
Les étapes d’un projet avec un moteur de règles
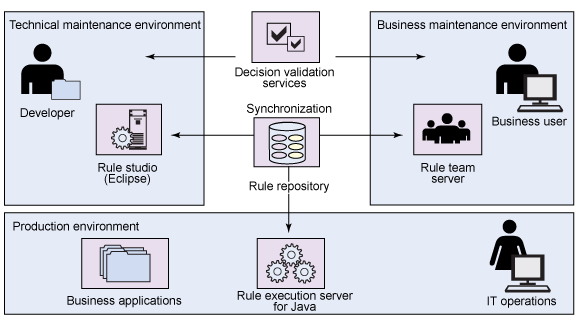
Utiliser un moteur de règles (BRMS Business Rules Management System) va dans le sens de l'urbanisation des SI dont l'objectif est de rendre le SI flexible et évolutif. Mais quelles sont les étapes à réaliser pour mettre en œuvre un moteur de règles ?
La première étape est la phase de conception qui consiste à :
. paramétrer le moteur de règles
. définir les concepts métier (diagramme de classes UML) et le langage utilisé pour les règles
. définir les objets physiques et les liens avec le modèle métier
. définir le modèles de règles
La deuxième étape consiste à écrire les règles par l’équipe de développement dans un premier temps puis par l’expert métier ensuite, à tester les règles et à les valider.
La troisième étape représente la phase de maturité. On met en place les processus de modification, ajout et suppression de règles. On s'appuie sur des données existantes dans le SI. L’utilisateur métier est autonome. Si le modèle de données évolue alors l’intervention de l’équipe de développement est alors nécessaire.
La quatrième étape a pour but d'intégrer le moteur dans l'application avec par exemple l'utilisation native du langage Java, l'Intégration dans l’architectures cible choisie (COBOL ou Java).
Les prérequis et contraintes sont :
. la couche d’objets « métier » doit être suffisamment stable avant d’écrire les règles.
. les première phases d’écriture de règles sont à réaliser par un développeur, puis le transfert doit être progressif vers l’utilisateur « métier ».
Le point critique d’un projet BRMS concerne le développement de tout ce qui va être exposé aux utilisateurs « métier », c’est à dire :
. le langage « métier » utilisé,
. l’élaboration de modèles et d’autres fonctions connexes comme des tests de non-régression ou des aides au débogage.
. la criticité vient principalement du niveau technique des utilisateurs « métier » concernés.
Si trop de liberté est laissée et que les utilisateurs ne sont pas assez formés, le système peut devenir instable, incompréhensible et donc ne pas remplir du tout ses objectifs d’amélioration de d’évolutivité du système, les utilisateurs ayant systématiquement besoin de l’assistance de l’équipe informatique.
À l’inverse, si le système est trop contraint, les utilisateurs ne pourront pas forcément exprimer toutes les règles qu’ils souhaiteraient. Dans ce cas, soit les utilisateurs cessent d’utiliser le système, soit les demandes à l’équipe informatique se multiplient.
Un bon conseil, n'hésitez pas à réaliser un POC avec comme objectifs de concevoir la méthode, les modèles et la granularité des règles, de former quelques développeurs et experts métiers, de communiquer avec pédagogie à l'ensemble des acteurs projet y compris la direction générale et la DSI. Puis faites une première itération ou seul les développeurs vont écrire les règles. Les processus d'intégration, d'exploitation, de tests et de cycle de vie des règles doivent être validés. Profitez-en pour mesurer les temps de développement et autres charges pour affiner votre retour sur investissement.
Voir aussi : Les bonnes pratiques de SI
A quoi sert un moteur de règles ?

On entends souvent parler dans le cadre de l'urbanisation des SI, de la gestion des processus métier (BPM Business Process Management) associée à un moteur de règles métiers (BRMS Business Rules Management System). Mais qu'est-ce exactement un moteur de règles ?
Mais d'abord qu’est-ce qu’une règle ?
Une règle est composée d’un ensemble de conditions et d’un ensemble d’actions exécutées uniquement si les conditions précédentes sont réunies.
Si un ensemble de conditions est vrai…
… alors on exécute un ensemble d’actions
Exemple :
Si un évènement initial avec une personne sinistrée dont le type n’est ni assuré, ni conjoint
Alors créer un évènement métier bloquant avec un message.
Objectifs d'un moteur de règle :
. La formalisation sous forme de règles permet de capitaliser et d’automatiser le savoir-faire des experts
. Apporte une standardisation et une auditabilité de ces règles « métier », facilitant leur consultation et leur maintenance par le plus grand nombre
. Evite d’écrire un analyseur syntaxique.
. La sémantique d’une règle standard (« Si ….Alors … ») est particulièrement bien adaptée à ce que l’on peut trouver dans les réglementations ou dans les spécifications, ce qui permet d’avoir des délais de mise en œuvre et de validation plus courts que pour un projet écrit dans un langage classique, le passage de la spécification aux règles étant naturel.
. Les règles sont donc beaucoup plus lisibles que du code COBOL ou Java. Le raisonnement global complexe est ainsi décomposé en règles simples et lisibles (au moins autant qu’un document de spécifications), et non noyées dans un code source complexe compréhensible uniquement par des informaticiens (voire de l’informaticien qui l’a écrit)
. Fournir un environnement d’édition des règles utilisable simplement et directement par des experts « métier » sans compétences informatiques particulières.
. Permet de faciliter la maintenance évolutive, grâce à la lisibilité des règles, et induit donc une meilleure réactivité et adaptation aux changements.
