
Le Machine Learning est il aux moteurs de règles métiers (BRMS) ce qu’une chute d’une météorite géante fut pour l’extinction des dinosaures ?
Faut-il continuer à modéliser les règles métiers avec DMN (Decision Model Notation), à les implémenter dans des moteurs de règles métiers (BRMS) si les algorithmes de Machine Learning permettent à des ordinateurs de reproduire des processus cognitifs par mimétisme ?
A « urbanisation-si.com », nous avons un « dada » : les règles métiers et les moteurs d’exécution BRMS (Business Rules Management system).
Mais nous sommes ouverts à tous les nouveaux concepts innovants et justement la stratégie de l’innovation et les écosystèmes nous paraissent incontournables et c’est pourquoi nous ouvrons une nouvelle catégorie « Innovation et Technologies de Rupture » dans laquelle on parlera de la stratégie d’innovation, de la transformation digitale, on traiera des sujets comme "pourquoi ou comment lancer des projets d’Intelligence Artificielle dans son entreprise" et on débute par ce premier article : le Machine Learning va-t-il signer l’arrêt de mort des moteurs de règles métiers BRMS ?
L’omniprésence de l’IA
De nos jours, deux approches technologiques se détachent pour bâtir des solutions d'Intelligence Artificielle.
D'une part les systèmes déterministes, à base de règles, et d'autre part des systèmes s'appuyant sur des algorithmes de Machine Learning.
L’intelligence Artificielle a eu sa période de vaches maigres jusqu’à fin des années 90s.
Et puis la période de vaches grasses arriva en mai 1997, quand a eu lieu le match historique en six parties entre Deep Blue et Kasparov.
Pour la première fois de l'histoire, le champion du monde doit s'incliner contre l'ordinateur, sur le score de 2½ à 3½.
Aujourd’hui les voitures sans chauffeur sont en phase finale de tests et sur le point d’être commercialisées.
Et tout récemment, le coup de maître dans l’univers de l’intelligence artificielle.
Pour la première fois, un ordinateur a battu un joueur de go professionnel.
Il s’agit de Google DeepMind avec leur algorithme, AlphaGo, qui a battu l’actuel champion européen, Fan Hui, par cinq victoires à zéro en octobre 2015 à Londres.
A présent tous les géants de l’IT comme les GAFAM (Google, Amazon, Facebook, Apple et Microsoft) , mais aussi les ancêtres comme IBM, … se livrent une guerre impitoyable à coup d’annonces sensationnelles.
Systèmes déterministes à bases de règles vs Machine Learning
Contrairement aux moteurs de règles qui se contentent d'appliquer des formules et des algorithmes construits par le concepteur de la solution, les algorithmes de Machine Learning permettent à des ordinateurs de reproduire des processus cognitifs par mimétisme.
Ainsi, pour apprendre à reconnaître un chat, vous ne construisez pas des règles telles que c'est un animal à quatre pattes, de petite taille, avec des poils, une queue et qui retombe toujours sur ses pattes.
Au contraire, vous vous contentez de montrer à la machine des images de chat.
Charge à l'ordinateur de comprendre les caractéristiques similaires entre les photos qui lui permettront de reconnaître tous les autres chats du monde.
Le monde des algorithmes de Machine Learning est très vaste et chaque algorithme doit être choisi en fonction de la tâche à accomplir.
Dans cette jungle, des algorithmes de plus ou moins grande complexité se côtoient.
C'est ainsi que depuis quelques années, beaucoup de recherches ont été menées sur des algorithmes impliquant des réseaux de neurones formels.
Ces algorithmes s'inspirent du fonctionnement des neurones et des synapses du cerveau humain.
Ils en reproduisent des mécanismes grâce à des couches de neurones successives.
Les réseaux de neurones formels, les plus simples, se contentent de présenter uniquement deux couches de neurones ; une couche d'entrée, une couche de sortie ; chaque couche pouvant disposer de plusieurs neurones (centaines, milliers, voire millions).
Les valeurs des neurones de sorties dépendent des valeurs des neurones d'entrées ainsi que d'un apprentissage du réseau qui qualifie les relations entre les neurones.
Le Deep Learning, d'un point de vue purement technique et algorithmique, consiste à disposer d'un réseau de neurones disposant d'une ou plusieurs couche(s) cachée(s) (entre la couche d'entrée et la couche de sortie).
Un avantage substantiel de ces modèles d'algorithme est d'offrir un mécanisme permettant de s'affranchir de la forte linéarité du modèle des réseaux neuronaux.
Cela permet d'adresser des problématiques plus complexes, plus proches des situations réelles de notre environnement humain.
