ma fille
- Inconvénients de l'Architecture Micro-Services
- Orchestration des micro-services avec BPMN
- Conseils pour réussir vos micro-services et éviter qu’ils ne se transforment en véritable pensum
- Estimation de la complexité d’une Architecture Micro-Services
- Solutions sur étagère pour la gestion des défaillances des Micro-Services
- Comment éviter la loi de Conway et faciliter ainsi l’agilité avec l’approche Micro-Services ?
- Les couches de l'Architecture Microservices et la méthode de conception DDD (Domain Driven Design)
- Le projet d'urbanisation du SI de Christophe Longépé
Architecture Hexagonale, exemple de mise en pratique de la méthode DDD Domain Driven Design
L'architecture hexagonale (ou encore Ports & Adapters Architecture, ce qui est moins sexy) créée par Alistair Cockburn garantit la réutilisabilité de la logique métier, en la rendant agnostique techniquement.

(Diagramme de Composants UML pour l'illustration de l'Architecture Hexagonale, réalisé avec l’outil commercial Enterprise Architect de Sparx Systems https://sparxsystems.com/ Les composants du domaine implémentent les interfaces des API métiers et utilisent les interfaces des SPI de persistance).
Présentation
Chris Richardson, dans son article (en anglais) Jfokus: Cubes, Hexagons, Triangles, and More: Understanding Microservices, explique les pictogrammes métaphoriques utilisés pour marketer les sujets qu'il aborde. Dans la pseudo science des logos, l’hexagone symbolise le travail, la rigueur, l’effort collectif, le réseau, la structure sociale et enfin l'organisation.
Avec UML ou ArchiMate, point d'élément de modélisation hexagonal ! Une vue d'artiste assez commune, montrant l'hexagone, se trouve à la fin de cet article.
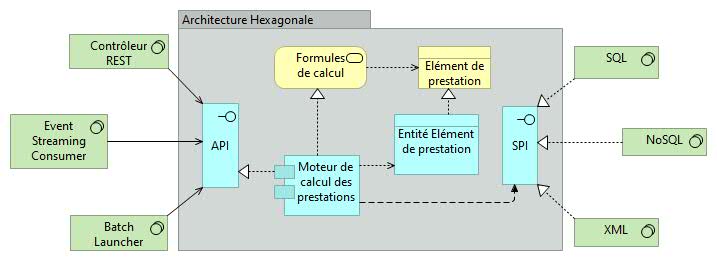
Le domaine est isolé du monde extérieur par l'intermédiaire d'API (Application Programming Interface) et de SPI (Service Provider Interface) qui sont représentées par des interfaces.
Seulement deux mondes existent : à l'intérieur, toute la logique métier et à l'extérieur, l'infrastructure technique.
Les dépendances vont toujours de l'extérieur vers l'intérieur de l'hexagone.
L'implémentation du domaine métier est indépendante de tous les autres aspects techniques comme la présentation, la gestion des protocoles de communication, les flux de messages, les moyens de persistance des entités métier, y compris des frameworks intrusifs obligeant à inclure du code technique.
Un corollaire de ceci est que le domaine métier ne dépend que de lui-même.
Description
Un concept clé de cette architecture est donc de mettre toute la logique métier dans un seul endroit nommé le domaine (hexagone), qui ne dépend que de lui-même ; c'est le seul moyen de s'assurer que la logique métier est découplée des couches techniques.
On y parvient en utilisant l'inversion du contrôle correspondant au "D (Dependency Inversion Principle)" des principes connus sous le nom de “SOLID” de Robert C. Martin ou Uncle Bob (voir son article en anglais : Solid Relevance), base de l’orienté objet, mais aussi de l’organisation structurelle de l’urbanisation des SI.
A noter que certains praticiens ont théorisé d’autres recommandations spécifiques aux microservices, comme celles de Paulo Merson, voir son article (en anglais) : Principles for Microservice Design: Think IDEALS, Rather than SOLID.
Bon nombre d'entreprises intègrent l'hexagone dans leurs logos pour symboliser l'organisation et le travail comme une ruche d'abeilles.
Puisque les problèmes d'intégration sont traités à part, la testabilité du domaine métier est augmentée.
De vrais tests fonctionnels sont enfin possibles grâce à cette contrainte de l'Architecture Hexagonale, car ils vont interagir directement avec le domaine métier et uniquement avec lui.
L'extérieur de l'hexagone (l'infrastructure) est divisé en deux parties virtuelles, le côté gauche et le côté droit :
- A gauche, se trouve tout ce qui va interroger le domaine (le contrôleur, les couches REST, Event Streaming, Batch Launcher, etc.),
- A droite, tout ce qui va fournir des informations/services au domaine (couche de persistance SQL ou NoSQL, services tiers, etc.).
Pour laisser l'extérieur interagir avec le domaine, le domaine propose des interfaces ou ports divisés en deux catégories :
- L'API fournit toutes les interfaces pour tout ce qui doit interroger le domaine. Ces interfaces sont implémentées à l’intérieur du domaine,
- Le SPI regroupe toutes les interfaces requises par le domaine pour récupérer des informations auprès de tiers. Ces interfaces sont utilisées dans l'hexagone et implémentées par la partie droite de l'infrastructure.
L'API et le SPI font partie de l'Hexagone. L'API et le SPI ne manipulent que les objets métier du domaine de l'Hexagone. Ils assurent en effet l'isolement.
Dans une architecture en couches, l'objet métier ou le service crée généralement les DAO (Data Access Object). Dans l'architecture hexagonale, le domaine ne gère que les objets de domaine. Par conséquent, la persistance se charge de traduire les objets du domaine en « DAO » à persister et utilise pour cela des adaptateurs.
Modèle UML
Dans le diagramme UML de composants ci-dessus, l'API et le SPI sont les ports ; les modules d'infrastructure, qui les implémentent ou les utilisent, sont les adaptateurs, d'où l'autre appellation plus technique de Ports & Adapters Architecture.
Pour cette raison, nous pensons que le langage de modélisation le plus approprié pour l'architecture Hexagonale est la norme UML, avec le diagramme de composants permettant visuellement de mieux représenter les connexions entre les ports (prises) correspondant aux interfaces fournies et ceux correspondants aux interfaces requises.
Modèle ArchiMate
(Modèle ArchiMate réalisé avec l’outil open source Archi de Phil Beauvoir et Jean-Baptiste Sarrodie de l’Open Group ArchiMate Forum https://www.archimatetool.com/)
Changer les technologies n'a aucun impact sur le code du domaine. Cette architecture est parfaitement conforme à la méthode de conception DDD (Domain Driven Design) abordée dans notre article Les couches de l'Architecture Microservices et la méthode de conception DDD (Domain Driven Design).
Intérêts
L'avantage majeur que présente cette architecture vient de sa modularité. Parce que tout est découplé, une couche REST et l'Event Streaming peuvent coexister simultanément sans aucun impact sur le domaine métier.
Du côté SPI, une migration de SQL vers NoSQL est grandement facilitée. Étant donné que le SPI ne changera pas parce qu'on modifie la méthode de persistance, le reste de l'application ne sera pas affecté.
Limites
Toutefois, l'architecture hexagonale ne convient pas systématiquement à toutes les situations. De la même manière que pour le Domain Driven Design, elle ne s'applique réellement qu'à un domaine métier consistant. Il est déconseillé de la mettre en œuvre pour une application transformant juste des données dans un autre format, par exemple.
Exceptions
Le domaine doit être complètement exempt de toutes technologies, sauf, et c’est l’exception qui confirme la règle, celles qui auraient un très faible impact sur le domaine métier, par exemple un gestionnaire de logs et de traces, comme indiqué dans notre article sur le DDD (Les couches de l'Architecture Microservices et la méthode de conception DDD (Domain Driven Design)).
Méthode de conception
Une équipe de développeurs (la “two-pizza team” popularisée par Jeff Bezos) doit :
- Commencer par l'intérieur de l'hexagone,
- Se concentrer sur la fonctionnalité, plutôt que sur les détails techniques,
- Retarder les choix sur la mise en œuvre technique. Parfois, il est difficile de savoir de quelle implémentation technique on a besoin au début. Par conséquent, retarder ce choix aide à se concentrer sur ce qui apporte de la valeur à l’entreprise : la fonctionnalité.
De plus, après la mise en place de la logique métier, de nouveaux éléments peuvent aider à faire le meilleur choix concernant l’infrastructure.
Cela garantit que l'hexagone est autonome et qu’il est auto-testé avec de vrais tests fonctionnels centrés sur le métier uniquement. Ces tests appellent directement l'API du domaine en évitant toute perturbation de la partie technique. Un adaptateur est créé, simulant le contrôleur pour tester les fonctionnalités du domaine.
Conclusion
Le réel avantage à découpler la logique métier du code technique, c’est de garantir que le domaine d'activité est durable et robuste, face à l'évolution continue de la technologie.
En résumé, les caractéristiques de l'Architecture Hexagonale :
- Mettre toute la logique métier en un seul endroit,
- Le domaine est isolé et agnostique sur la partie technique, car il ne dépend que de lui-même,
- Les dépendances vont toujours de l'extérieur vers l'intérieur de l'Hexagone,
- L'Hexagone est un module autonome. Ainsi, il augmente la testabilité du domaine en écrivant de vrais tests fonctionnels qui n'ont pas à traiter de problèmes techniques,
- Cette architecture offre une modularité puissante. Il aide à écrire autant d'adaptateurs que nécessaire avec un faible impact sur le reste du logiciel. Et comme le domaine est indépendant des technologies, elles peuvent être modifiées sans aucun impact sur l'entreprise,
- En commençant toujours par le domaine, les développeurs assurent d'apporter de la valeur au client en se concentrant sur le développement des fonctionnalités. De cette façon, ils peuvent retarder les choix de mise en œuvre technique, pour faire le meilleur choix au bon moment.
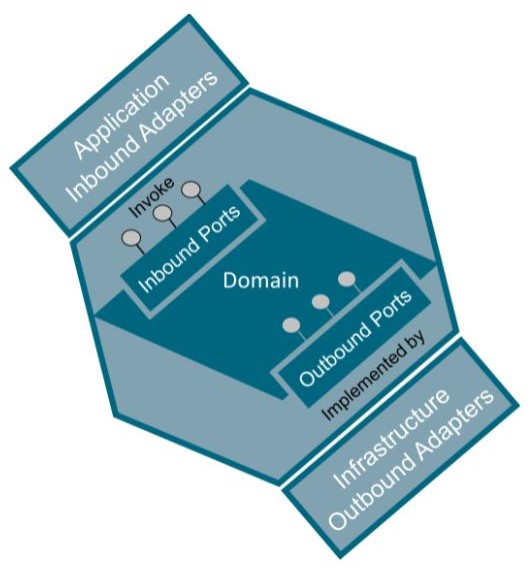
Et pour terminer, voici à mon avis la meilleure vue d'artiste, issue de l'Open Group (https://publications.opengroup.org/), désolée Alistair et Chris.
|
|
Rhona Maxwel @rhona_helena |
“Aimer savoir est humain, savoir aimer est divin”
Joseph Roux
Compléments de lecture
- L’Architecture Micro-Services expliquée à ma fille
- Inconvénients de l'Architecture Micro-Services
- Orchestration des micro-services avec BPMN
- Conseils pour réussir vos micro-services et éviter qu’ils ne se transforment en véritable pensum
- Estimation de la complexité d’une Architecture Micro-Services
- Solutions sur étagère pour la gestion des défaillances des Micro-Services
- Comment éviter la loi de Conway et faciliter ainsi l’agilité avec l’approche Micro-Services ?