. Le codage et la validation des nouvelles règles sont plus rapides à effectuer et plus aisées à mettre en œuvre, les utilisateurs font moins appel aux services informatiques.
. Conçus pour séparer la logique « métier » (la formalisation des règles, en utilisant directement les concepts « métier ») de la logique système (la mise en œuvre technique).
. Permet d’exprimer ce qu’on veut faire (langage déclaratif) et non pas comment on le fait (langage impératif)
. Rapidité et dimensionnement (algorithme RETE) pour trouver les règles en fonction des entités métiers.
On verra dans un prochain article quelles sont les étapes d’un projet avec un moteur de règles.
Intégrer un moteur de règles est une véritable révolution dans le SI mais il contribue pleinement aux enjeux de l'urbanisation des SI qui est de faire évoluer les entreprises plus rapidement et puis n'oublions pas qu'un changement dans notre environnement peut nous dynamiser.
Voir aussi : http://bonnes-pratiques-si.eklablog.com/
Quelle est l'étape la plus importante dans l'urbanisation des SI ?

Trop souvent négligé par les DSI dans le plan d'urbanisation, la conduite du changement est cependant capitale pour la réussite du processus.
Examinons tout d'abord les changements introduits par l'urbanisation des SI.
L'expression des besoins représentée par les processus métier transverses modifient considérablement le travail des informaticiens habitués à une organisation verticale par projet.
Les concepts techniques nouveaux comme les ESB (Enterprise Service Bus), le BPM (Business Process Management), les langages de modélisation comme BPMN (Business Process Modeling Notation) ou UML (Unified Modeling Language), les outils d'exploitation de type BAM (Business Activity Monitor), les web services, ... deviennent le socle de toute l'architecture globale d'entreprise.
Quelles sont alors les solutions pour résorber un tel choc culturel ?
L'établissement d'un réseau informel constitué d'interlocuteurs permet à chacun de partager ses réticences et ses craintes et de s'approprier les concepts de l'urbanisation des SI.
Le processus d'urbanisation des SI implique une réorganisation permettant de motiver les acteurs et donner leurs chances aux nouvelles idées.
La peur du changement est un facteur humain important et sa prise en compte peut s'opérer par la résorption du stress des collaborateurs en autorisant le droit à l'erreur. Une bonne pratique est de créer des pépinières permettant de se libérer, de tester de nouvelles technologies, des méthodes, de mettre en pratique les concepts de l'urbanisation des SI avec suffisamment de temps pour y arriver. Les objectifs doivent être aisément atteignables.
La réalisation de POC (Proof Of Concept) avec des processus simple, des pilotes sur des projets non stratégiques permettent d'appréhender les concepts et d'affiner les techniques.
On ne dira jamais assez toute l'importance de la documentation, tout ce qui a été fait, en cours de réalisation ou ce qui est prévu doit être détaillé de manière pédagogique. Les documents doivent être autosuffisants, une personne ne connaissant pas le sujet doit trouver toutes les réponses à ses questions.
Avoir une bonne trajectoire d'urbanisation de SI créée par des urbanistes et architectes ne suffit pas, encore faut il que les opérationnels soient à la hauteur. Car au final, comme toujours seul compte l'exécution.
Ne pas lésinez sur les formations. Les plans de formation doivent être conçus à l'avance avec les objectifs pédagogiques, les moyens pour y arriver, la méthode de vérification des acquis et le suivi. La bonne pratique est de plutôt privilégier la formation en interne permettant d'expliquer les raisons spécifiques à l'entreprise qui ont poussé à la démarche d'urbanisation de SI.
Le succès du plan d'urbanisation du SI passe par l'implication, l'appropriation et l'acceptation de tous les acteurs de l'entreprise. Une communication puissante accompagnée d'une bonne dose de pédagogie avec le soutien de la direction générale doit être mis en avant à contrario on verrait nos efforts et nos investissements périclités.
Voir aussi : http://bonnes-pratiques-si.eklablog.com/
11/11 Projet informatique, passer du moyen âge à l'ère industrielle. Devenez parano en vérifiant chaque jour votre développement logiciel avec l'intégration en continue.
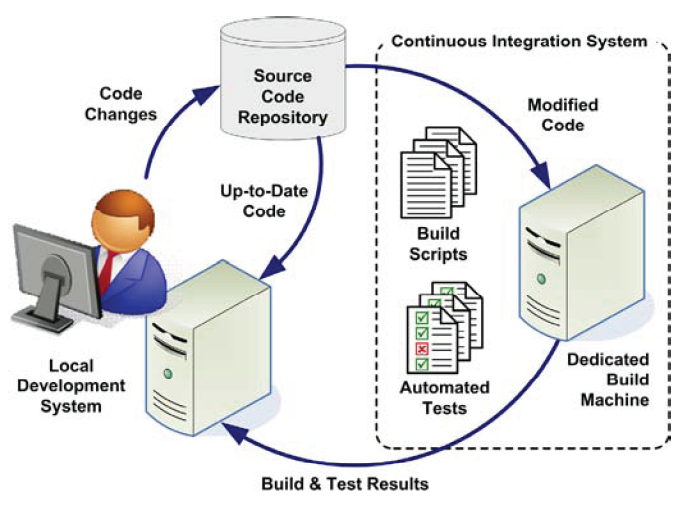
N'attendez surtout pas que les développements soient commencés pour mettre en place la plate forme d'intégration continue car vous risqueriez de "brûler du gaz" pour rien. Au contraire investissez dés le départ et soyez audacieux et innovateur, ce sont les clés du retour sur investissement.
En fait l'objectif c'est de rechercher la sérénité. En effet en investissant au départ dans les vérifications automatiques journalières c'est pouvoir dormir comme un bébé chaque nuit.
