
Agilité logicielle : quelle solution pour diminuer le couplage entre sous-systèmes et obtenir une architecture logicielle agile ?
Des plus petites aux plus grandes entreprises, le concept de bounded context est aujourd’hui au cœur de la conception d’architecture logicielle, mais se pose l’éternelle question de quelle méthode pour parvenir à un découpage produisant le couplage le plus faible, augmentant ainsi l’évolutivité, l'autonomie et l'agilité.

Evolution de l'architecture logicielle
Dans notre article consacré au livre Urbanisation, SOA et BPM, l’auteur Yves Caseau, insiste sur l’urbanisation fractale ou comment appliquer récursivement les mêmes principes à différentes échelles du SI. En effet, les concepts, comme les “General Responsibility Assignment Software Principles" (GRASP) ou encore les design patterns du GoF (Gang of Four), mis en œuvre dans la conception orientée objet à toute petite échelle, se retrouvent dans les strates supérieures au niveau de l’architecture d’entreprise. Ces principes sont les gammes de l’architecte logiciel, qui s’acquièrent au plus bas niveau en programmation orienté objet et qui permettent ensuite d’avoir les bons réflexes au niveau d’un SI global.
D'après Craig Larman, ces patterns sont des “boîtes à outils mentales”, une aide à la conception à petite ou à très grande échelle.
Nous appliquerons donc ces patterns au niveau architecture logicielle, afin d’obtenir un couplage faible et une forte cohésion.
De la démultiplication des critères qualité
Commençons par un problème récurrent de l’architecture logicielle qui est de pouvoir gérer l’évolutivité et la résilience. Une première idée est de multiplier les systèmes que ce soit au niveau du front-end ou du back-end. A partir de ce moment, une série de problèmes va se poser. Par exemple, comment gère-t-on les états, que choisir entre stateless et stateful ? Doit-on stocker l’état dans tous les back-ends ou bien doit-on mettre en place une solution de “sticky session” pour retrouver le système qui a enregistré l'état. Cette solution est complexe, elle utilise un équilibreur de charge (load balancer), une gestion d’identifiants supplémentaires, mais que se passe-t-il s’il tombe en panne, si le back-end contenant l’état devient surchargé ?
Faisons alors du stateless avec un cache partagé qui contiendra l’état. Si le cache tombe, on met un cluster, mais cela implique que l’on doit gérer la réplication et la cohérence des données…
C’est l’escalade presque sans fin des patterns Circuit Breaker (Disjoncteur), Bulkheads (Cloisonnement)… (voir notre article Solutions sur étagère pour la gestion des défaillances des Micro-Services)
Afin d’éviter cette course effrénée aux propriétés de qualité, il faut s’intéresser à la volumétrie de l’entreprise concernée : a-t-on besoin d’une surenchère de tels systèmes pour une entreprise de quelques dizaines d’utilisateurs ? A-t-on besoin de temps réel ? Pour la plupart des TPE ou PME, les enjeux ne justifient pas la mise en œuvre de systèmes redondants et hautement performants pour des coûts exorbitants.
Une pléthore de possibilités de découpages
Découpage par couches
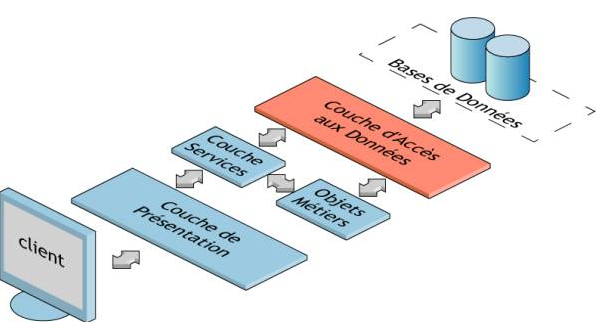
Découpage par couches
Souvent le plus utilisé, le découpage par couche, consiste à séparer l’aspect web (présentation + contrôleur), l’aspect métier (services + règles), DAO (Data Access Object) et enfin la persistance. Le nombre d’appels entre chaque couche est très important et les risques de conflits au moment des commits sont augmentés.