- Les couches de l'Architecture Microservices et la méthode de conception DDD (Domain Driven Design)
Essai et évaluation de Modelio : est-il un bon outil de modélisation ?
Ce test concerne Modelio, le seul outil open source fonctionnant sur Windows, Linux, Mac OS, supportant ArchiMate, TOGAF, BPMN, UML, SysML, MDA et offrant, pour tous ces artefacts de modélisation, un référentiel commun assurant la traçabilité depuis la stratégie jusqu’à la couche technologique. Mais est-il fiable en usage intensif dans les entreprises ou doit-il être plutôt réservé à l’apprentissage de la modélisation ?

Sur le store, on trouve des extensions gratuites : import/export Excel, générateur de code Java et reverse engineering Java en UML, concepteur de patterns, modélisateur de base de données SQL… Malheureusement le module collaboratif est payant. https://store.modelio.org/
Installation
Ici, point de SaaS, mais une application on premise qui se télécharge à partir du site https://www.modelio.org/ en fonction de l’OS cible. Des utilisateurs de Mac nous ont avertis que des dysfonctionnements sans gravité étaient survenus pendant l’installation. La version installée est en français. La désinstallation ne laissera aucune trace sur votre machine.
Modelio open source est gratuit et sous licence GNU GPL (General Public License). Il est développé par Softeam, une filiale de Docaposte, société de conseils en transformation numérique. Développé en Java, il est basé sur Eclipse, qui est un environnement de production de logiciel libre, extensible, universel et polyvalent.
Les habitués d’Eclipse retrouveront le système de personnalisation redessinant entièrement l’écran, basé sur les perspectives regroupant un certain nombre de vues déjà prédisposées : Gestion des projets, Modèle, ArchiMate, Diagramme, Développement et une dernière perspective globale.
Si Modelio gère bien un référentiel d’objets d’entreprise, il ne permet pas de le partager entre plusieurs utilisateurs autorisés. On peut juste exporter le projet pour le transmettre à un autre utilisateur qui pourra l’importer.
N’importe quel objet d’entreprise, sous n’importe quel formalisme parmi ceux cités précédemment, peut être intégré dans un diagramme et être lié à un autre par des liens de traçabilité. Un projet doit être créé, qui contiendra automatiquement un package dans lequel, on peut créer un diagramme. Modelio propose alors les diagrammes BPMN et UML.

L’ensemble des diagrammes UML/BPMN supportés par Modelio
Sur les 13 diagrammes de la norme UML 2, 10 sont présents, les diagrammes : Timing Diagram, Interaction Overview Diagram sont absents de la liste, il est vrai que leur utilisation est beaucoup plus rare. Le "Component Diagram" avec les interfaces fournies et requises, indispensables pour la modélisation d’architecture distribuée SOA, se trouve dans la toolbox du diagramme de classe, nous trouvons ce choix un peu surprenant, car c'est bien un diagramme à part entière de la norme UML de l'OMG.
ArchiMate
Mais où est passé ArchiMate, promis sur le site ?

Ajout gratuit du plugin Modelio ArchiMate
Pour installer ArchiMate, il faut aller dans le menu Aide, puis dans Page d’accueil, on apprend que l’on peut télécharger le support d’ArchiMate gratuitement et c’est une nouveauté. Une alerte de sécurité s’affiche, et l’on est redirigé sur le site commercial Modeliosoft qui propose le téléchargement pour les 3 OS du marché.
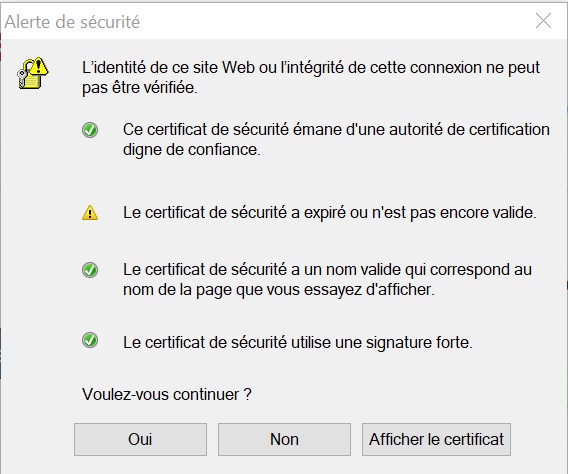
Quelques messages d'alertes plus tard, l'installation s'est bien déroulée
Si l’on a échappé jusque-là au traditionnel formulaire à remplir, aucune issue, il vous faudra bien consacrer un peu de temps à la saisie des informations habituelles pour obtenir le module convoité.
Fermer Modelio avant de lancer l’installateur que vous venez de télécharger. Rouvrez le projet créé précédemment, clic droit sur le projet ArchiMate, allez dans Sous-projets puis Sous-projet ArchiMate.
Très surprenant, les couches d’architecture sont classées par ordre alphabétique et non pas dans l’ordre habituel comme le font tous les autres outils à savoir : Strategy, Business, Application, Technology & Physical, Motivation, Implementation & Migration. Impossible de les déplacer, malgré la présence de flèches haut et bas qui restent désespérément grisées.
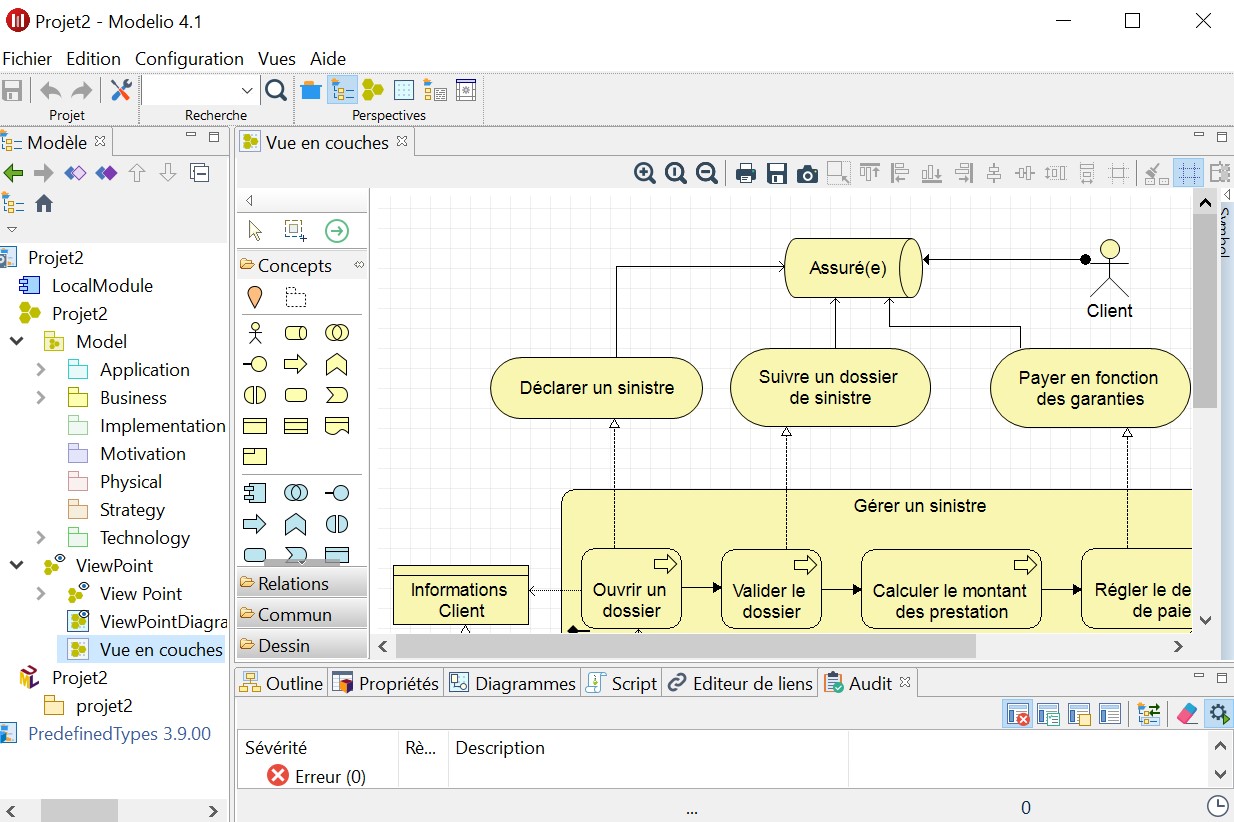
Test du module gratuit ArchiMate
Pour avoir l’affichage d’un élément en icône ou en symbole complet, il faut faire apparaître la fenêtre Symbole sur le côté droit, sélectionner l’élément dans le diagramme, puis dans la propriété Mode de représentation, cliquer sur Simple ou Structuré.
On trouve les fonctionnalités standards des autres outils du marché, rangement automatique des éléments dans leur niveau d’architecture, zoom, options d’affichage, éditeur de liens, audit pour les erreurs et les conseils.
L’outil vérifie la conformité avec le méta-modèle ArchiMate. Cela se concrétise par un encadré rouge et un panneau interdit sur l’élément cible lorsqu’on tente de le relier à un autre élément avec un lien dont la sémantique ne correspond pas à leur nature. Malheureusement, lors de la sélection d’un élément, on regrette qu’il n’y ait pas comme dans l’outil Archi (https://www.archimatetool.com/), une aide qui s’affiche rappelant la définition détaillée, la catégorie et des exemples.
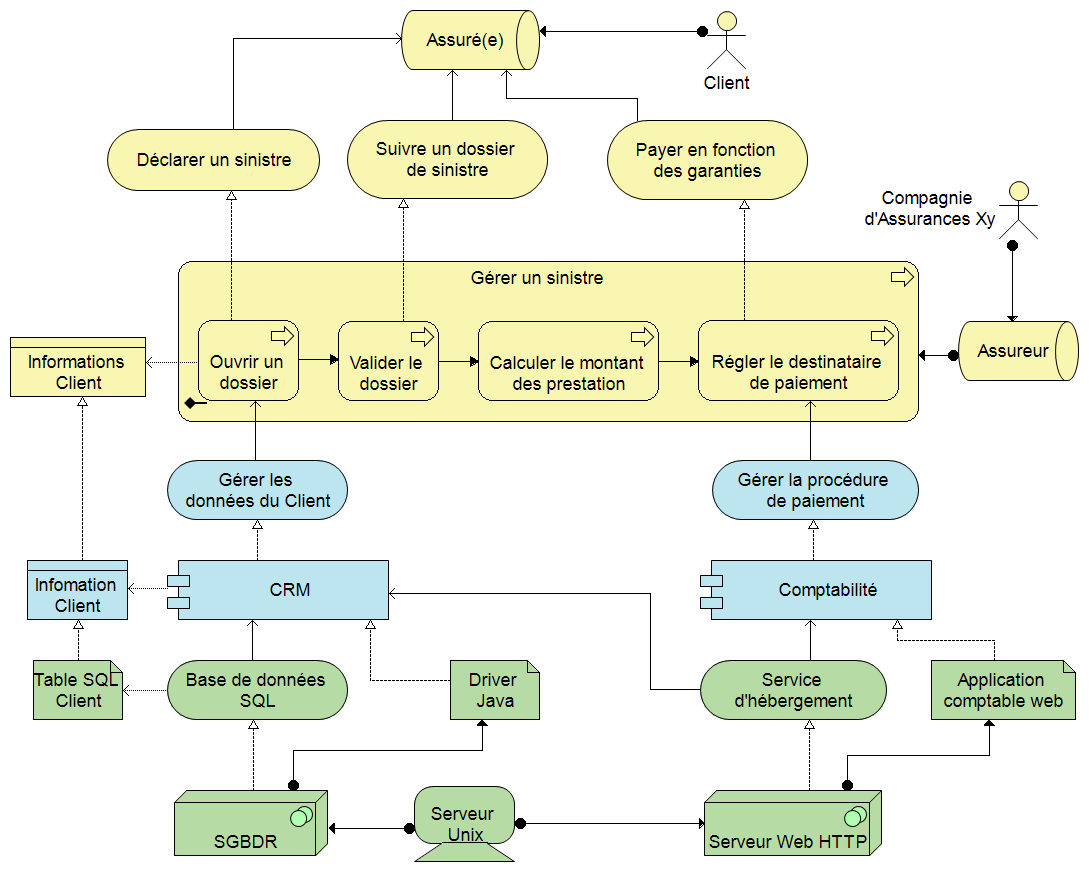
Vue des couches d’architecture métier, applicative et technologique
d’un processus de prestation d’assurance
BPMN
La procédure n’est pas des plus simples.