Chaque évolution ou modification du code peut engendrer des régressions. N'est il pas rageant de s'apercevoir qu'une fonctionnalité complexe difficile à mettre au point et dûment testée ne marche plus ! L'automatisation des tests de régression exécutés au moins une fois par jour permet de voir au plus tôt ce qui ne va pas et empêche d'ajouter des nouvelles fonctionnalités qui ne feraient qu'aggraver la situation.
Mais que doit faire la plate forme?
Tout d'abord récupérer le code source, depuis le dépôt qui est la plupart du temps un outil de gestion de source (CVS, SVN, Git, SourceSafe, …).
Ensuite vérifier et optimiser le code par des outils d'audit (voir mon article : 9/11 Projet informatique, passer du moyen âge à l'ère industrielle. Comment vérifier que les développeurs n'ont pas mijoté un plat de spaghetti ? (qualité du code, audit, style, ...)
Bien évidement, il faut compiler des sources. Si un projet ne peut pas être compilé complètement, il faut remonter rapidement l’information, pour que le code problématique soit corrigé. Un projet qui ne compile pas peut bloquer l’ensemble des développeurs qui travaillent dessus.
Puis passer les tests unitaires et générez un rapport avec les messages liés aux tests en échecs.
Préparer les artefacts de déploiement de manière à ce que l'application puisse être exécutée dans l'environnement cible.
Déployer l’application sur le serveur d'application cela peut se résumer à une simple copie des artefacts de déploiement. Tous les fichiers de log doivent être activés pour pouvoir analyser si besoin est les erreurs de déploiement. Ce qui parfois peut se révéler difficile à réaliser tellement les facteurs peuvent être nombreux.
On termine par les tests fonctionnels correspondant aux Use Case. Un rapport structuré doit être généré.
Et qu'est ce qu'on oublie ? La génération automatique de la documentation de développement, qui est faite à partir des informations présentes dans le code source. C'est toujours plus facile de développer quand on a sous la main une version à jour de la documentation.
À la fin de l’exécution de toutes ces actions, la plate-forme doit envoyer des messages aux personnes concernées par les problèmes relevés. Ces messages ne doivent pas se transformer en spam, car ils deviendraient inutiles (personne n’y ferait plus attention). Il faut donc faire attention à remonter les vrais problèmes, et ne pas mettre tous les développeurs en copie sauf dans les cas nécessaires.
La résolution des bugs remontés doit être lapriorité première d’une équipe de développement. C’est simple, si on continue à développer en sachant qu’il y a des bugs, on sait pertinemment qu’il faudra encore plus de temps et d’énergie pour les corriger, tout en risquant de devoir refaire les « sur-développements ».
En bout de course, l’application déployée par l’intégration continue doit être accessible à l’équipe de test, qui peut ainsi procéder à ses vérifications complémentaires sans avoir à se soucier des étapes techniques en amont (compilation, packaging, déploiement).
Mettre en place une plate-forme d’intégration continue est un tâche technique assez longue. Mais une fois que c’est fait, c’est à la fois un confort de travail et une sécurité dont on ne peut plus se passer.
L’écriture des tests unitaire est quelque chose d’un peu fastidieux, qu’il est souvent difficile d’imposer à une équipe qui a pris de mauvaises habitudes. Un développeur ne voit souvent le code source comme seul élément constitutif de son travail, et oublie la documentation et les tests. Encourager l’écriture de tests unitaire est un travail de longue haleine sur lequel il faut maintenir une pression constante, sous peine de laisser prendre la poussière. Et un test qui n’est pas tenu à jour devient rapidement inutile.
N'attendez surtout pas que les développements soient commencés pour mettre en place la plate forme d'intégration continue car vous risqueriez de "brûler du gaz" pour rien. Au contraire investissez dés le départ et soyez audacieux et innovateur, ce sont les clés du retour sur investissement.
Voir aussi : Bonnes pratiques des SI
10/11 Projet informatique, passer du moyen âge à l'ère industrielle. Ne jouez pas perso, travaillez en équipe.
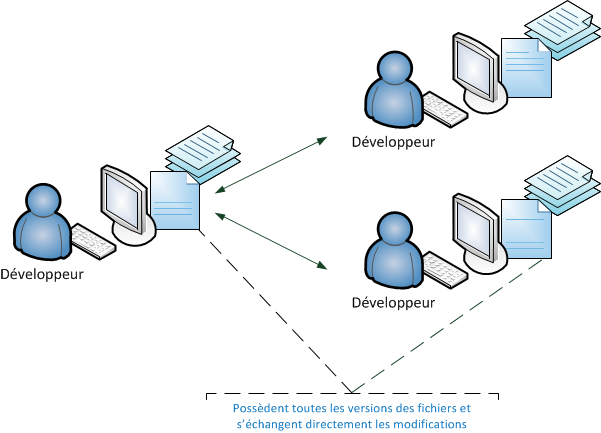
Pendant les phases d'inception et d'élaboration des méthodes UP (Unified Process), la discipline "Environnement" permet la mise en place des outils pour l'ensemble des acteurs du projet. Un logiciel de type GCL (Gestionnaire de Configuration Logiciel) ou VCS (Version Control System) a pour but de partager les sources, de gérer des versions et d'éventuels conflits dans un même bloc de code. Il y a quelques années, pour un projet de gestion de clients, j'étais intervenue pour mettre en place une nouvelle méthode de gestion de projet s'appuyant sur UP. Je formais alors les différents profils, chef de projet, experts métier, analystes et développeurs aux concepts d'itération, de gestion du changement, de phases et disciplines du processus unifié, de la modélisation UML, des processus métier, des Use Case, de la méthode d'estimation basée sur les UC... Une des priorités étant de valider l'architecture, j'avais recommandé Eclipse comme IDE (Environnement de Développement Intégré) ainsi que de mettre tout de suite un serveur avec Subversion qui était à l'époque le standard open source des GCL. Mais le client à ses raisons que le consultant ne connaît pas. L'outil de développement retenu fut jDeveloper d'Oracle et la mise en place de la gestion de versions fut différée pour des problèmes internes. Le projet était composé de 2 équipes de développeurs l'une à Paris et l'autre à Dijon. La "réseautique" devait installé une nouvelle ligne et configurer les firewalls pour gérer la sécurité. J'alertais sur le fait qu'il y aurait un gros risque pour recentraliser tous les sources de Paris et Dijon dans 6 mois, qu'il y aurait des conflits et d'énormes différences ingérables manuellement. Malgré ma désapprobation le projet démarra sans GCL ! Je structurais alors les fonctionnalités entre le sites de Paris et Dijon dans des domaines fonctionnels indépendants et les répartis entre Paris et Dijon. Les interdépendances furent bouchonnées. . Voilà vraiment la chose à ne pas faire, laissez 5 développeurs produire du code sans gestion de version. Le client aurait du mettre en place le système de GCL dés l'étude de faisabilité du projet.
