
Autonomic Computing ou Informatique Autonome, est-elle une informatique visionnaire ?
L'informatique autonome aide à réduire la complexité en utilisant la technologie pour gérer la technologie. Dans cet environnement, les systèmes sont capables de s’adapter dynamiquement au changement des politiques métier.
Les enjeux de l'Informatique Autonome.
Similaire au corps humain ?
Le terme autonome est dérivé de la biologie humaine. Inconsciemment, le système nerveux autonome surveille votre rythme cardiaque, vérifie votre niveau de glycémie et maintient votre température corporelle proche de 37 °C, sans aucun effort de votre part.
De la même manière, l'informatique autonome anticipe les exigences du système informatique et résout les problèmes sans intervention humaine. Les professionnels de l'IT peuvent se concentrer sur des tâches à plus forte valeur ajoutée pour l'entreprise.
Cependant, il existe une distinction importante entre l'activité autonome dans le corps humain et les activités autonomes dans les systèmes informatiques : de nombreuses décisions faites par les capacités autonomes du corps humain sont involontaires. En revanche, les capacités autonomes dans les systèmes informatiques effectuent des tâches que les informaticiens choisissent de déléguer à la technologie, conformément à la gouvernance en place.
Un moteur de règles, plutôt qu'une procédure codée en dur, détermine les types des décisions et des actions que les composants autonomes effectuent.
Introspection
Le système autonome se connaît :
- Il connaît ses composants, leurs spécifications, leurs capacités et leurs états en temps réel.
- Il a également des connaissances sur ses ressources propres, empruntées et partagées.
- Il peut se configurer encore et encore et exécuter sa configuration automatiquement
au fur et à mesure des besoins. - Il a la capacité de s'optimiser en ajustant les flux de travail.
- Il peut se réparer, il peut se remettre des échecs.
- Il peut se protéger en détectant et en identifiant diverses attaques à son encontre.
- Il peut s'ouvrir. Cela signifie qu'il ne doit pas s'agir d'une solution propriétaire
et doit implémenter des standards ouverts. - Il est invisible. Cela signifie qu'il a la capacité de permettre l'optimisation des ressources,
en masquant sa complexité.
Un système autonome, selon IBM, doit être capable de savoir ou d'anticiper le type de demande qui va survenir pour ses ressources.
Les capacités d'auto-gestion d'un système accomplissent leurs fonctions, en prenant une action appropriée selon une ou plusieurs situations qu'ils perçoivent dans l'environnement. La fonction de toute capacité autonome est une boucle de contrôle, qui collecte les détails du système et agit en conséquence.
Ces boucles de contrôle sont organisées en quatre catégories : auto-configuration, auto-réparation, auto-optimisation et auto-protection.
Auto-configuration
Les composants auto-configurables s'adaptent dynamiquement aux changements de l'environnement, en utilisant les règles fournies par les informaticiens.
De tels changements pourraient inclure le déploiement de nouveaux composants ou la suppression de ceux existants, ou des changements importants dans les propriétés du système. L'adaptation dynamique assure une productivité constante de l'infrastructure informatique, ce qui entraîne une croissance et une grande flexibilité de l'entreprise.
Auto-réparation
Cette propriété permet de découvrir, diagnostiquer et réagir aux perturbations.
Les composants d'auto-réparation peuvent détecter les dysfonctionnements du système et initier des actions correctives basées sur des règles, sans perturber l'environnement informatique. Une action corrective peut impliquer qu'un composant modifie son propre état ou effectue des changements sur les autres.
Le système dans son ensemble devient plus résilient, parce que les opérations quotidiennes sont moins susceptibles d'échouer.
Auto-optimisation
Les ressources sont surveillées et réglées automatiquement pour une efficience optimale.
Les composants d'auto-optimisation peuvent s'adapter pour répondre à l'utilisateur final ou aux besoins de l'entreprise. Les actions de réglage peuvent être la réallocation des ressources - par exemple en réponse à des augmentations des charges de travail - pour améliorer les temps de réponse des processus métier.
Auto-protection
Les menaces sont anticipées, détectées, identifiées et les parades sont mises en place.
Les composants auto-protégés peuvent détecter des comportements suspects au fur et à mesure qu'ils se produisent et prendre des contre-mesures, pour se rendre moins vulnérables par exemple aux accès non autorisés, à l'infection et à la prolifération de codes malveillants, ainsi que les attaques par déni de service.
Les capacités d'auto-protection permettent aux entreprises d'appliquer systématiquement des politiques de sécurité et de confidentialité.
Intégration dans ITIL
Les entreprises informatiques organisent ces tâches sous la forme d'un ensemble de meilleurs pratiques et processus, tels que ceux définis dans ITIL (Information Technology Infrastructure Library).