Créez un Diagramme de collaboration BPMN dans le package du sous-projet avec l’icône UML regroupant ces 2 notations comme vu précédemment.
Dans ce diagramme, créez par exemple 2 processus qui seront créés spécifiquement par ailleurs.
Ouvrez l’icône d’un processus, puis en cliquant sur l’icône de diagramme, vous aurez accès à la toolbox avec l’ensemble des artefacts BPMN.
Mais il est alors impossible de modifier le diagramme de collaboration, on est obligé de faire des allers-retours dans chacun des diagrammes de processus, ce qui devient très vite fastidieux.
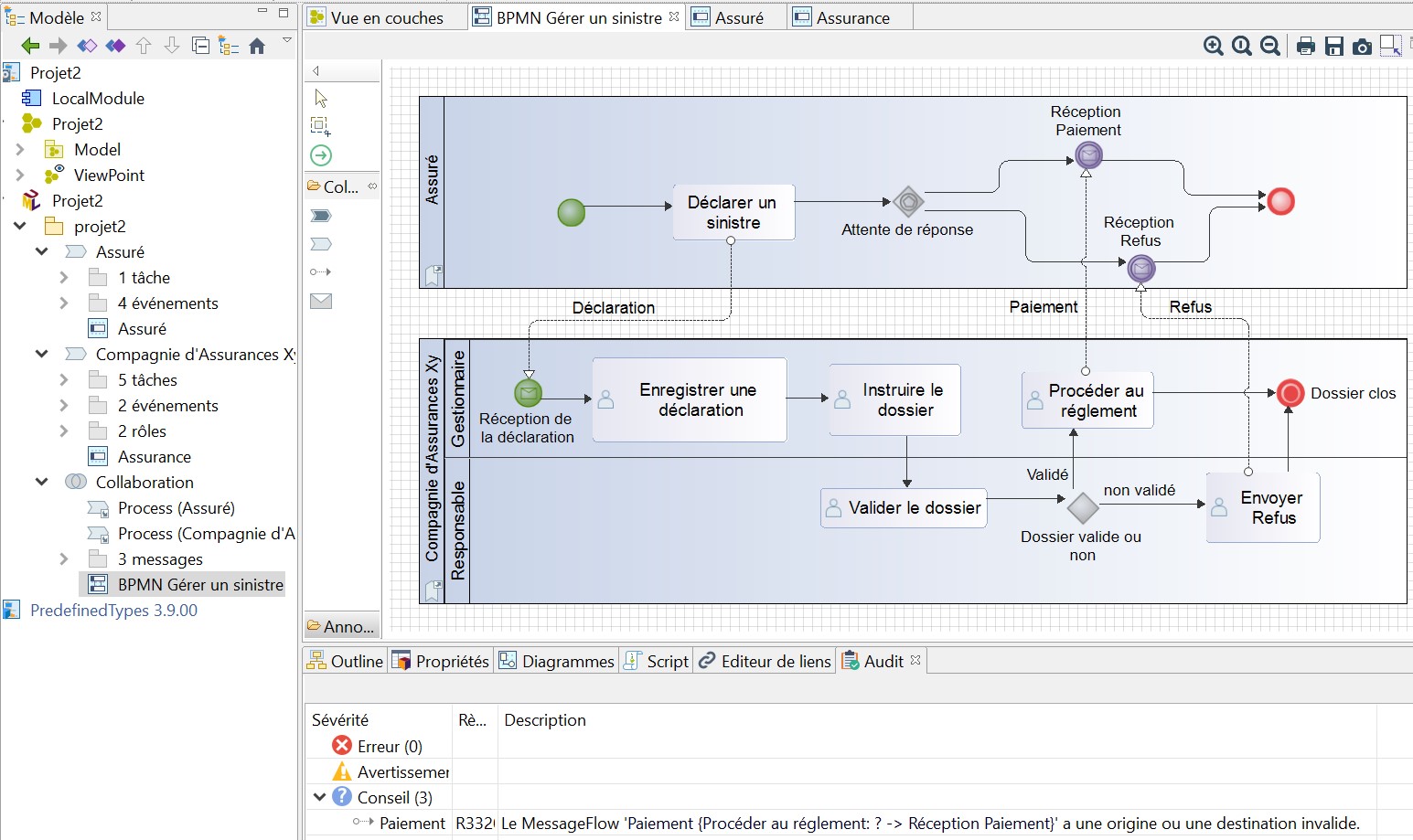
Modélisation BPMN d’un processus de prestation d’assurance
L’ergonomie pourrait être améliorée, par exemple on ne peut pas changer la nature d’une tâche (sans, user, manual…) : on est obligé de la supprimer puis de la recréer en la modifiant.
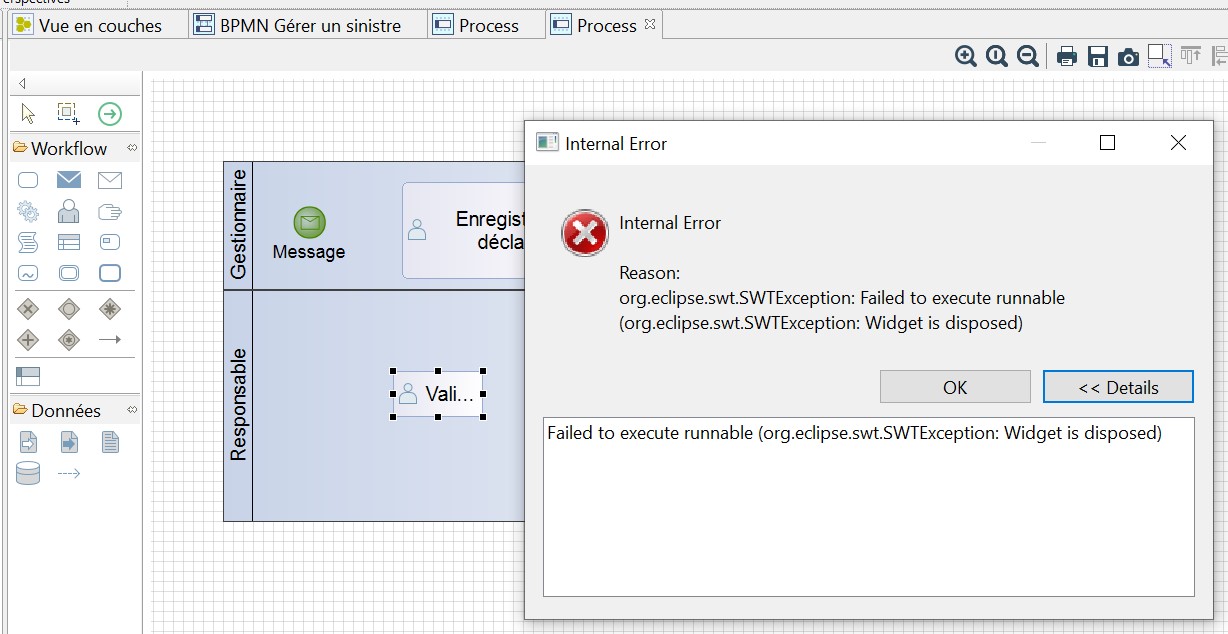
Au cours de la conception de notre BPMN, nous avons rencontré plusieurs erreurs internes, heureusement sans impact visible
En cas de non-respect d’une règle de la norme BPMN, une erreur ou un avertissement est généré. L’explication s'affiche en français, une correction est même proposée.
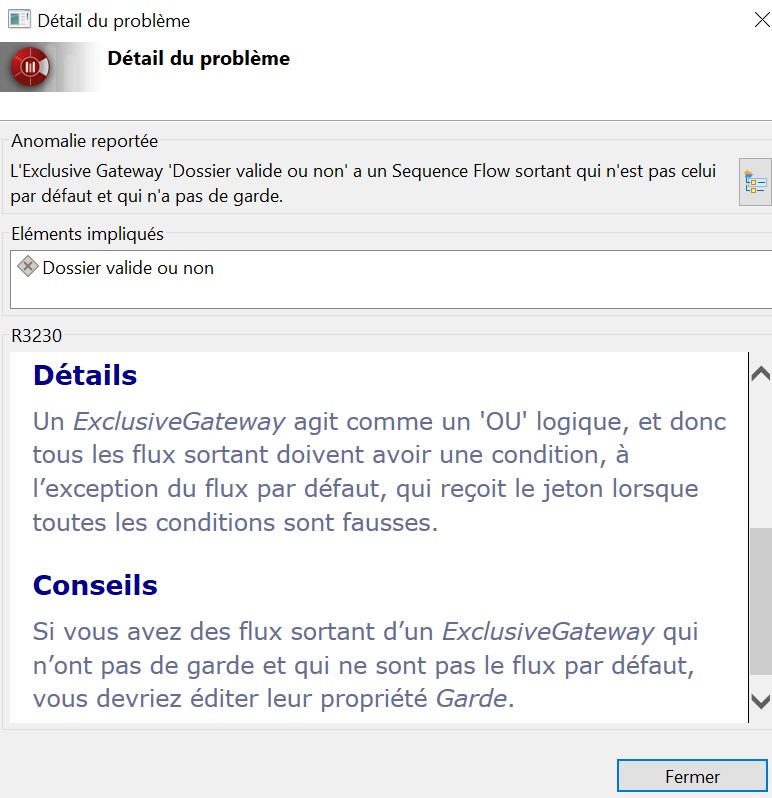
Détails et conseils sur une erreur BPMN
Modelio va encore plus loin en ajoutant des conseils et des bonnes pratiques sur les points ambigus de la norme. Ces fonctionnalités permettent de mieux assimiler les concepts BPMN et procurent donc un gros avantage pédagogique.
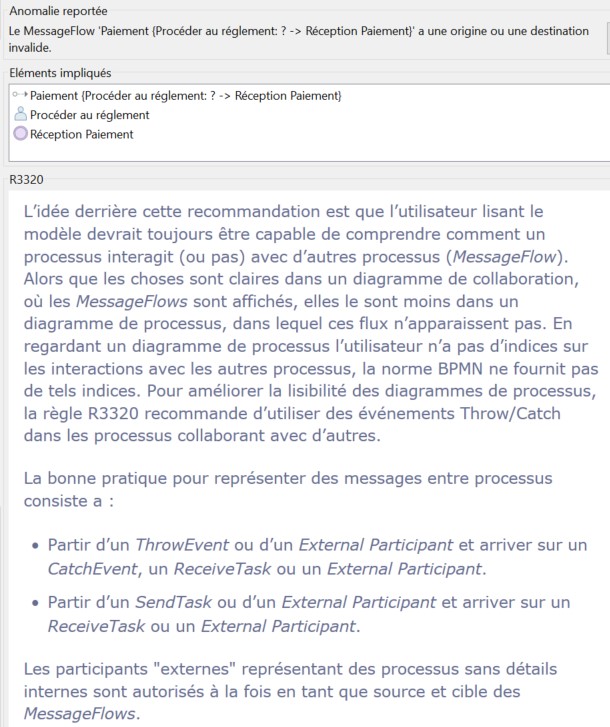
Les bonnes pratiques de Modelio pour lever les ambiguïtés laissées par la norme BPMN
En sélectionnant le diagramme BPMN de collaboration, on peut créer un pattern à partir du modèle, puis l’exporter afin qu’il soit réutilisable pour créer un autre modèle.