Les GCL permettent de mettre à jour ses sources à partir des modifications des autres développeurs. Et réciproquement d'enregistrer ses propres modifications pour qu'elles puissent être récupérées par l'équipe Le référentiel peut être distribué, c'este cas des outils les plus modernes comme Git (développé par Monsieur Linux Linus Torvald en personne). A partir de la version courante de l'application, celle qui évolue, appelée trunk, on peut sauvegarder des clichés(tags) correspondants par exemple à des versions stables livrées, on peut créer des branches à partir du trunk qui suivront leurs propres évolutions pour des clients différents. Lorsque 2 développeurs modifient le même bloc de code par exemple simultanément, il y a alors conflit. Tous les commits seront représentés entourés de marqueurs, il s'agira alors pour un développeur de trancher en validant une version du code et en supprimant les autres. On doit pouvoir accéder à un historique complet de tous les commits effectués et éventuellement pouvoir revenir à une ancienne version ou annuler le dernier commit.
La grande nouveauté dans les GCL réside dans la distribution du référentiel (DVCS en anglais pour Distributed Version Control Systems). Dans un DVCS (tel que Git, Mercurial, Bazaar ou Darcs), les clients n'extraient plus seulement la dernière version d'un fichier, mais ils dupliquent complètement le dépôt. Ainsi, si le serveur disparaît et si les systèmes collaboraient via ce serveur, n'importe quel dépôt d'un des clients peut être copié sur le serveur pour le restaurer. Chaque extraction devient une sauvegarde complète de toutes les données. De plus, un grand nombre de ces systèmes gère particulièrement bien le fait d'avoir plusieurs dépôts avec lesquels travailler, vous permettant de collaborer avec différents groupes de personnes de manières différentes simultanément dans le même projet. Cela permet la mise en place de différentes chaînes de traitement qui ne sont pas réalisables avec les systèmes centralisés, tels que les modèles hiérarchiques.
Comme le préconise les méthodes UP, l'architecture et l'environnement doivent être stabilisés dés les premières phases d'initialisation et d'élaboration. Le système de gestion de version doit être opérationnel immédiatement, sinon gare à la facture salée du rattrapage manuel.
Voir aussi : http://bonnes-pratiques-si.eklablog.com/
9/11 Projet informatique, passer du moyen âge à l'ère industrielle. Comment vérifier que les développeurs n'ont pas mijoté un plat de spaghetti ? (qualité du code, audit, style, ...)

La méthodologie de gestion d'un projet informatique doit inclure les aspects normes et stratégie de codage. Sinon l'arnarchie va régner, chaque développeur aura sa propre manière d'indenter son code, de nommer les classes, les attributs, les méthodes (anglais, français, ...), les paramétres, les variables locales, ...
Chacun aura ses patterns de code, utiliser une boucle "for"(C, C++, Java, C#, ...) infinie et tester une condition à l'intérieure pour en sortir plutôt qu'un "for" classIque. Les développeurs c'est comme les écrivains, chacun a son style propre et on peut reconnaître son auteur sans regarder la signature. L'erreur chronophage et quasi systématique c'est la duplication de code. Tout développeur qui se respecte sait qu'il ne doit pas faire du copier/coller pour des problèmes évidents de maintenance, de lisibilité, d'impacts en cas de modifications, ... Les conceptions génériques coûtent toujours un peu plus chéres au départ mais on y gagne énormément en évolutivité, réutilisabilité et maintenabilité. Vous aurez beau dire qu'il ne faut pas le faire, il se peut que dans une situation d'urgence, pris par le stress, le développeur le fasse quand même en se disant qu'il modifiera à l'itération suivante, ce qui ne sera bien sur jamais fait car dans un projet les "TODO" s'accumulent vite et les impondérables aussi. Des alertes sur du code complexe peuvent être mises en œuvre. Le paramétrage de métriques concernant la taille des classes et des méthodes permet de déceler les parties de codes qui doivent être refactorées. Les outils peuvent aussi détecter de manière statique les mauvaises pratiques de codage, le code "mort", les expressions sous optimisées. Le chef de projet doit demander à l'architecte technique de mettre en place des outils d'audit comme Checkstyle ou PMD facilement intégrables et configurables dans les IDE comme Eclipse. Un autre concept, est d'analyser le byte code généré par le compilateur. C'est la philosophie choisie par FindBugs. Ce puissant outil permet de trouver des bogues potentiels, des problèmes de performances, ou des mauvaises habitudes de codage. FindBugs est le résultat d’une recherche menée par Bill Pugh à l’université du Maryland, et qui étudie les modèles de byte code venant de bogues dans de réels grands projets, comme les JDKs, Eclipse, ou le code source d’applications Google. FindBugs peut détecter des problèmes assez importants tels que des exceptions de pointeurs nuls, des boucles infinies, et un accès non intentionnel de l’état interne d’un objet.