Traditionnellement, la détection d’un dysfonctionnement nécessite la mise en œuvre d’une procédure fastidieuse : il faut créer la demande de correction, recueillir les détails de l'incident et suivre l’évolution de l’état du ticket d’anomalie sur une plateforme.
Dans un système auto-géré, les composants peuvent initier ces étapes en fonction des informations provenant directement du système. Cela aide à réduire les tâches manuelles et le temps nécessaire pour répondre aux situations critiques.
Dans un processus de gestion des problèmes, une des étapes est le diagnostic. Dans les systèmes auto-gérés, les ressources sont créées telles que l'expertise requise pour effectuer cette tâche puisse être encodée dans le système et ainsi puisse être automatisée.
La plus-value client
L'efficience des processus informatiques typiques est mesurée à partir du temps écoulé pour terminer un processus, le pourcentage exécuté correctement et le coût d'exécution d'un processus.
Les systèmes auto-gérés peuvent affecter positivement ces métriques, améliorant la réactivité et la qualité de service, en réduisant le coût total de possession (TCO) et en améliorant le délai de rentabilité.
L'informatique autonome est nécessaire pour surmonter le problème de la complexité accrue :
- des systèmes distribués, dont les prévisions tablent sur une croissance de 40 % par an,
- des applications qui doivent s'adapter au travail en distanciel.
Architecture de l'Autonomic Computing
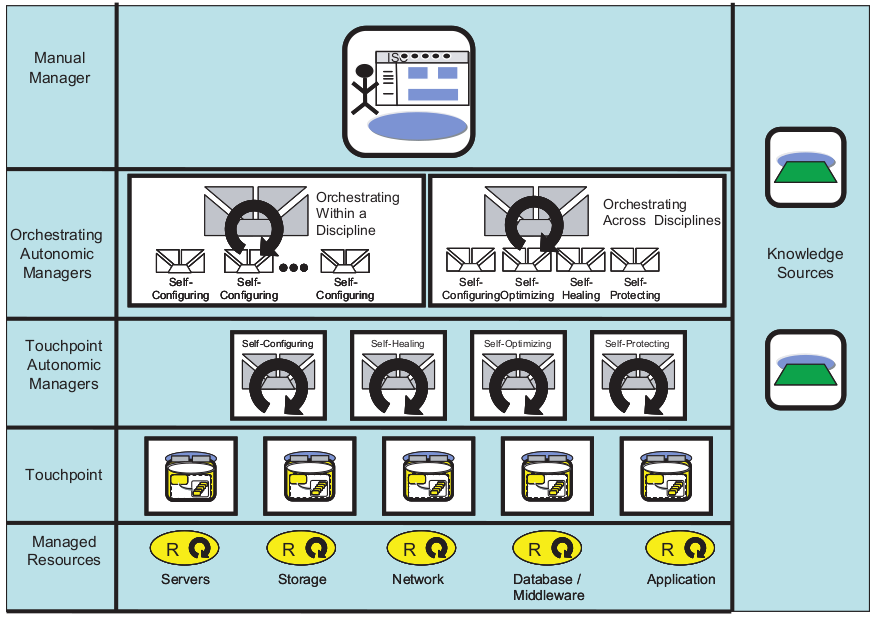
Les couches de l'Architecture de l'Autonomic Computing
L'architecture AC (Autonomic Computing) comprend des propriétés qui permettent l'auto-gestion selon divers fournisseurs, en impliquant des boucles de contrôle qu'un fournisseur de ressources intègre dans l'environnement d'exécution.
- Éléments gérés (Managed Resources) : l'élément géré est un composant du système contrôlé. Il peut s'agir aussi bien d'une ressource matérielle que d'une ressource logicielle. Des capteurs et des effecteurs sont utilisés pour contrôler l'élément géré.
- Capteurs (Touchpoint) : fournissent des informations sur l'état et tout changement d'état
des éléments du système autonome. - Effecteurs (Touchpoint Autonomic Managers) : ce sont des commandes ou interfaces de programmation d'applications (API) qui sont utilisées pour changer les états d'un élément.
- Gestionnaire autonome (Orchestrating Autonomic Managers) : utilisé pour s'assurer que les boucles de contrôle sont mises en œuvre. Celui-ci divise la boucle en 4 parties pour son fonctionnement. Ces parties sont : surveiller, analyser, planifier et exécuter -
MAPE (Monitor, Analyze, Plan, Execute). - Interface Utilisateur (Manual Manager) : l'environnement d'exécution est configuré à l'aide d'une interface de gestion fournie pour chaque ressource, par exemple des moyens de stockage.