Si l’on a pu créer un pattern à partir de notre modèle BPMN,
quand on a voulu l'exporter, on a eu une erreur bloquante
UML
Diagramme de cas d’utilisation
Dans un diagramme de cas d’utilisation UML, nous avons récupéré à partir du référentiel commun, des objets processus métier ArchiMate comme des rôles métier ArchiMate, des objets BPMN comme des user tasks BPM, ainsi que des lanes BPMN représentant les rôles métier.
Le processus métier ArchiMate peut être lié au processus BPMN, les user tasks BPMN aux use cases UML, de même que les rôles ArchiMate peuvent liés aux lanes BPMN, elles-mêmes liées aux acteurs des use cases.
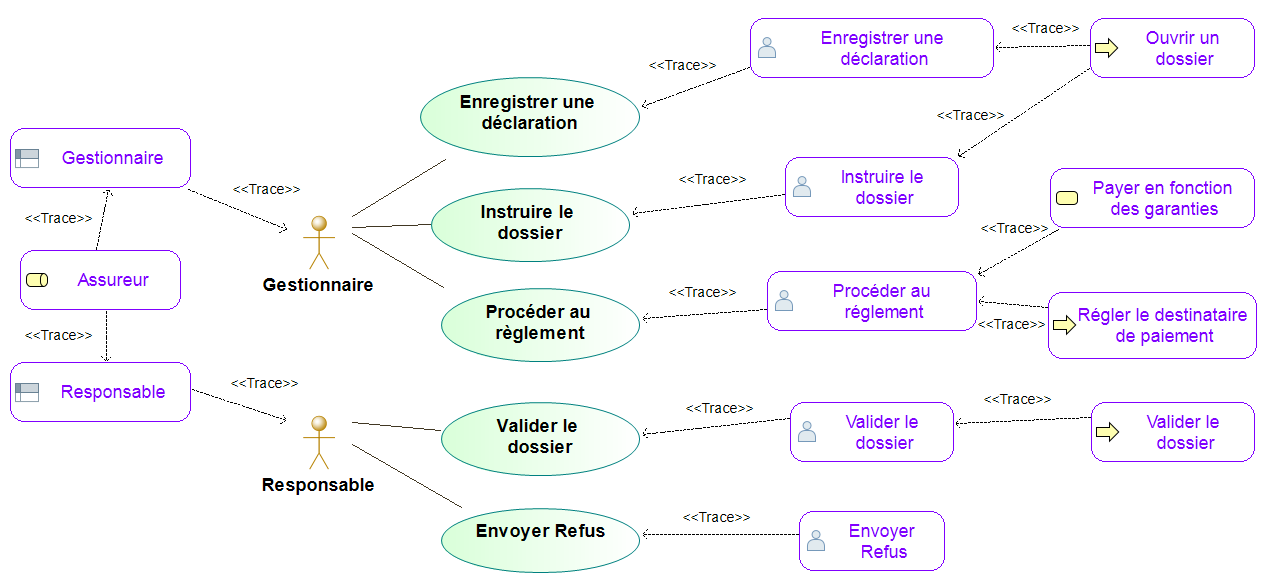
Traçabilité entre objets de modélisation stockés dans le référentiel commun
et provenant de différentes notations
Modelio propose une vue “Editeur de liens” montrant, quand on sélectionne un objet dans le référentiel, tous les endroits où il apparaît, l’ensemble des objets auxquels il est lié, quel que soit le formalisme de modélisation.

La vue “Editeur de liens” pour la traçabilité des objets de l’entreprise

Zoom sur les liens et les potentielles transformations entre par exemple
un sous-processus ArchiMate lié à un "User Task" BPMN et enfin à un "Use Case" UML
Diagramme de classe
La norme UML du diagramme de classe est bien respectée et la réalisation d'un modèle ne pose aucun problème.
Dans la toolbox du diagramme de classe, nous trouvons les éléments de modélisation pour les composants, les interfaces fournies et requises.
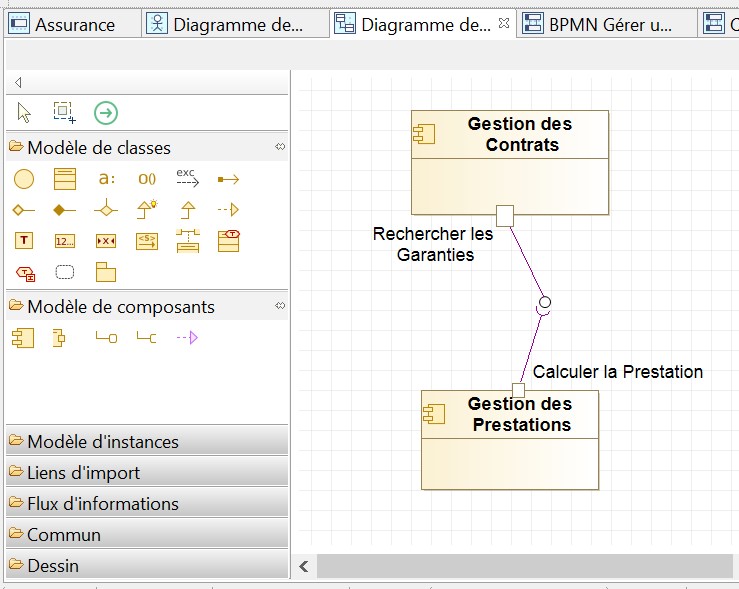
La réalisation d'un diagramme de composant avec les branchements est d'une grande facilité. Ici le composant "Gestion des Prestations" doit, pour calculer une prestation, interface requise, se connecter au composant "Gestion des Contrats" pour récupérer les garanties, interface fournie.
A noter que le raccourci Ctrl S pour sauvegarder ne fonctionne pas, contrairement aux autres diagrammes déjà créés, on est obligé de cliquer sur l'icône de sauvegarde.
SysML
Dans le menu Configuration, on a accès au catalogue de modules où se trouve SysML Architect. Dans le menu Modules, nous pouvons l'ajouter à la configuration du projet. Les diagrammes SysML sont alors disponibles.
Aussi étrange que cela puisse paraître, le diagramme d'exigences, pourtant primordial, manque à l’appel. Nous n’avons pas de chance, car c’est justement celui que l’on voulait faire, pour ensuite tracer les exigences dans notre diagramme de use case.
Les procédures de réalisation des 8 autres diagrammes (la norme de l'OMG en compte 9) sont identiques à ceux déjà testés.
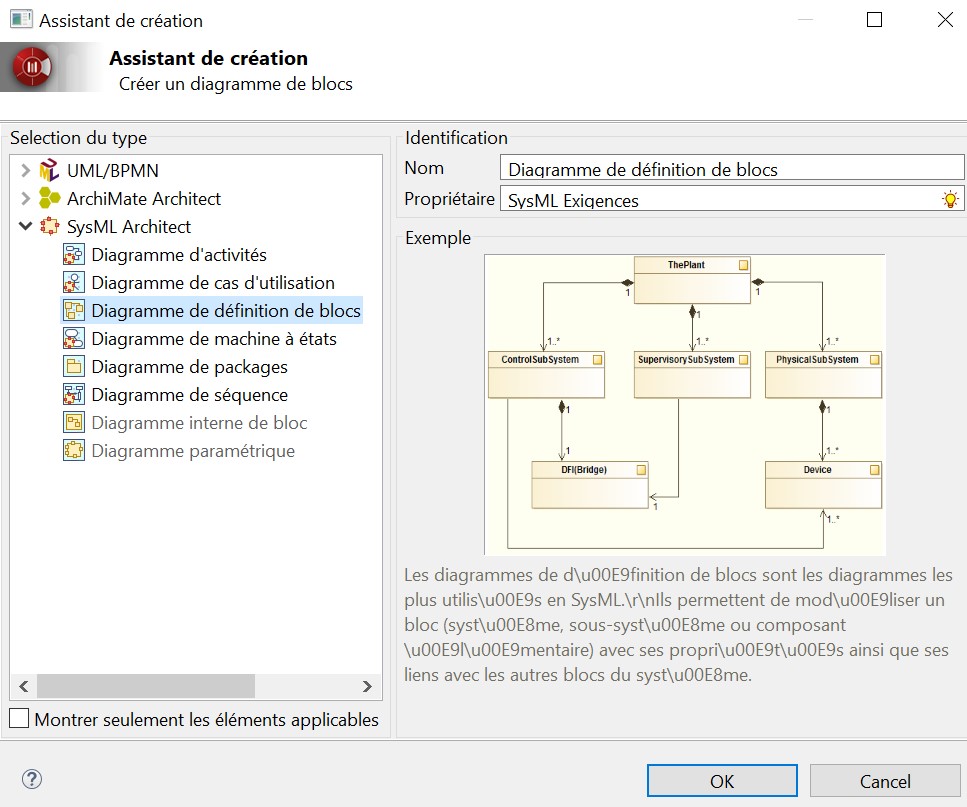
Les 8 diagrammes SysML supportés ; il manque le diagramme d’exigences, pourtant très utilisé.
TOGAF
De la même manière que précédemment, on peut ajouter au projet le module TOGAF Architect :
Modelio a conçu un profil UML pour le cadre d’architecture TOGAF. Rappelons par exemple que SysML et SOAML sont des profils UML, c'est-à-dire une surcouche de personnalisation, constituée de stéréotypes, tagged value et contraintes OCL.
Nous disposons alors de tous les diagrammes constituant leur profil TOGAF.
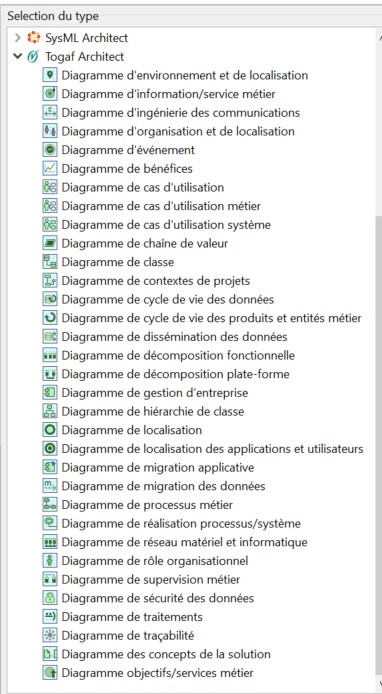
Liste des diagrammes du module TOGAF Architect
Pour chaque diagramme du profil TOGAF de Modelio, une note très pédagogique est générée, expliquant les objectifs du diagramme, la sémantique des différents artefacts entrant en jeu et la procédure à réaliser dans Modelio.
Import/Export de modèles
Des modèles .bpmn au format XML de la norme de l’OMG, réalisés avec d’autres outils, ont parfaitement été importés dans Modelio.