Pour la qualité, la lisibilté, l'évolutivité, la réutilisabilité, la maintenabilité et les performances du code source il est vivement conseillé d'activer ces outils sans attendre les premiers développements. Si on se base sur la méthode UP (Unified Process) l'installation des outils et leurs paramétrages relévent de la discipline Environnement au début de la phase Élaboration.
Mieux vaut donc anticiper l'audit de code à moins que les plats de spaghettis soient votre spécialité.
Voir aussi le site :
http://bonnes-pratiques-si.eklablog.com/
8/11 Projet informatique, passer du moyen âge à l'ère industrielle. Les nominés pour le meilleur Environnement de Développement Intégré open source sont ...

Dans la méthodologie de gestion de projet UP (Unified Process) et les xUP (RUP Rational Unified Process, 2TUP 2 Tracks Unified Process, EUP Enterprise UP ...), l'environnement (tous les outils pour mener à bien le projet) est une discipline à part entière parmi les 9 de la composante statique de la méthode. L'IDE (Integrated Development Environment) est le cœur de toute la partie technique voir de l'ensemble du projet si on y ajoute des plugins. Alors comment choisir ?
Quel serait l'IDE idéal ? Quel est l'outil qui s'en rapproche le plus ?
Rappelons d'abord les fondamentaux.
L'éditeur doit avoir toutes les fonctionnalités modernes d'aide à la production de sources, citons en quelques unes parmi les plus utiles :
- outils de migration permettant par exemple de passer d'anciennes versions de Java vers la dernière Java 8,
- support des nouvelles versions des langages comme par exemple Java 8 avec les constructions lambdas, fonctionnels et les références de méthodes,
- la coloration syntaxique,
- la complétion automatique du code,
- les aides, la documentation,
- les templates de code,
- la détection au fil de l'eau d'erreurs de syntaxe,
- les avertissements concernant des variables non initialisées,
- les fuites de mémoire,
- la couverture de code,
- la génération de code,
- l'inclusion de bibliothèques de patterns de conception (GoF Gang or Four, ...),
- la personnalisation des raccourcis clavier,
- fusion, différences de code.
- couverture de code,
- un Profiler pour analyser et comprendre pourquoi telles ou telles parties de code prennent beaucoup de temps d'exécution
Une attention toute particulière pour la navigation dans le code. On doit pouvoir connaître tous les appelants et les appelés d'une méthode. À quel endroit est instanciée une classe.
Le refactoring c'est à dire par exemple le renommage de la classe, des méthodes, attributs, package, ... , doit être facilement accessible. Les erreurs de compilation doivent être détaillées et l'IDE doit proposé des solutions de corrections.
Le débogueur doit permettre la mise au point conditionnelle c'est à dire d'exécuter telle ou telle partie de codes si des conditions sont vérifiées. On doit pouvoir suivre l'exécution pas à pas dans les applications JEE à travers les serveurs d'application comme jBoss, Glassfish, Tomcat, …
Tous les langages et techniques utilisés dans votre application doivent être inclus,, par exemple pour une application JEE :
- Java, JEE
- XML, XSD, DTD
- web services : SOAP, WSDL
De nombreux assistants graphiques et conviviaux permettent de concevoir et mettre au point des documents XML, XSD, des web services. Ces outils s'interfacent avec les standards du marché comme les frameworks CXF, AXIS, JWS, ...
Dans mon IDE idéal, l'architecture SOA est pleinement intégrée avec des concepteurs grahiques de modélisation de processus métier à la norme BPMN 2. Des moteurs de règles open source comme DROOLS, Activity, … peuvent compléter la panoplie BPM/BRMS. Des ESB open sources sont intégrés en standard.
Bien sur tous les framework open source de tests unitaires (xUnit) et d'intégration doivent être présent en standard.
L'IDE idéal supporte tous les SGBD standards du marché (Oracle, MS SQL Server, DB2, MySQL, PostGRES, …) avec des éditeurs de conception et de requêtages.
Le déploiement et débogage avec tous les serveurs d'application du marché : jBoss, Tomcat, Glassfish, Oracle Server, IBM WebSphere, … doivent faire partie de la base commune de l'IDE.
Des aides à la configuration des frameworks d'architecture standard ( JEE 7, Spring, Hibernate, OSGI , EJB, JPA, CDI (Contexts and Dependency Injection) ) … permettent au développeur d'éviter les tâches répétitives. Les gestionnaires de projet Java comme Maven sont supportés.
La conception d'écrans de type client lourd (Swing, …) ou léger (HTML5, CSS, JavaScript, Ajax, Applets, Servlets, JSP, JSF, GWT, …) peut être réalisée par des concepteurs graphiques WYSIWYG. Ils doivent être bidirectionnels c'est-à-dire que toute modification manuelle de code doit se retrouver visuellement dans l'outil.
L'intégration et interface utilisateur commune à tous les systèmes de gestion de version (Git, Subversion ,CVS, ClearCase, Mercurial, …) est obligatoire.