Découpage par technologies
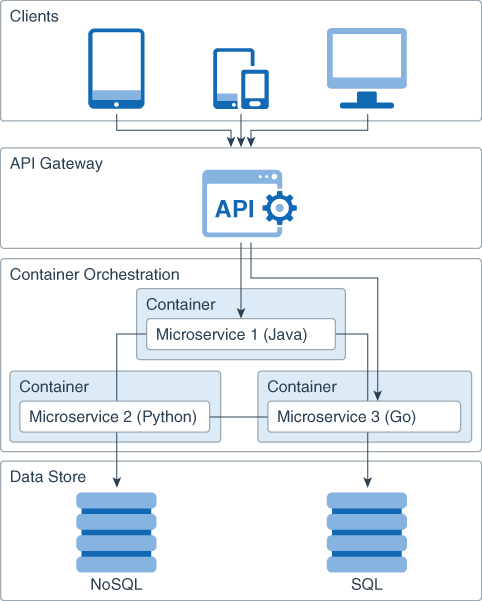
Découpage par technologies
L’exemple typique est d’avoir un existant composé par exemple d’un monolithe Java avec Jakarta EE (anciennement JEE), d’un système plus récent architecturé en micro-services avec Node.js, pour l’IA une architecture Python avec sa cohorte de bibliothèques de Machine ou Deep Learning, les référentiels avec SQL basé sur MySQL ou noSQL basé sur MongoDB… Un couplage fort sera forcément présent, par exemple entre Jakarta EE et MySQL ou Node.js et MongoDB.
Découpage entre entités
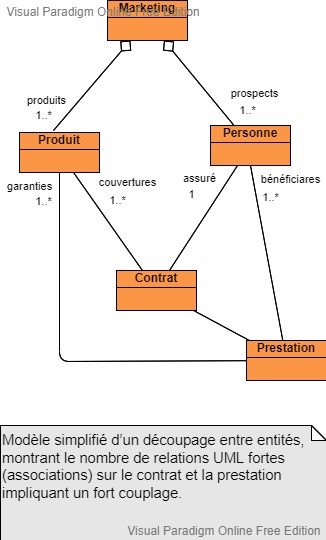
Diagramme UML de classe réalisé avec l'outil gratuit Visual Paradigm
L’architecture micro-services est souvent basée sur ce type de décomposition. A titre d’exemple volontairement simplifié, pris dans le monde assurantiel, on va trouver les micro-services Produit, Personne, Contrat, Prestation…
L’accès aux informations d’un contrat va entraîner de nombreux échanges nécessitant un fort couplage.
Pour calculer une prestation, on a besoin du contrat, de la personne…
Les entités Contrat et Prestation auront besoin de nombreuses données en provenance des entités Produit et Personne, d’où des relations fortes sous forme d’associations UML, ce qui introduit un couplage fort, une augmentation de la bande passante réseau, de CPU, sans oublier les nombreux conflits sur le SCM (Source Control Management).
Mais alors quel découpage préconisé ?
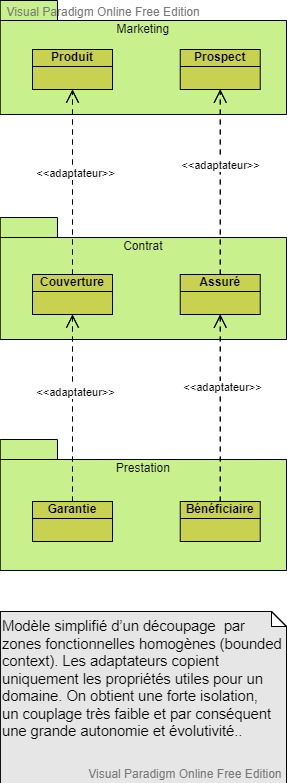
Diagramme UML de classe réalisé avec l'outil gratuit Visual Paradigm
Les décompositions précédentes présentent donc des problèmes de performances, de conflits entre les développements et un fort couplage semblable à une architecture spaghetti.
La bonne solution : le découpage par zones fonctionnelles homogènes (bounded context), regroupant des entités appartenant à un même domaine.