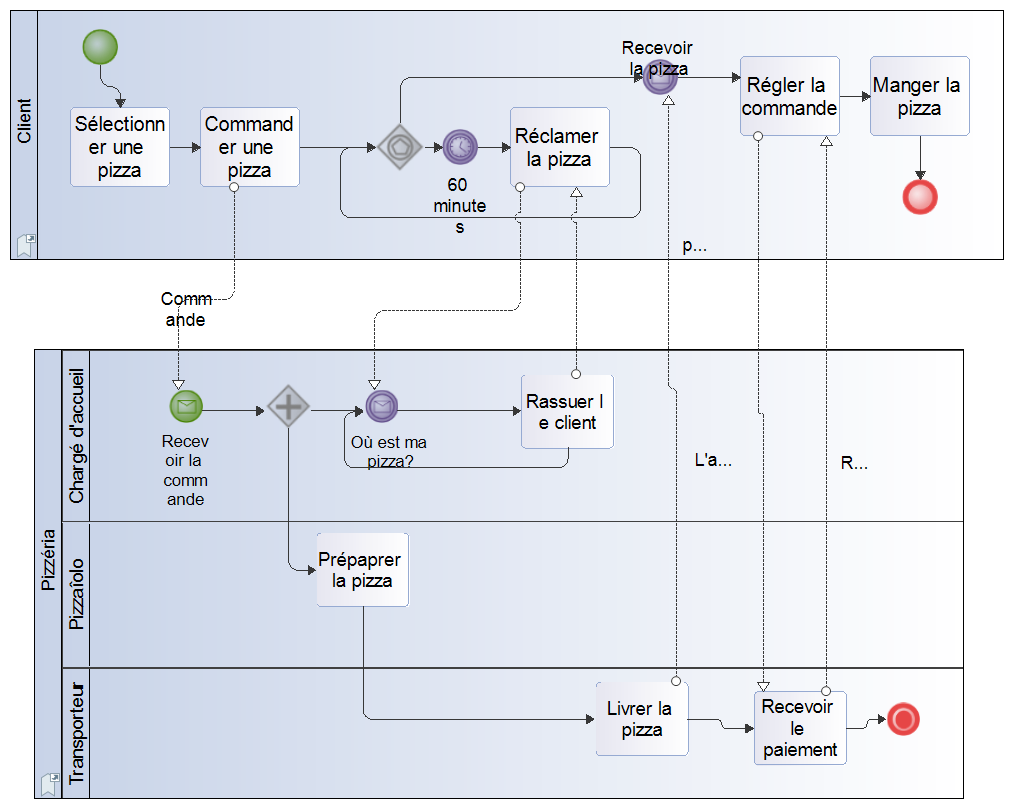
L’exemple de la norme OMG représentant la commande d’une pizza, réalisé avec l’outil bpmn.io,
l’outil open source de Camunda, a été importé avec succès sans aucune retouche dans Modelio.
De même, après avoir vérifié la conformité avec la norme dans le menu contextuel d'un modèle, vous pourrez l’exporter au format .bpmn standard.
MDA
Avec Modelio, on peut créer des stéréotypes UML et des profils c'est-à-dire un ensemble de stéréotypes, tagged value et contraintes OCL.
Audit
Modelio offre une vue audit permettant de détecter en temps réel ou en mode manuel les erreurs et de sélectionner les éléments s’y rapportant.
Scripts
Les scripts permettent à l’utilisateur d’écrire et d’exécuter du code stocké sous forme de macros réutilisables, qui pourront être lancées à partir du menu contextuel. Pour ce faire, Modelio utilise Jython, qui est un ensemble de bibliothèques Java implémentant le langage Python et directement intégrable dans une application Java.
Génération de rapports
Le module Excel Exchange permet d’exporter des cas d'utilisation ou des exigences, de Modelio vers Excel, puis de les modifier dans Excel et de les synchroniser dans Modelio. Cela signifie que vous pouvez choisir l'outil d'édition que vous préférez, Modelio ou Excel.
Pour générer des rapports au format HTML, il est possible d’installer le module gratuit Web Model Publisher.
Documentation
On trouve en français toutes les règles UML (OCL) implémentées dans l’outil.
Par exemple, la R1450 : ”Si une association est une composition, alors la multiplicité max de l’autre extrémité doit être de 1”. Des détails et des conseils accompagnent les règles, ce qui renforce le côté pédagogique de l’outil.
Bon nombre d’outils de modélisation ne proposent pas l’intégration de ces règles, permettant au débutant d’introduire des incohérences.
Les métamodèles complets BPMN et ArchiMate sont documentés en anglais.
Le manuel en français consacré à BPMN est complet, avec des explications sur les concepts et les procédures pour réaliser des diagrammes.
La documentation SysML est en anglais, ainsi que le profil dédié à TOGAF, qui est particulièrement bien expliqué et accompagné de nombreux exemples concrets.
Fiabilité
Des utilisateurs ont signalé qu’après une utilisation poussée, les artefacts de modélisation s’étaient retrouvés superposés faisant perdre de longues heures de travail.
Un projet Modelio n’est malheureusement pas contenu dans un seul fichier, mais dans une arborescence complexe de répertoires, portant préjudice à un partage et à la synchronisation via par exemple OneDrive.
Conclusion
De nombreux éditeurs d’outils d’architecture d’entreprise proposent des versions open source ou community, intégrant uniquement quelques fonctionnalités pour constituer un produit d’appel gratuit, comme ArchiMate, et dès que vous aurez besoin d’un référentiel partagé ou de BPMN et UML, il faudra payer des abonnements, qui peuvent être conséquents.
Cette version multi-OS offre gratuitement, en français, le support d’ArchiMate, BPMN, UML, SysML, TOGAF et MDA. Cet outil conviendra donc parfaitement à toute personne désirant se familiariser avec ces techniques de modélisation et notamment pourra servir comme outil pédagogique de base aux étudiants et à leur professeur, pour l’enseignement de la modélisation.
Pour les professionnels qui voudraient une version SaaS, un référentiel collaboratif, une génération de rapports personnalisables, la simulation, l’analyse d’impacts, une évaluation de chaque application du portefeuille, du Master Data Management…, le site de la société Softeam, éditeur de Modelio (https://www.modeliosoft.com/fr/), propose d’évaluer Modelio BA Business Architecture, mais après la période d'essai, il faudra contacter le département commercial pour acheter une version complètement fonctionnelle.
A cause des messages d’erreurs rencontrés lors de notre test et des remontées de problèmes qui nous ont été communiqués, Modelio obtient la note plus qu'honorable de 3,5/5.
Note : 3,5/5
Nous regrettons :
- Trop de problèmes sont survenus.
- L’ergonomie n’est pas au niveau de ce qui se fait aujourd’hui.
- Des diagrammes sont absents, par exemple le diagramme d’exigences pour la norme SysML.
- Le profil UML pour le framework TOGAF créé par Modelio n’est pas un standard (spécifique à l’outil).
Nous aimons :
- Un outil de modélisation open source supportant ArchiMate, BPMN, UML, SysML, TOGAF et MDA et disponible sur Windows, Linux et Mac OS.
- La possibilité de lier n’importe quels objets du référentiel pour assurer la traçabilité.
- La validation des diagrammes, avec la description détaillée des erreurs et des propositions de solutions pédagogiques.
- Nous pensons que le profil UML pour le framework TOGAF créé par Modelio est intéressant d’un point de vue uniquement pédagogique, mais en entreprise, il faudra passer au standard ArchiMate.
|
|
Rhona Maxwel @rhona_helena |
“Si c'est une bonne idée, allez-y et faites-la.
Il est beaucoup plus facile de s'excuser que d'obtenir la permission.”
Grace Hopper
Compléments de lecture
Outils de Modélisation et comparatifs
- ADOIT:CE pour la gestion de l’Architecture d’Entreprise
- ADOIT:CE (compléments d’information)
- Le meilleur du meilleur des outils de modélisation de Systèmes d’Information pour 2017 : les « Modsars » de « urbanisation-si.com » récompensent les plus innovants
- Les meilleurs outils de modélisation UML, SysML, BPMN, DMN de l'année 2016 et les gagnants sont ...
Pour devenir expert en UML
- Modélisation de système : Soyez maniaque, croisez et recroisez vos modèles UML pour être certain qu'ils soient valides (4)
- Modélisation de système : Soyez maniaque, croisez et recroisez vos modèles UML pour être certain qu'ils soient valides (5)
- Modélisation de système : Soyez maniaque, croisez et recroisez vos modèles UML pour être certain qu'ils soient valides (6)
- Modélisation de système : Soyez maniaque, croisez et recroisez vos modèles UML pour être certain qu'ils soient valides (7)
- Modélisation de système : Soyez maniaque, croisez et recroisez vos modèles UML pour être certain qu'ils soient valides (8)
- Modélisation de système : Soyez maniaque, croisez et recroisez vos modèles UML pour être certain qu'ils soient valides (9)
- Modélisation de système : Soyez maniaque, croisez et recroisez vos modèles UML pour être certain qu'ils soient valides (10)
- Modélisation de système : Soyez maniaque, croisez et recroisez vos modèles UML pour être certain qu'ils soient valides (11)
- Modélisation de système : Soyez maniaque, croisez et recroisez vos modèles UML pour être certain qu'ils soient valides (12)
- Modélisation de système : UML n'est rien sans OCL !
- Modélisation de système : OCL ça se complique !
- Modélisation de système : comment utiliser OCL avec Eclipse, c'est bien la question que tout le monde se pose
Diagramme d'exigences SysML
- SysML : le diagramme d'exigence (requirement diagram)
- SysML : exemples de diagramme d'exigence tout droit sortie de la norme de l'OMG
TOGAF
- TOGAF pour les nuls.
- Le processus des itérations ADM (Architecture Development Method), le moteur de la transformation d’entreprise TOGAF (The Open Group Architecture Framework)
- La phase A Vision du cycle de la méthode ADM (Architecture Development Method) de la transformation d’entreprise TOGAF (The Open Group Architecture Framework)
- Comment mettre en œuvre la phase B Métier de la méthode ADM (Architecture Development Method) du framework d’Architecture d’Entreprise TOGAF (The Open Group Architecture Framework)
- Comment mettre en œuvre la phase C Système d’Information et la phase D Technique de la méthode ADM (Architecture Development Method) du framework d’Architecture d’Entreprise TOGAF (The Open Group Architecture Framework)
- Comment mettre en œuvre la phase E Opportunités et Solutions de la méthode ADM (Architecture Development Method) de la transformation d’entreprise TOGAF (The Open Group Architecture Framework)
- Comment mettre en œuvre la phase F Planning de migration de la méthode ADM (Architecture Development Method) de l’architecture d’entreprise TOGAF (The Open Group Architecture Framework)
- Comment mettre en œuvre la phase G Gouvernance de la méthode ADM (Architecture Development Method) de l’architecture d’entreprise TOGAF (The Open Group Architecture Framework)
- Les objectifs de la phase H « Gestion de la maintenance et des évolutions » de la méthode ADM (Architecture Development Method) de l’architecture d’entreprise TOGAF (The Open Group Architecture Framework)
- La vision dynamique des exigences de la méthode ADM (Architecture Development Method) de l’architecture d’entreprise TOGAF (The Open Group Architecture Framework)
- La structure de l’architecture d’entreprise TOGAF (The Open Group Architecture Framework)
- Les concepts du métamodèle de l’architecture d’entreprise TOGAF (The Open Group Architecture Framework)
- Le diagramme de classe UML du métamodèle de l’architecture d’entreprise TOGAF (The Open Group Architecture Framework)
- L’extension « Gouvernance » du métamodèle de l’architecture d’entreprise TOGAF (The Open Group Architecture Framework)
- L’extension « Services » du métamodèle de l’architecture d’entreprise TOGAF (The Open Group Architecture Framework)
- L’extension « Modélisation de processus métier » du métamodèle de l’architecture d’entreprise TOGAF (The Open Group Architecture Framework)
- L’extension « Modélisation des données » du métamodèle de l’architecture d’entreprise TOGAF (The Open Group Architecture Framework)
- L’extension « Consolidation d’infrastructure » du métamodèle de l’architecture d’entreprise TOGAF (The Open Group Architecture Framework)
- L’extension « Motivation » du métamodèle de l’architecture d’entreprise TOGAF (The Open Group Architecture Framework)
- Le référentiel TOGAF sous toutes ses coutures : le « Continuum d'Entreprise » et la réutilisation de l'architecture
- Le référentiel TOGAF, le patrimoine des informations et des bonnes pratiques pour toute l’entreprise
- Gouvernance d’entreprise, Gouvernance technologique, Gouvernance informatique et Gouvernance de l’architecture : mais où se situe la Gouvernance TOGAF ?