Et n'oublions pas les outils de modélisation UML 2 qui doivent faire partie du lot, tout comme les générateurs de codes (MDA, QVT, OCL, …), d'écrans et de rapport (BIRT)..
De plus en plus d'applications d'entreprise s'accompagnent pour la partie frontal avec des clients d'applications mobiles (iOS, Android, WinPhone, …), le développeur doit avoir accès à un environnement complet pour les périphériques mobiles
L'IDE idéal disposent d'une très large bibliothèque de plugins complémentaires couvrant tout le spectre d'un projet depuis les processus métier, les règles métier, les exigences, la gestion de proget, les rapports de bogues (Issuezilla ou Bugzilla).
Une communauté importante d'utilisateurs participent aux développement de nouveaux plugins. Les logiciels commerciaux standards ont des versions s'intégrant complètement dans l'IDE (AGL, Enterprise Architect, …). Ils supportent de nombreux langages (C++, C#, .NET, scala, PHP, …).
Les nominés pour le meilleur IDE open source sont ...
- IntelliJ IDEA 13.1
- Eclipse Luna
- NetBeans IDE 8.0
Le premier prix est décerné à NetBeans IDE 8.0 pour sa convivialité, ses concepteurs graphiques et ses nombreux tutoriaux intégrés. Le deuxième prix revient à Eclipse Luna pour ses innombrables plugins. De toutes les manières il faudra imposer dans vos projets un IDE configuré avec toute une série de plugins dument éprouvés. Ce serait une très mauvaise idée de laisser les développeurs choisir ce qu'ils veulent à moins d'assumer les plantages du à des plugins obsolètes ou bogués.
Voir aussi le site :
7/11 Projet informatique, passer du moyen âge à l'ère industrielle. N'ayez plus peur du "grand méchant générateur de code"
Où en est-on sur la génération de code ? L'OMG (Object Management Group) a depuis plus de 10 ans spécifié des normes sur la transformation de modèles permettant en théorie de générer un modèle de code (PSM Plateform Specific Model) à partir d'un modèle décrivant des processus et des objets métier (PIM Plateform Independant Model).
Seulement voilà, comme à son habitude, l'OMG laisse le soin à d'autres de réaliser les outils conforment à ses spécifications . Plus facile à dire qu'à faire ! Quelques organisations open source ou commerciales s'y sont essayées en respectant plus ou moins les normes et de tout de manière sans succès, personne ne voulant investir sans avoir une garantie sur le retour sur investissement. Les solutions propriétaires existent depuis encore plus longtemps souvent intégrées dans leur AGL (Atelier de Génie Logiciel) sans plus de succès.
Alors faut il intégrer de la génération de code dans les projets ? Et si oui, à quelle dose ?
En 2004 j'avais participé à l'élaboration de l'urbanisation du SI d'un organisme de santé. L'organisation était très "IBMisée" et avait misé sur les outils Rational (racheté par IBM). La stratégie reposait en partie sur la génération de code à partir de modèles UML. Les problèmes sont arrivés lorsque l'équipe d'une dizaine de développeurs ont voulu modifier le code Java généré. RSA (Rational Software Architecture) était censé gérer le round trip, c'est à dire la mise à jour du code en cas de modification des modèles et réciproquement. Malheureusement lorsque plusieurs développeurs faisaient des changements sur les mêmes parties de code, les modèles étaient modifiés que partiellement. Suite à notre plainte, IBM nous a répondu que le bug était répertorié et qu'un patch nous serait livré dans 6 mois! Les raisons de ne pas utiliser les générateurs viennent essentiellement de la faible fiabilité, de la complexité de la mise œuvre, des contraintes imposées, de l'impossibilité de modifier ou de comprendre le code généré ou bien encore que le développeur passe plus de temps à paramétrer l'outil qu'à se concentrer sur la partie métier. Se lancer dans un générateur de code serait bien la dernière chose à faire. Cela paraît peut être trivial mais certains développeurs se laisseraient bien emporter par leur passion dans un tourbillon infini.
Alors faut il définitivement ranger la génération de code aux oubliettes ? Évidement que non car la bonne question à se poser relève une fois encore de la méthodologie c'est à dire : que dois-je générer et par quels moyens ? Les parties de code répétitives, représentent les patterns de conception, l'implémentation des différentes couches d'architecture, les squelettes du modèle métier, les règles métier et tout ce qui relève de la présentation (écrans, rapports, ...).