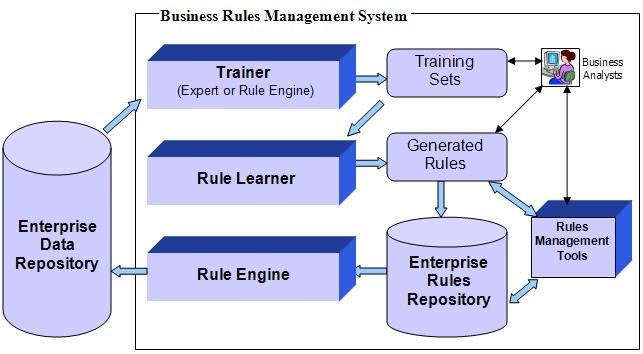
La solution : intégrer une brique Machine Learning dans les BRMS
L'une des techniques les plus populaires de Machine Learning est l'extraction de règles et de modèles de classification à partir d'ensembles de données massives.
Dans le même temps, la découverte de règles est un élément clé de tout système de gestion des règles d'entreprise.
Cela suggère une question naturelle : pourquoi ne pas combiner ces deux technologies (Machine Learning et BRMS) ?
On ajoute une brique de « Rule Machine Learning » (RML) qui devient un composant des BRMS pour exécuter un algorithme d'apprentissage automatique par rapport aux données historiques provenant d'une base de données d'entreprise et génère de nouvelles règles de décision sous une forme compréhensible par les experts métiers et le système de règles métier.
Les règles générées peuvent être automatiquement ajoutées au référentiel de règles d'entreprise et être utilisées pendant un cycle d'exécution du moteur de règles pour générer de nouvelles décisions d'entreprise qui seront à leur tour enregistrées dans le référentiel de données d'entreprise.
En travaillant ensemble et en appliquant plusieurs itérations du processus RML / moteur de règles, on ajoute une nouvelle dimension, celle des capacités d'apprentissage auto-améliorées, aux processus métier basés sur des règles.
De cette façon, RML devient une partie intégrante d'un BRMS au niveau de l'entreprise.
Il convertit un service de décision basé sur des règles en un véritable "expert autonome", c'est-à-dire qui peut apprendre des expériences antérieures des experts métiers et peut également apprendre de ses propres expériences antérieures.
Cette approche de Machine Learning nécessite d’être supervisée avec des entrainements successifs pour son exécution.
Cet apprentissage du RML consiste généralement en des exemples indiquant quand le résultat souhaité a été atteint (exemples positifs) et des contre-exemples indiquant les cas où le résultat souhaité n'a pas été atteint (exemples négatifs).
Ces formations sont utilisées par le RML pour découvrir et représenter de nouvelles règles et pour mesurer l'exactitude et l'efficacité des règles une fois qu'elles ont été apprises.
Si les résultats sont satisfaisants, les règles peuvent alors être utilisées pour prédire les résultats pour de nouveaux cas non détectés auparavant.
L'apprentissage supervisé nécessite un formateur pour créer des ensembles d'entraînement.
Habituellement, un formateur est un expert métier qui possède une vaste expérience dans le traitement des données d'entreprise et possède les compétences et les qualités nécessaires pour établir des objectifs, des concepts et / ou des critères pour détecter les modèles et les règles.
Il est également possible d'automatiser l’apprentissage et d'en faire une partie intégrante de l'architecture du système.
Initialement, le formateur peut être implémenté comme une interface interactive basée sur des règles qui aide l'expert métier à analyser les données de l'entreprise et à créer des ensembles de formation.
Mais ce formateur peut également être implémenté comme un moteur de règles spéciales qui analyse automatiquement de gros volumes de données conformément aux « règles de formation » créées par une entreprise et utilise ces données pour générer de nouveaux ensembles d’apprentissage.
Cela est particulièrement important pour les applications basées sur des règles qui mettent fréquemment à jour les données d'entreprise et souhaitent que leur RML se tienne au courant des dernières modifications.
Conclusion
Il est évident que l’IA devient incontournable, elle se démocratise par la mise à disposition en open source des algorithmes.
Le Machine Learning ne va pas signer l’arrêt de mort des moteurs de règles métiers BRMS mais au contraire, il va devenir une brique de base des BRMS qui pourront s’auto alimenter en règles métiers après un apprentissage par un expert métier.
Les objectifs les plus fous sont en train de devenir des réalités à tel point que des scientifiques de renom, tel le célèbre physicien Stephen Hawking, voient en l’avènement de ces technologies un danger pour la race humaine ...
Rhona Maxwel
@rhona_helena
"On ne fera jamais une bonne publicité en mettant en avant des caractéristiques techniques, des Gigaoctets de RAM, des tableaux ou des comparatifs …
Il faut transmettre une émotion."
Steve Jobs
Articles conseillés :
Drools le moteur de règles métiers open source (BRMS) : le chaînage avant (forward chaining)
Drools le moteur de règles métiers open source (BRMS) : le chaînage arrière (backward chaining)
A quoi sert un moteur de règles ?
Les étapes d’un projet avec un moteur de règles
Quand faut il utiliser un moteur de règles ?
Qui fait fonctionner un moteur de règles ?
BRMS Moteur de règles : mais que fait IBM ?
Inscrivez-vous au site
Soyez prévenu par email des prochaines mises à jour
Rejoignez les 838 autres membres