- Le cadre de gouvernance de l'architecture : identifier les processus et les structures organisationnelles efficaces
- Gouvernance de l'architecture en pratique : principaux facteurs de succès et éléments d'une stratégie efficace
ArchiMate
- ArchiMate pour les nuls : les fondamentaux - 1
- ArchiMate la synthèse : les éléments de motivation - 2
- ArchiMate en condensé : les éléments de stratégie - 3
- ArchiMate l’essentiel : les éléments de la couche métier - 4
- ArchiMate mémento : les éléments de la couche application - 5
- ArchiMate aide mémoire : les éléments de la couche technologique - 6
- ArchiMate en abrégé : les éléments physiques de modélisation - 7
- ArchiMate mémento : Alignement de la couche métier avec les couches inférieures - 8
- ArchiMate : modélisation de l’alignement des couches d'application et de technologie - 9
- ArchiMate : les éléments d'implémentation et de migration - 10
- ArchiMate : vues et points de vue - 11
- ArchiMate : guide complet des éléments de modélisation - 12
BPMN
- BPMN 2 : les concepts de base des processus métiers
- BPMN pour les nuls : les collaborations
- BPMN pour les nuls : les chorégraphies (Choreographies)
- BPMN pour les nuls : les conversations
- BPMN : norme OMG - synthèse des éléments graphiques
- BPMN : l'antisèche pour rester incollable en modélisation de processus
- BPMN l’exemple type pour tout comprendre sans prendre d’aspirine
- BPMN : la norme, toute la norme rien que la norme. L'exemple à lire en attendant une pizza
- BPMN : mais que dit la norme sur les sous-processus et la gestion des événements d'interruption et de remontée d'incidents ?
- BPMN : processus exécutables, comment s'y prendre ? (1/3)
- BPMN : processus exécutables, comment s'y prendre ? (2/3)
- BPMN : processus exécutables, comment s'y prendre ? (3/3)
- Comment identifier, simuler, améliorer et modéliser les processus métiers ?
- Comment mettre en place un jeu de rôles pour modéliser un processus métier ?
Les couches de l'Architecture Microservices et la méthode de conception DDD (Domain Driven Design)
Nous allons décrire dans cet article le rôle des différentes couches de l'Architecture Microservices et le lien avec la méthode de conception DDD.

(Ce diagramme ArchiMate, montre que toutes les couches dépendent de la couche “Domaine Métier”. Réalisé avec Modelio Open Source outil de modélisation UML, BPMN et ArchiMate)
Certaines grandes plateformes numériques dont certaines font partie des GAFAM ont été confrontées récemment à de gigantesques pannes paralysant l’ensemble de leurs activités écornant leur image de Graal de la technologie. Un des enjeux de l’architecture Microservices est d’offrir une meilleure résilience grâce à des outils de détection, de contournement et de remplacement des blocs défectueux.
Si la physique de l’infiniment grand et de l’infiniment petit forme un tout, il en va de même pour les Systèmes d’Information qui se basent sur les concepts et patterns des technologies objets de développement, comme les fameux Design Patterns du GoF (1995), les principes SOLID, les GRASP patterns, ceux de Martin Fowler et Sam Newman.
Les systèmes sont faiblement couplés vers l’extérieur et sont constitués d’éléments cohérents en interne.
On est bien en présence d'une architecture fractale. Les domaines d'application des fractales se retrouvent partout même dans l'urbanisme des villes et donc aussi dans l'urbanisme des SI.
Dans sa méthode de conception DDD, Eric Evans, auteur du livre “Domain-Driven Design: Tackling Complexity in the Heart of Software”, intègre et développe ces patterns dans l'Architecture Microservices adoptée aussi bien par les GAFAM que par les PME.
Couche Contrôleur
Les interfaces de communication ou API (Application Program Interface) sont implémentées.
Le protocole le plus simple et le plus utilisé est REST (REpresentational State Transfer) reposant sur HTTP.
Les données sont représentées textuellement en JSON (JavaScript Object Notation).
Tout est permis, on peut trouver des protocoles de type “Event Streaming Consumer” ou des interfaces pour les programmes batchs.
Le pattern d’architecture distribuée DTO (Data Transfer Object), consistant à ne transférer que les données utiles est mis en œuvre et s’appuie sur des technologies de sérialisation/désérialisation des objets en JSON.
L'implémentation du pattern "proxy" permet d'utiliser des objets distants et complexes comme s'ils étaient locaux en masquant la gestion des trames HTTP et la transformation en JSON.
Pour les spécificités des microservices, les aspects comme la traçabilité condition sine qua non pour la mise au point, la supervision des états, la conformité des SLA (Service Level Agreement) et l’administration sont effectués par de nombreuses technologies faisant partie de l’entité contrôleur.
Couche Applicative
Les fonctionnalités sont dérivées des cas d’utilisation UML dans lesquels on trouve des VO (Value Object) qui sont des objets immutables.
La coordination et les transactions longues métier sont réalisées par la gestion de l’état de progression d’un processus métier.
Aucune règle métier n’est exécutée, seuls des contrôles syntaxiques sont opérés pour préparer les données métier pour la couche “Domaine Métier”.
Les authentifications, autorisations, cryptages et les parades aux attaques connues, sont mis en œuvre.
Des contributions à l’amélioration des performances peuvent se traduire par des technologies de cache.
Couche Domaine Métier (DDD)
Ce niveau représente une zone métier (“Bounded context” en DDD) bien délimitée et autonome (“Les bonnes barrières font les bons voisins” Eric Evans).
En MDA (Model Driven Architecture), ce serait la couche PIM (Platform Independent Model).
Ici, on ne trouve pas la moindre trace de framework technologique, la persistance par exemple est reléguée dans l’infrastructure.
A l’intérieur des frontières, on parle le jargon des experts métiers (traduit en DDD cela donne : “Ubiquitous Language”). Le langage ubiquitaire est le concept de définition d'un langage (parlé et écrit) qui est également utilisé par les développeurs et les experts du domaine pour éviter les incohérences et les problèmes de communication dus aux problèmes de traduction et aux malentendus. La même terminologie apparaît dans le code, les conversations entre tous les membres de l’équipe, les spécifications fonctionnelles, etc.
Les modèles sont composés de diagrammes de classes et d’états-transitions UML.
Le métier et le code sont alors liés par l’Ubiquitous Language.
Pour faire communiquer des "bounded context" différents, il faut des adaptateurs permettant l’interopérabilité et garantissant l’indépendance des systèmes. Déjà en 1995 la bande des quatre (Erich Gamma, Richard Helm, Ralph Johnson et John Vlisside) inventeurs des patterns de conception objet et auteurs du livre fondateur “Design Patterns: Elements of Reusable Object-Oriented Software” avaient défini le pattern “adapter”.
Oserait-on l’heuristique : DDD = 80% de bounded context + 20% d’adapter.
Couche Infrastructure
Elle sert de support à toutes les autres couches rendant possible l’interopérabilité.
La persistance des entités métier est réalisée.
Les autres couches y accèdent en utilisant l’injection de dépendances (pattern IOC Inverse Of control) qui est un des principes SOLID (Single responsibility ; Open closed ; Liskov substitution ; Interface segregation ; Dependency inversion), qui délègue à un tiers la réalisation des relations entre les entités permettant l'agilité, l'évolutivité, la maintenabilité et la réutilisabilité en maintenant un couplage faible entre les composants.
Conclusion
Le domaine ne dépend d’aucune couche
L’infrastructure dépend du domaine.
L’application dépend du domaine
La présentation dépend de l’application et de l’infrastructure.
|
|
Rhona Maxwel @rhona_helena |
“Tiny, the only thing you need to know about development, project management and leadership”
Chad Fowler
(“Minuscule, la seule chose que vous devez savoir sur le développement, la gestion de projet et le leadership”)
Compléments de lecture
- L’Architecture Micro-Services expliquée à ma fille
- Inconvénients de l'Architecture Micro-Services
- Orchestration des micro-services avec BPMN
- Conseils pour réussir vos micro-services et éviter qu’ils ne se transforment en véritable pensum
- Estimation de la complexité d’une Architecture Micro-Services
- Solutions sur étagère pour la gestion des défaillances des Micro-Services
- Comment éviter la loi de Conway et faciliter ainsi l’agilité avec l’approche Micro-Services ?
- Le meilleur outil pour transformer, dériver, parcourir, requêter sur des modèles afin de mettre en œuvre MDA (Model Driven Architecture)
Quelles solutions pour concilier architecture logicielle et agilité ?
Des plus petites aux plus grandes entreprises, le concept de bounded context est aujourd’hui au cœur de la conception d’architecture logicielle, mais se pose l’éternelle question de quelle méthode pour parvenir à un découpage produisant le couplage le plus faible, augmentant ainsi l’évolutivité, l'autonomie et l'agilité.
Evolution de l'architecture logicielle
Dans notre article consacré au livre Urbanisation, SOA et BPM, l’auteur Yves Caseau, insiste sur l’urbanisation fractale ou comment appliquer récursivement les mêmes principes à différentes échelles du SI. En effet, les concepts, comme les “General Responsibility Assignment Software Principles" (GRASP) ou encore les design patterns du GoF (Gang of Four), mis en œuvre dans la conception orientée objet à toute petite échelle, se retrouvent dans les strates supérieures au niveau de l’architecture d’entreprise. Ces principes sont les gammes de l’architecte logiciel, qui s’acquièrent au plus bas niveau en programmation orienté objet et qui permettent ensuite d’avoir les bons réflexes au niveau d’un SI global.
D'après Craig Larman, ces patterns sont des “boîtes à outils mentales”, une aide à la conception à petite ou à très grande échelle.
Nous appliquerons donc ces patterns au niveau architecture logicielle, afin d’obtenir un couplage faible et une forte cohésion.
De la démultiplication des critères qualité
Commençons par un problème récurrent de l’architecture logicielle qui est de pouvoir gérer l’évolutivité et la résilience. Une première idée est de multiplier les systèmes que ce soit au niveau du front-end ou du back-end. A partir de ce moment, une série de problèmes va se poser. Par exemple, comment gère-t-on les états, que choisir entre stateless et stateful ? Doit-on stocker l’état dans tous les back-ends ou bien doit-on mettre en place une solution de “sticky session” pour retrouver le système qui a enregistré l'état. Cette solution est complexe, elle utilise un équilibreur de charge (load balancer), une gestion d’identifiants supplémentaires, mais que se passe-t-il s’il tombe en panne, si le back-end contenant l’état devient surchargé ?