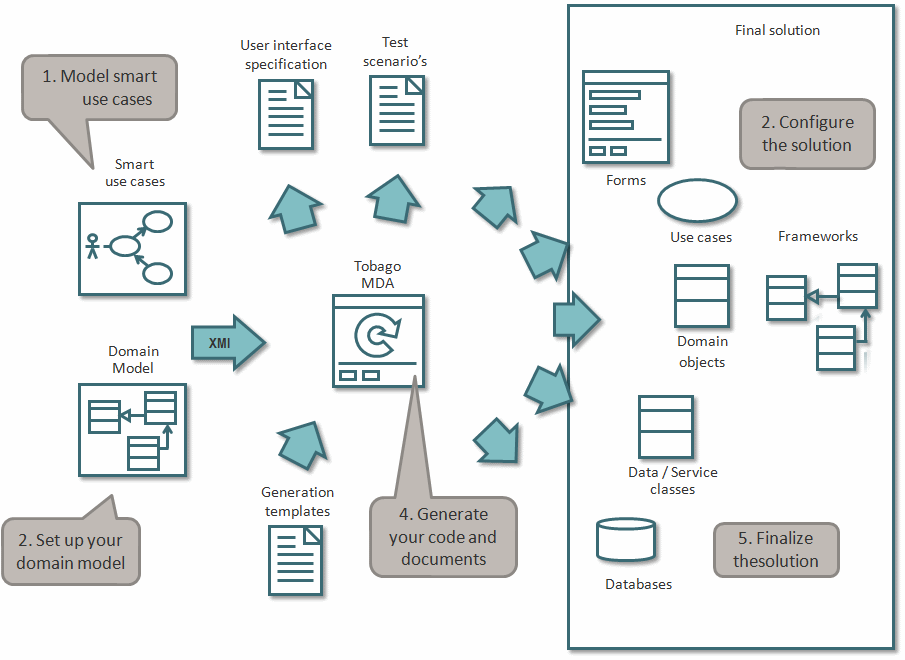
Parmi les dernières tendances de méthode agile comme Accelerated Delivery Platform de Cap Gémini, la génération de codes repose sur des templates et des stéréotypes de Use Case. Dans une application de gestion, on fait toujours la même chose : des recherches, créations, modifications, suppressions, ... d'entités métier. On peut identifier des types de use case comme : <<search>>, <<create>>, ... L'étape suivante est la traditionnelle modélisation du domaine métier avec un diagramme de classe UML. On associe par exemple le use case "rechercher un contrat" de stéréotype <<search>> à la classe "Contrat". Un générateur MDA (Model Driven Architecture) open source comme Tobago MDA permet l'importation du modèle. Le template ( modèle de code) se conçoit à partir d'un bloc de code répétitif dans lequel on remplace les entités à variabiliser par des tags. Le template est positionné dans des structures de boucles ou conditionnelles du générateur et les valeurs à remplacer dans les tags seront récupérées du diagramme de classe UML. Le squelette de code peut être emprunté à la couche présentation ou à toute autre de l'architecture applicative et technique.
Cette manière efficiente de générer du code est entièrement intégrée à la méthode agile ADP et utilise les bonnes pratiques et c'est assez rare pour qu'on le cite les norme UML et MDA. Cela démontre bien que les normes peuvent être utilisées et contribuer au retour sur investissement à condition de viser le pragmatisme et d'oser le changement dans la méthodologie de gestion de projet car rien ne vaut le changement pour dynamiser et motiver une équipe.
Voir aussi le site : "Abandonnez le classicisme, relookez votre SI"
6/11 Projet informatique, passer du moyen âge à l'ère industrielle. Travaillez votre agilité.
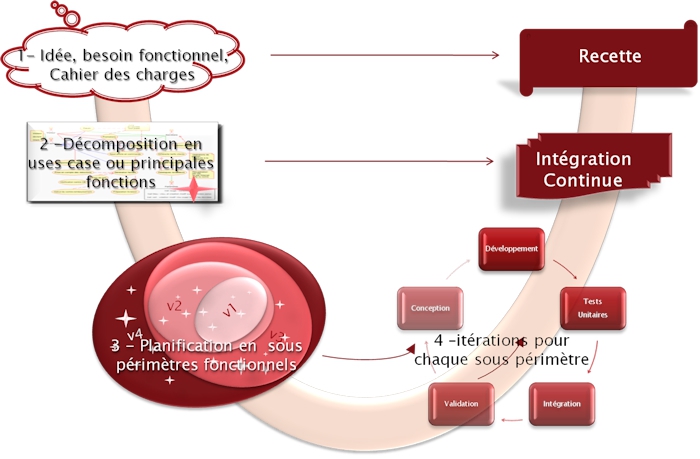
Les méthodes agiles (Scrum, Kanban, XP, … ) ne sont pas incompatibles avec les processus d'ingénierie comme CMMI, ISO, … qui spécifient le "quoi faire" et non le "comment faire" qui relève justement de leur périmètre. La meilleure méthode sera celle que vous vous serez approprié en mixant et adaptant l'ensemble des méthodes traditionnelles ou agiles à votre propre contexte.
Les utilisateurs de futures applications ne savent pas ce qu'ils veulent. Mettez de côté les "mais vous m'aviez dit que le gestionnaire pouvait modifier le statut de la commande" ou bien encore "pour le calcul des indemnités on devait se baser sur les salaires des 6 derniers mois et non sur les tranches de sécurité sociale". Seulement voilà, au fur et à mesure où le développement avance et où on commence à montrer les premiers écrans opérationnels, les utilisateurs vous disent que finalement ça a changé. Avec toutes les bonnes raisons du monde du reste, ils vous diront qu'ils n'avaient pas compris ce que vous attendiez d'eux, que le concurrent a ajouté des nouveaux services clients a très fortes valeurs ajoutées ou bien encore que la nouvelle loi à plus d'impacts que prévus. Cela arrive d'autant plus que les équipes peuvent rester isoler dans leur bunker sans avoir aucune relation avec le reste du monde.
Et voilà pourquoi plus de 80% des projets explosent les budgets quand ils ne sont pas gelés ou jetés à la poubelle.
Avec les méthodes agiles on laisse de côté toutes nos vieilles habitudes.
Le facteur humain avec les aspects communication est mis en valeur par rapport aux lourdeurs des formalismes des méthodes d'ingénierie et de leurs outils. La prise de conscience que ce qui compte vraiment ce n'est pas la documentation et les spécifications mais l'exécutable réalisé. Mettre en œuvre une collaboration efficace avez le client permet la reformulation qui est le moyen le plus efficace que l'on connaisse pour savoir si on a bien compris ce qui a été formulé. Oubliez définitivement de vouloir refuser les changements sous prétexte que ce n'est pas ce qui avait été spécifié. Les bonnes pratiques sont :
• l'adoption d'un cycle itératif et incrémental
• l'implication du client permettant, toutes les 2 à 4 semaines (durée recommandée pour une itération qui doit être courte) de montrer l'avancement des réalisations. Le fameux "effet tunnel" est ainsi évité.