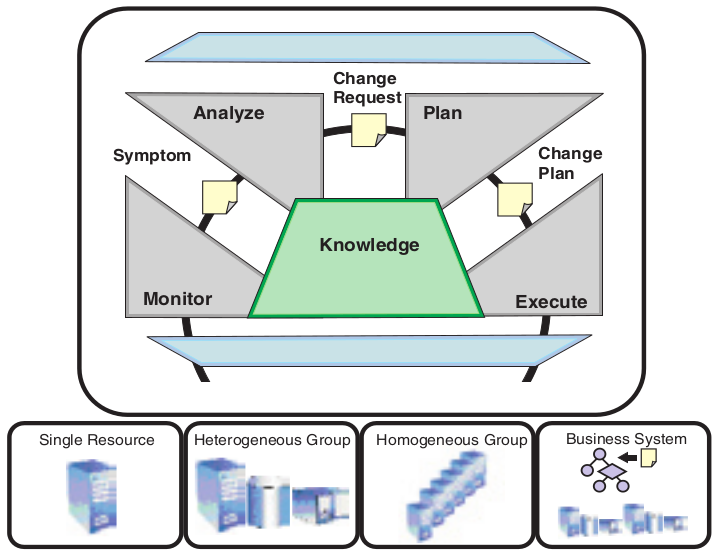
Architecture MAPE (Monitor, Analyze, Plan, and Execute) : surveiller, analyser, planifier et exécuter
Exemples
- Exécution d'une tâche d'auto-configuration telle que l'installation d'un logiciel
lorsqu'il détecte que certains logiciels prérequis sont manquants. - Exécution d'une tâche d'auto-réparation telle que la correction d'un chemin configuré
afin que les logiciels installés puissent être correctement localisés - Exécution d'une tâche d'auto-optimisation telle que l'adaptation de la CPU
lorsqu’elle constate une augmentation des transactions. - Exécuter une tâche d'auto-protection telle que mettre des ressources hors ligne
en cas de détection d’une tentative d'intrusion.
Conclusion
L'Autonomic Computing nécessite 3 conditions :
- Automatique : le système doit pouvoir exécuter ses opérations sans intervention humaine.
- Adaptatif : les ordinateurs autonomes doivent pouvoir apporter des modifications en fonction de leur environnement et d'autres conditions imprévues, telles que les attaques de sécurité et les pannes du système.
- Conscient : il doit également avoir connaissance des processus et des états internes
qui permettraient d'exécuter les deux fonctionnalités précédentes.
Avantages
- Open Source
- C'est une technologie évolutive qui s'adapte aux nouveaux changements.
- Donne donc une meilleure efficacité et de meilleures performances.
- Sécurisé, peut contrer automatiquement des attaques.
- Dispose de mécanismes de sauvegarde qui permettent la récupération après les pannes
et le plantage du système. - Réduit le coût de possession (TCO) d'un tel mécanisme, car il est moins sujet aux pannes
et peut se maintenir automatiquement. - Il peut se configurer lui-même, réduisant ainsi le temps nécessaire
à la configuration manuelle.
Inconvénients
- Il y aura toujours une possibilité de plantage ou de dysfonctionnement du système.
- Impact sur l'emploi pour certaines professions.
- Le système coûte plus cher.
- Besoin de compétences hautement qualifiées pour gérer ou développer de tels systèmes, augmentant ainsi le coût pour l'entreprise qui les emploie.
- Dépendant de la bande passante réseau et donc pas forcément disponible partout.
|
|
Rhona Maxwel @rhona_helena |
"Sur tous les sujets, des opinions contradictoires se font face, et la plupart d’entre nous n’ont pas les outils nécessaires pour savoir laquelle est la bonne."
Yuval Noah Harari
Compléments de lecture
- L’Architecture Micro-Services expliquée à ma fille
- Inconvénients de l'Architecture Micro-Services
- Orchestration des micro-services avec BPMN
- Conseils pour réussir vos micro-services et éviter qu’ils ne se transforment en véritable pensum
- Estimation de la complexité d’une Architecture Micro-Services
- Solutions sur étagère pour la gestion des défaillances des Micro-Services
- Comment éviter la loi de Conway et faciliter ainsi l’agilité avec l’approche Micro-Services ?
- Les couches de l'Architecture Microservices et la méthode de conception DDD (Domain Driven Design)
- Architecture Hexagonale, exemple de mise en pratique de la méthode DDD Domain Driven Design
- Agilité logicielle : quelle solution pour diminuer le couplage entre sous-systèmes et obtenir une architecture logicielle agile ?
- Urbanisation, SOA et BPM d’Yves Caseau
A découvrir aussi
- 10/11 Projet informatique, passer du moyen âge à l'ère industrielle. Ne jouez pas perso, travaillez en équipe.
- 11/11 Projet informatique, passer du moyen âge à l'ère industrielle. Devenez parano en vérifiant chaque jour votre développement logiciel avec l'intégration en continue.
- Avec toutes les nouvelles techniques de RIA (Rich Internet Application), y a de quoi y perdre son Java !
Inscrivez-vous au site
Soyez prévenu par email des prochaines mises à jour
Rejoignez les 840 autres membres