Faisons alors du stateless avec un cache partagé qui contiendra l’état. Si le cache tombe, on met un cluster, mais cela implique que l’on doit gérer la réplication et la cohérence des données…
C’est l’escalade presque sans fin des patterns Circuit Breaker (Disjoncteur), Bulkheads (Cloisonnement)… (voir notre article Solutions sur étagère pour la gestion des défaillances des Micro-Services)
Afin d’éviter cette course effrénée aux propriétés de qualité, il faut s’intéresser à la volumétrie de l’entreprise concernée : a-t-on besoin d’une surenchère de tels systèmes pour une entreprise de quelques dizaines d’utilisateurs ? A-t-on besoin de temps réel ? Pour la plupart des TPE ou PME, les enjeux ne justifient pas la mise en œuvre de systèmes redondants et hautement performants pour des coûts exorbitants.
Une pléthore de possibilités de découpages
Découpage par couches
Découpage par couches
Souvent le plus utilisé, le découpage par couche, consiste à séparer l’aspect web (présentation + contrôleur), l’aspect métier (services + règles), DAO (Data Access Object) et enfin la persistance. Le nombre d’appels entre chaque couche est très important et les risques de conflits au moment des commits sont augmentés.
Découpage par technologies
Découpage par technologies
L’exemple typique est d’avoir un existant composé par exemple d’un monolithe Java avec Jakarta EE (anciennement JEE), d’un système plus récent architecturé en micro-services avec Node.js, pour l’IA une architecture Python avec sa cohorte de bibliothèques de Machine ou Deep Learning, les référentiels avec SQL basé sur MySQL ou noSQL basé sur MongoDB… Un couplage fort sera forcément présent, par exemple entre Jakarta EE et MySQL ou Node.js et MongoDB.
Découpage entre entités
Diagramme UML de classe réalisé avec l'outil gratuit Visual Paradigm
L’architecture micro-services est souvent basée sur ce type de décomposition. A titre d’exemple volontairement simplifié, pris dans le monde assurantiel, on va trouver les micro-services Produit, Personne, Contrat, Prestation…
L’accès aux informations d’un contrat va entraîner de nombreux échanges nécessitant un fort couplage.
Pour calculer une prestation, on a besoin du contrat, de la personne…
Les entités Contrat et Prestation auront besoin de nombreuses données en provenance des entités Produit et Personne, d’où des relations fortes sous forme d’associations UML, ce qui introduit un couplage fort, une augmentation de la bande passante réseau, de CPU, sans oublier les nombreux conflits sur le SCM (Source Control Management).
Mais alors quel découpage préconisé ?
Diagramme UML de classe réalisé avec l'outil gratuit Visual Paradigm
Les décompositions précédentes présentent donc des problèmes de performances, de conflits entre les développements et un fort couplage semblable à une architecture spaghetti.
La bonne solution : le découpage par zones fonctionnelles homogènes (bounded context), regroupant des entités appartenant à un même domaine.
Reprenons notre exemple, on peut constituer 3 domaines fonctionnels homogènes : Marketing (Produit, Prospect), Contrat (Couverture, Assuré) et Prestation (Garantie, Bénéficiaire).
Dans le domaine Marketing, les entités Produit et Prospect deviennent respectivement dans le domaine Contrat, Couverture et Assuré, qui eux-mêmes deviennent Garantie et Bénéficiaire dans le domaine Prestation.
La même personne en chair en os avec la même identité est vue comme prospect dans le marketing, assuré dans le contrat et bénéficiaire dans la prestation.
De même pour un produit dans le marketing, le domaine contrat va utiliser les données de couverture et la prestation les données concernant les garanties.
Cette méthode de regroupement permet d’avoir des zones autonomes. Les liens s’implémentent par des adaptateurs chargés de recopier uniquement les données utiles d’une entité dans une autre.
Mais alors, on viole le principe de non-duplication de données ?
Les adaptateurs copient uniquement les propriétés utiles pour un domaine, c’est le prix à payer pour avoir une forte isolation, un couplage très faible et par conséquent une grande autonomie et évolutivité.
Cette duplication des données se retrouve partout dans la vraie vie, par exemple dans les réseaux sociaux : on a un ami sur Facebook, un candidat sur LinkedIn, un commiter sur Github, un collaborateur sur Slack… Ces différentes plateformes gèrent avec leur propre sémantique la même personne, mais adaptée à leurs objectifs et peuvent partager le même identifiant permettant de se connecter avec un ID Google ou Facebook par exemple.
Le pouvoir de choisir la technologie la plus adaptée
Autre avantage d’une bonne découpe, c’est de pouvoir choisir la technologie la plus adaptée
Prenons l’exemple de la persistance :
- Domaine Marketing regroupant les produits et les prospects : NoSQL favorisant les recherches rapides sur de gros volumes en lecture.
- Domaine Contrat : RDBMS (Relational Database Management System) SQL, pour les aspects transactionnels.
- Domaine Prestation : RDBMS SQL ou Cassandra NoSQL conçu pour gérer des quantités massives de données sur un grand nombre de serveurs, assurant une haute disponibilité en éliminant les points de défaillance unique.
Conclusion
Ce concept de bounded context est de plus en plus considéré et mis en œuvre dans les entreprises et fait partie du DDD Domain Driven Design (voir nos articles Les couches de l'Architecture Microservices et la méthode de conception DDD (Domain Driven Design) et Architecture Hexagonale, exemple de mise en pratique de la méthode DDD Domain Driven Design).
La difficulté consiste à bien délimiter les contours. Pour les identifier, il faudra alors faire appel à l’expérience et à des heuristiques propres.
|
|
Rhona Maxwel @rhona_helena |
“Apprendre à penser, à réfléchir, à être précis (…), à écouter l’autre, c’est être capable de dialoguer, c’est le seul moyen d’endiguer la violence effrayante qui monte autour de nous. La parole est le rempart contre la bestialité.”
Jacqueline de Romilly
Compléments de lecture
- L’Architecture Micro-Services expliquée à ma fille
- Inconvénients de l'Architecture Micro-Services
- Orchestration des micro-services avec BPMN
- Conseils pour réussir vos micro-services et éviter qu’ils ne se transforment en véritable pensum
- Estimation de la complexité d’une Architecture Micro-Services
- Solutions sur étagère pour la gestion des défaillances des Micro-Services
- Comment éviter la loi de Conway et faciliter ainsi l’agilité avec l’approche Micro-Services ?
- Les couches de l'Architecture Microservices et la méthode de conception DDD (Domain Driven Design)
- Architecture Hexagonale, exemple de mise en pratique de la méthode DDD Domain Driven Design
- Urbanisation, SOA et BPM d’Yves Caseau
Solutions sur étagère pour la gestion des défaillances des Micro-Services
L'objectif des micro-services est d'accélérer la mise en production des applications, en décomposant l'application en petits services autonomes, qui peuvent être déployés indépendamment les uns des autres. Une architecture de micro-services pose également certains problèmes. Voici une synthèse des patterns les plus utilisés afin d'éviter les pannes.

Le génie logiciel emprunte de nombreuses idées au génie civil, où les ingénieurs s'occupent de la conception, de la construction et de l'entretien des routes, des ponts, des canaux, des barrages et des bâtiments.
Ces ingénieurs prévoient les défaillances des composants individuels et pour pallier cela, ils assurent plusieurs redondances pour des bâtiments plus sûrs et plus stables.
Le même “mindset” peut être appliqué au génie logiciel. Des défaillances isolées sont inévitables, mais l'objectif reste de concevoir des systèmes fonctionnant aussi longtemps que possible.
Les pratiques d'ingénierie, telles que la modélisation et l’injection de défaillances, devraient être incluses dans le cadre d'un processus d’intégration et de livraison continue, afin de concevoir des systèmes plus fiables.
Circuit Breaker (Disjoncteur)
Le modèle "Circuit Breaker" (disjoncteur) est couramment utilisé pour garantir que, en cas de défaillance d’un micro-service, l'ensemble du système ne soit pas affecté.
Cela se produit si le volume des appels au service ayant échoué est élevé et, pour chaque appel, on doit attendre qu'un délai se produise avant de continuer.
Faire l'appel au service défaillant et attendre utiliserait des ressources, ce qui finirait par rendre le système global instable.
Le modèle de "Circuit Breaker" se comporte comme un simple disjoncteur, comme celui de votre circuit électrique domestique. Les appels à un micro-service sont enveloppés dans un objet "Circuit Breaker".
Lorsqu'un micro-service défaille, l'objet "Circuit Breaker" autorise les appels ultérieurs au service jusqu'à ce qu'un seuil de tentatives infructueuses soit atteint.
À ce moment-là, le "Circuit Breaker" pour ce micro-service se déclenche, et tout autre appel sera court-circuité et n'entraînera pas d'appels au micro-service en échec.
Ce pattern d'installation économise de précieuses ressources et maintient la stabilité globale du système.
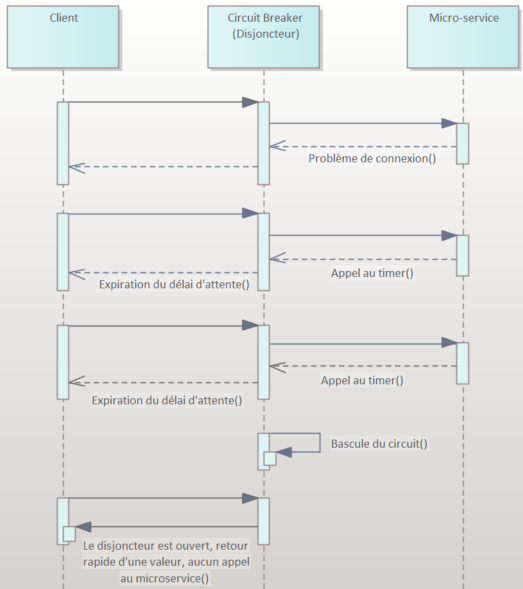
(Diagramme de séquence UML du "Cicuit Breaker")
Lorsque le "Circuit Breaker" se déclenche et que le circuit est ouvert, un traitement de secours peut être démarré à la place. La logique de secours effectue généralement peu ou pas de traitements et renvoie une valeur. Ces actions de secours doivent avoir peu de chances d'échouer, car ils s'exécutent à la suite d'un échec au départ.
Bulkheads (Cloisonnement)
L’informatique a souvent repris à son compte des concepts appartenant à d’autres domaines comme pour la sécurité des navires avec les cloisons étanches des coques. Si l'une des cloisons est endommagée, cette défaillance est limitée à cette seule cloison et les autres cloisons permettent de garder le bateau à flot.
La même approche de partitionnement peut également être utilisée dans les logiciels pour isoler une partie du système.
Ce pattern peut également être appliqué dans les micro-services eux-mêmes. Par exemple, un pool de threads utilisés pour atteindre deux systèmes existants. Si l'un des systèmes a commencé à connaître un ralentissement et a provoqué l'épuisement du pool de threads, l'accès à l'autre système existant sera également affecté.
Avoir des pools de threads séparés garantit qu'un ralentissement dans un système existant n'épuise que son propre pool de threads.
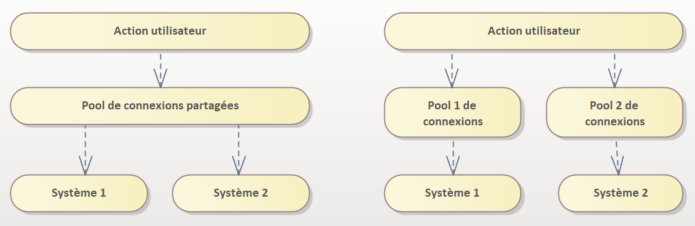
(Exemple de pattern "bulkhead" : utilisation de pools de threads séparés)
Gestion décentralisée des données
Dans une application monolithique, il est facile de traiter les transactions, car tous les composants font partie du monolithe.