• définition d'objectifs atteignables à court terme permettant de maintenir une pression constante mais supportable évitant l'effet "gaz" (quelque soit le temps donné à un développeur, il aura tendance à prendre la totalité pour réaliser sa tache).
• l'intégration des équipes diminuant les tensions et contentieux qui peuvent naitre entre la MOA et les prestataires MOE
• la livraison d'une application opérationnelle et en adéquation avec les besoins exprimés grâce aux méthodes TDD (Test Driven Developpement) et TDR (Test Driven Requirement) qui mettent l'accent sur les tests et aux feedbacks réguliers avec le client.
L'acceptation et l'appropriation de ces nouvelles bonnes habitudes ne se feront que s'il y a une réelle implication et volonté de changement de la direction générale et pour cela il faudra prouver mathématiquement le retour sur investissement.
Voir aussi le site :
5/11 Projet informatique, passer du moyen âge à l'ère industrielle. Mettez le paquet sur les Use Case.

Les cas d'utilisation (Use Case dans le langage unifié de modélisation UML) représente la technique la plus efficiente pour concevoir des spécifications fonctionnelles (SFG , SFD ou bien encore STD).
Malheureusement de nombreuses sociétés se basent sur la réalisation de maquettes écrans pour décrire ce que sera le futur système. Les directeurs de projet font ce choix soit par méconnaissance des méthodes de projet informatique , soit par peur de ce qu'il ne maîtrisent pas et préfèrent la solution de facilité. C'est une grave erreur, car en pensant faire simple et faire des économies sur les méthodes, la modélisation, les outils et des concepts trop abstraits, ces décideurs mettent en péril les projets. Investir sur la méthode et la modélisation des Use Case permet d'avoir de solides fondations pour les phases à venir du projet. Tout part des Use Case, les ignorer ou les bâcler conduira au désordre et à la désorganisation pendant toute la durée du projet entraînant rapidement une démotivation de l'équipe et au naufrage du projet.
Investissez sans hésiter dans les méthodes , les outils et la formation et vous obtiendrez rapidement un retour sur investissement en terme de formalisation des spécifications, de la rédaction des cas de tests quasi immédiate à partir des cas d'utilisation, de l'amélioration de la communication avec le développement et donc baisse des anomalies, de réutilisation des services métier et fonctionnels, d'évolutivité et de maintenabilité accrues.
Le concept de Use Case a été créé pour renforcer la communication entre MOA et MOE. Son objectif est de formaliser des besoins métier en actions exécutées par les utilisateurs du futur système. La modélisation des processus métier (BPMN Business Process Modeling Notation) facilite grandement l'identification des Use Case. En effet, si on est descendu à une granularité assez fine et que l'on a bien spécifié les activités entièrement manuelles que l'on désirent automatisées dans le futur système, il suffit de les reprendre dans la modélisation des exigences sous forme de cas d'utilisation UML.
Un bon Use Case ne doit pas être ni trop gros ni trop petit. Par exemple, supposons que l'on décide d'informatiser les prêts bancaire. On peut identifier dans l'architecture des processus l'activité "Gérer un prêt". La technique largement éprouvée pour savoir si est en présence d'un bon Use Case est de se demander s'il y a un unique acteur principal, s'il a bien un début et une fin, une durée limitée équivalent à une transaction métier de quelques heures (mais ne peut pas s'étendre sur plusieurs jours) et s'il répond à la règle des dix-dix. Cette règle stipule qu'un Use Case est constitué d'environ 10 scénarios eux même constitués d'environ 10 étapes.
Dans notre exemple, on identifie plusieurs acteurs : le chargé de clientèle qui crée une demande de prêt, l'analyste qui étudie la demande et enfin le responsable des prêts qui valide la demande. Ces 3 acteurs vont bien déclencher les 3 Use Case : "Créer une demande de prêt", "Etudier une demande de prêt" et "Valider une demande de prêt". Chacun est constitué d'un dizaine de scénarios (nominal, alternatifs, cas d'erreurs fonctionnelles) chacun composé d'une dizaine d'étapes élémentaires (comme imprimer la demande pour signature du client).
Cette description peut être modéliser en UML à l'aide des diagramme de Use Case pour les acteurs et les dépendances, les diagrammes de séquence pour les scénarios et l'enchaînement des étapes, les diagramme de classe pour les entités métier manipulées.
Si en amont on a modélisé les exigences et les règles métier (avec des diagrammes de classe et d'activité UML), on peut mettre en œuvre la traçabilité entre les exigences/règles et les use case. Ce qui permet de vérifier que toutes les exigences/règles sont bien implémentées et permet de mettre en œuvre une automatisation de la gestion du changement avec étude d'impacts.
Les estimations sont calculées à partir de la méthode des points de Use Case qui donne aujourd'hui les résultats les plus proche de la réalité.
La conduite du projet est basée sur les Use Case qui donnent la priorité et le périmètre des itérations.
L'utilisation d'outils comme un AGL (Atelier de Génie Logiciel) est indispensable pour mettre en œuvre ces techniques : modélisation des processus, gestion des exigences/règles, modélisation des Use Case, traçabilité, estimation avec les points de Use Case, conduite de projet informatique, …
Attention à ne pas négliger la formation à la méthode et aux outils ainsi que de s'attacher au début les services d'un expert. Beaucoup de pédagogie et de communication permettront l'adhésion et la motivation de toute l'équipe, clé du succès du projet.
Voir aussi le site :