Reprenons notre exemple, on peut constituer 3 domaines fonctionnels homogènes : Marketing (Produit, Prospect), Contrat (Couverture, Assuré) et Prestation (Garantie, Bénéficiaire).
Dans le domaine Marketing, les entités Produit et Prospect deviennent respectivement dans le domaine Contrat, Couverture et Assuré, qui eux-mêmes deviennent Garantie et Bénéficiaire dans le domaine Prestation.
La même personne en chair en os avec la même identité est vue comme prospect dans le marketing, assuré dans le contrat et bénéficiaire dans la prestation.
De même pour un produit dans le marketing, le domaine contrat va utiliser les données de couverture et la prestation les données concernant les garanties.
Cette méthode de regroupement permet d’avoir des zones autonomes. Les liens s’implémentent par des adaptateurs chargés de recopier uniquement les données utiles d’une entité dans une autre.
Mais alors, on viole le principe de non-duplication de données ?
Les adaptateurs copient uniquement les propriétés utiles pour un domaine, c’est le prix à payer pour avoir une forte isolation, un couplage très faible et par conséquent une grande autonomie et évolutivité.
Cette duplication des données se retrouve partout dans la vraie vie, par exemple dans les réseaux sociaux : on a un ami sur Facebook, un candidat sur LinkedIn, un commiter sur Github, un collaborateur sur Slack… Ces différentes plateformes gèrent avec leur propre sémantique la même personne, mais adaptée à leurs objectifs et peuvent partager le même identifiant permettant de se connecter avec un ID Google ou Facebook par exemple.
Le pouvoir de choisir la technologie la plus adaptée
Autre avantage d’une bonne découpe, c’est de pouvoir choisir la technologie la plus adaptée
Prenons l’exemple de la persistance :
- Domaine Marketing regroupant les produits et les prospects : NoSQL favorisant les recherches rapides sur de gros volumes en lecture.
- Domaine Contrat : RDBMS (Relational Database Management System) SQL, pour les aspects transactionnels.
- Domaine Prestation : RDBMS SQL ou Cassandra NoSQL conçu pour gérer des quantités massives de données sur un grand nombre de serveurs, assurant une haute disponibilité en éliminant les points de défaillance unique.
Conclusion
Ce concept de bounded context est de plus en plus considéré et mis en œuvre dans les entreprises et fait partie du DDD Domain Driven Design (voir nos articles Les couches de l'Architecture Microservices et la méthode de conception DDD (Domain Driven Design) et Architecture Hexagonale, exemple de mise en pratique de la méthode DDD Domain Driven Design).
La difficulté consiste à bien délimiter les contours. Pour les identifier, il faudra alors faire appel à l’expérience et à des heuristiques propres.
|
|
Rhona Maxwel @rhona_helena |
“Apprendre à penser, à réfléchir, à être précis (…), à écouter l’autre, c’est être capable de dialoguer, c’est le seul moyen d’endiguer la violence effrayante qui monte autour de nous. La parole est le rempart contre la bestialité.”
Jacqueline de Romilly
Compléments de lecture
- L’Architecture Micro-Services expliquée à ma fille
- Inconvénients de l'Architecture Micro-Services
- Orchestration des micro-services avec BPMN
- Conseils pour réussir vos micro-services et éviter qu’ils ne se transforment en véritable pensum
- Estimation de la complexité d’une Architecture Micro-Services
- Solutions sur étagère pour la gestion des défaillances des Micro-Services
- Comment éviter la loi de Conway et faciliter ainsi l’agilité avec l’approche Micro-Services ?
- Les couches de l'Architecture Microservices et la méthode de conception DDD (Domain Driven Design)
- Architecture Hexagonale, exemple de mise en pratique de la méthode DDD Domain Driven Design
- Urbanisation, SOA et BPM d’Yves Caseau
A découvrir aussi
- Solutions sur étagère pour la gestion des défaillances des Micro-Services
- Les couches de l'Architecture Microservices et la méthode de conception DDD (Domain Driven Design)
- Architecture Hexagonale, exemple de mise en pratique de la méthode DDD Domain Driven Design
Inscrivez-vous au site
Soyez prévenu par email des prochaines mises à jour
Rejoignez les 840 autres membres