Lorsque vous passez à une architecture de micro-services distribuée, vous devez désormais potentiellement traiter des transactions réparties sur plusieurs services.
Dans une architecture de micro-services, la préférence va à "BASE" (Basically Available, Soft state, Eventual consistency), plutôt que de type "ACID" (Atomicity, Consistency, Isolation, Durability).
Les transactions distribuées sont à éviter chaque fois que c'est possible.
Idéalement, chaque micro-service gère sa propre base de données. Cela permet d’être agnostique sur les moyens de persistance (SQL, NoSQL…).
Une contrainte de préservation du caractère ACID d’une transaction peut aboutir à ce que plusieurs micro-services utilisent la même base de données. Quelle qu'en soit la raison, une attention particulière doit être accordée au partage de la base de données.
Les avantages et les inconvénients de le faire doivent être pris en considération.
A l’opposé, le partage d'une base de données peut violer le principe de parfaites indépendance et autonomie de chaque micro-service. En effet dans ce cas, les micro-services pourraient dépendre des changements dans la base apportés par un autre micro-service.
Le niveau de partage entre les micro-services doit être limité autant que possible pour rendre les micro-services aussi faiblement couplés que possible.
Discoverability (Découverte)
L'architecture des micro-services nécessite de rendre les services fiables et tolérants aux pannes. Cela implique la construction de micro-services de telle manière que, si l'infrastructure sous-jacente est détruite, alors les micro-services peuvent être reconfigurés et communiquer avec d’autres micro-services pour les besoins de l’application globale.
L'utilisation du cloud computing et des conteneurs, pour le déploiement de micro-services, offre la possibilité d’une reconfiguration dynamique. Lorsque la nouvelle instance du micro-service est créée, les autres micro-services peuvent la trouver rapidement et commencer à communiquer avec elle grâce à un système de découverte des micro-services reposant sur un registre (ex. open source : Netflix Eureka), auxquels tous les micro-services doivent s’enregistrer explicitement.
Avec un tel système, l’équilibrage de charge (load balancing ; ex. open source : Netflix Ribbon) devient alors une réalité.
Conception de communication inter-services
Lorsque les micro-services sont répartis sur les différents serveurs (Tomcat), conteneurs (Docker) ou machines virtuelles (Oracle Virtual Box), on peut se poser la question : comment communiquent-ils ?
Une première solution est de mettre en place des files d'attente de messages qui suffisent pour les communications unidirectionnelles.
Avec un monolithe applicatif, les clients de l'application (navigateurs ou applications natives) font des requêtes HTTP (Hypertext Transfer Protocol) à un équilibreur de charge, ce qui propage la demande à plusieurs instances identiques de l'application.
Mais dans l'architecture micro-services, le monolithe a été remplacé par une collection de micro-services. Une deuxième solution consiste à utiliser le protocole REST (REpresentational State Transfer), pour la communication des micro-services entre eux ainsi qu’avec le client.
(Appels entre les clients et les micro-services en utilisant des API REST)
À première vue, cela peut sembler souhaitable. Cependant, certains clients peuvent être « bavards » ; d'autres peuvent nécessiter de nombreux appels pour obtenir les données. Étant donné que les services peuvent évoluer différemment, il y a d'autres défis à relever, comme le traitement des défaillances partielles.
Une meilleure approche pour le client est de faire peu de requêtes, peut-être juste une, en utilisant le pattern du GoF (Gang of Four) "façade", de type API Gateway (passerelle).
(Intégration du pattern "façade" comme l'API Gateway)
L'API Gateway se situe entre les clients et les micro-services et fournit des API qui sont sur mesure pour les clients. Elle consiste principalement à masquer la complexité technologique (par exemple, la connectivité à un ordinateur central), par rapport à la complexité de l'interface.
Une API Gateway est donc une façade. Cependant, une façade offre une vue uniforme des éléments internes complexes aux clients externes, alors qu'une API Gateway fournit une vue uniforme des ressources externes aux composants internes d'une application.
Tout comme le modèle de conception de façade, l'API Gateway fournit une interface simplifiée aux clients, ce qui rend les services plus faciles à utiliser, à comprendre et à tester.
En effet, il peut fournir différents niveaux de granularité aux clients. L'API Gateway peut fournir des API à grosses granularités aux appareils mobiles et des API à fines granularités aux ordinateurs de bureau, qui pourraient utiliser un réseau haut débit. Dans ce scénario, l'API Gateway réduit la conversation en permettant aux clients d'agréger plusieurs demandes en une seule, optimisée pour un client donné (tel que le client mobile).
HTTP synchrone versus messagerie asynchrone
Il existe deux approches principales pour la communication interprocessus :
- Les mécanismes synchrones basés sur HTTP, tels que REST, SOAP ou WebSocket, qui permettent de conserver un canal de communication entre les navigateurs et serveurs, pour les requêtes / réponses pilotées par les événements,
- La communication asynchrone utilisant un "message broker" (négociateur de messages ; ActiveMQ, Kafka, RabbitMQ, Redis...).
La communication synchrone est un mécanisme simple, compatible avec le pare-feu. L'inconvénient est qu'elle ne prend pas en charge d'autres modèles, comme le modèle de publication / abonnement. Elle ne permet pas non plus la mise en file d'attente des demandes, ce qui peut ralentir les performances.
Avec les applications synchrones, le client et le serveur doivent être disponibles simultanément et les clients doivent toujours connaître l'hôte et le port du serveur, ce qui n'est pas toujours simple lorsque les services évoluent automatiquement lors d'un déploiement cloud.
La communication asynchrone dissocie les services les uns des autres dans le temps, permettant d’envoyer des messages au fil de l'eau, stockés dans une file d'attente, tandis que le système de messagerie prend la responsabilité du message, en le gardant en sécurité jusqu'à ce qu'il puisse être livré au destinataire.
Le style de messagerie de publication / abonnement est plus flexible que la mise en file d'attente point à point, car il permet à plusieurs destinataires de s'abonner au flux de messages. Cela permet d'ajouter plus facilement plusieurs micro-services à l'application.
Alternativement, un mécanisme asynchrone utilise un "message broker", cet intermédiaire permet de diminuer le couplage entre les producteurs et les consommateurs. Le "message broker" met les messages en mémoire tampon jusqu'à ce que le consommateur soit en mesure de les traiter. Ce type de scénario de répartition de la charge permet aux développeurs de créer des applications évolutives et réactives. L'application peut être découpée en threads s'exécutant en arrière-plan, ce qui lui permet de continuer sans attendre la fin d'exécution des threads.
Les deux approches présentent des avantages et des inconvénients. La plupart des applications utilisent une combinaison de ces deux approches, adaptée à leurs besoins.
Faire face à la complexité
Une architecture de micro-services crée une utilisation supplémentaire des ressources pour de nombreuses opérations. Le nombre de composants augmente et en même temps la complexité. Rationaliser le comportement de chaque composant individuel pourrait être plus simple, mais comprendre le comportement de l'ensemble du système est beaucoup plus difficile.
Le réglage d'un système basé sur des micro-services, qui peut consister en des dizaines de processus, en comptant les "load balancers" et les "messages brokers", nécessite une surveillance et une expertise accrues.
Tests
Le test d'un système complexe nécessite des suites de tests unitaires et d'intégration, et un cadre de tests qui simule les composants défaillants, la dégradation des performances du service, la résistance et le comportement global du système au cours d'une journée classique.
Ces cadres de tests assurent l'exactitude et la résilience globale du système.
En raison de l'accent mis sur le bon fonctionnement du système lorsqu'un composant tombe en panne, dans une architecture de micro-services, il n'est pas rare de tester un échec en production.
Des tests automatisés, qui forcent un composant à échouer, permettent de tester la capacité du système à reprendre en cas d'erreurs, ainsi que les capacités de surveillance.
Surveillance
En plus des systèmes de surveillance conventionnels, des services bien conçus peuvent fournir des informations supplémentaires sur l'état de santé d'une architecture en utilisant le modèle publication / abonnement.
De cette façon, les informations peuvent être collectées par le service de surveillance, offrant des indicateurs de configuration.
Ces indicateurs peuvent à leur tour être utilisés pour garantir que les services ont la capacité suffisante pour traiter le volume demandé et comparer les performances actuelles par rapport à celles attendues.
Les contrôles personnalisés peuvent être enregistrés pour recueillir des données supplémentaires.
Toutes les informations de collecte peuvent être agrégées et affichées dans le tableau de bord de surveillance.
DevOps
Le défi de maintenir les micro-services opérationnels signifie que vous avez besoin d'expertise en DevOps dans votre équipe de développement.
Programmation polyglotte
Très souvent, une architecture micro-services utilise plusieurs langages, Java pour la partie back-end, Python pour l'IA… ce qui présente un défi pour maintenir un tel système hyper-polyglotte.
Des développeurs peuvent déployer, exécuter et optimiser les produits noSQL (MongoDB) et remplacer l'administrateur de base de données (DBA).
Maintenir un pipeline de développeurs et d'architectes techniques qualifiés est aussi critique que la maintenance du pipeline DevOps.
On doit garantir qu’il y a suffisamment de développeurs qualifiés pour maintenir la plate-forme et améliorer la conception du système à mesure que de nouvelles évolutions sont réalisées.
La plupart des organisations ont une liste restreinte de langages de programmation qu'ils utilisent. Cela présente des avantages du point de vue de la réutilisation du code et des compétences.
Conception évolutive
L'architecture des micro-services permet une approche de conception évolutive. L'idée centrale est que vous pouvez introduire de nouvelles fonctionnalités dans votre application en changeant un seul micro-service. Il vous suffit de déployer les micro-services que vous avez modifiés. Le changement n'affecte que les consommateurs de ce micro-service et, si l'interface n'a pas changé, tous les consommateurs continuent de fonctionner.
Étant donné que les micro-services sont faiblement couplés, petits et ciblés, et ont un contexte borné, des modifications peuvent y être apportées rapidement et fréquemment avec un risque minimal.
Cette facilité de l'évolutivité d'un micro-service permet d'évoluer rapidement.
Parce qu'un micro-service est petit et généralement conçu, développé et entretenu par une petite équipe « deux pizzas », il est typique de trouver des micro-services entièrement réécrits, par opposition à être mis à niveau ou maintenus. Un compromis courant réside dans la petite taille de votre micro-service.
Cependant, plus chaque micro-service est petit, plus il est probable qu'une mise à jour d'une application classique nécessite plus de micro-services à déployer, augmentant ainsi le risque de dysfonctionnement.
Les principes des micro-services, tels que la déployabilité indépendante et le couplage lâche, doivent être pris en compte pour déterminer quelle fonctionnalité métier devient un micro-service.
Conclusion
Les micro-services peuvent avoir un impact positif sur votre entreprise.
Ce nouveau paradigme qu'est l'architecture micro-service (MSA) nécessite l'utilisation de modèles de conception pour la fiabilité, exactement comme pour le paradigme objet, où il existe des design patterns pour l'évolutivité, la maintenabilité et la réutilisabilité.
Rhona Maxwel
@rhona_helena
"Au calme clair de lune triste et beau,
Qui fait rêver les oiseaux dans les arbres
Et sangloter d'extase les jets d'eau,
Les grands jets d'eau sveltes parmi les marbres."
Clair de lune, Paul Verlaine
En complément :
Comment éviter la loi de Conway et faciliter ainsi l’agilité avec l’approche Micro-Services ?
Estimation de la complexité d’une Architecture Micro-Services
Conseils pour réussir vos micro-services et éviter qu’ils ne se transforment en véritable pensum
Inconvénients de l'Architecture Micro-Services
L’Architecture Micro-Services expliquée à ma fille